1. Introduction to MongoDB
In this post, we feature a comprehensive MongoDB Tutorial that integrates with a Java-based application. Whenever we read about NoSQL databases, we need to know why were they ever developed when SQL databases were working excellent. NoSQL foundations grew upon relaxed ACID (atomicity, consistency, isolation, durability) guarantees in favour of performance, scalability, flexibility and reduced complexity. Most NoSQL databases have gone one way or another in providing as many of the previously mentioned qualities as possible, even offering tunable guarantees to the developer.
MongoDB is an open-source, document-oriented, and cross-platform database which is developed in C++ and is one of the most popular and used NoSQL type databases. It works on top of JSON-like documents with key-value pairs whose schema can remain undefined across every document. Also, it is free to use as it is published under a combination of the GNU Affero General Public License and the Apache License. MongoDB stores data in JSON-like documents (called BSON), which can have a dynamic schema across documents in the same collections. The structure of a document in the same collection can be changed by simply adding new fields or deleting existing ones.
In this post we will study some of the characteristics of this NoSQL Database and how it evolved across various versions, adding new features with improved scalability and performance. We will also develop a small Maven-based Java project in which we will run some of the sample queries with MongoDB driver for Java.
2. MongoDB evolution
MongoDB was developed by 10gen and it was first released on August 27th, 2009. The first version for MongoDB was released with some basic features, authorization, and ACID guarantees which made up for shortcomings with performance and flexibility. Again, some basic features for v1.0 and v1.2 were:
- JSON-based document model
- Global lock at process level
- Indexes on collections which resides on RAM (majorly)
- CRUD operations on documents in a collection
- Replication support in a Master Slave architecture
- Map-Reduce (supported in v1.2)
- Javascript functions (supported in v1.2)
Soon after the initial versions, next version of MongoDB brought many new features and exciting improvements on indexed collections and built upon previous feature set as well. To list down the evolution, here are some features which were present in Version 2 of MongoDB release:
- Sharding (supported in v1.6)
- Query operators (supported in v1.6)
- Sparse and covered indexes (supported in v1.8)
- Much more efficient memory usage
- Concurrency improvements
- MapReduce improvements
- Authentication (supported in v2.0 for Sharding)
- Geospatial query and data support
Now, with the advent of much more data in the databases of most of the organisations, there was a need of much more performance increase, faster indexes and searchable documents. All of these demands were correctly answered in the Version 3 of MongoDB. Here are the features which were a major boost which made MongoDB one of the most used NoSQL Database:
- Aggregation Framework (supported in v2.2)
- Text search (supported in v2.4)
- Hashed indexes (supported in v2.4)
- Security enhancements, role-based access to databases (supported in v2.4)
- V8 JavaScript engine (replacing SpiderMonkey, since v2.4)
- Query engine improvements (since v2.6)
- Document validation (since v3.2)
- Multiple storage engines (since v3.2, Enterprise edition only)
When we start to notice the features MongoDB has been adding since it started to evolve, we can easily see that at its current state, MongoDB is a database that can handle loads of data ranging from startup MVPs and POCs to enterprise applications with hundreds of servers and more.
3. MongoDB Terminologies for SQL Developers
We can understand MongoDB concepts much faster if we establish a comparison between SQL terminologies and NoSQL concepts. Here is a simple analogy comparison between Mongo and a traditional MySQL system:
- Tables in MySQL becomes Collections in MongoDB
- A row beomes a document
- Column becomes a field
- Joins are defined as linking and embedded documents (more on this later)
To clear any misconceptions, this was just a simple way to look at MongoDB concepts and each of them might not be strictly applied on their MongoDB counterparts but it was nevertheless important.
4. Making the Java Project with Maven
We will be using one of the many Maven archetypes to create a sample project for our example. To create the project execute the following command in a directory that you will use as workspace:
Creating a Project
mvn archetype:generate -DgroupId=com.javacodegeeks.example -DartifactId=JCG-JavaMongoDB-Example -DarchetypeArtifactId=maven-archetype-quickstart -DinteractiveMode=false
If you are running maven for the first time, it will take a few seconds to accomplish the generate command because maven has to download all the required plugins and artifacts in order to make the generation task. Once we run this project, we will see the following output and the project will be created:
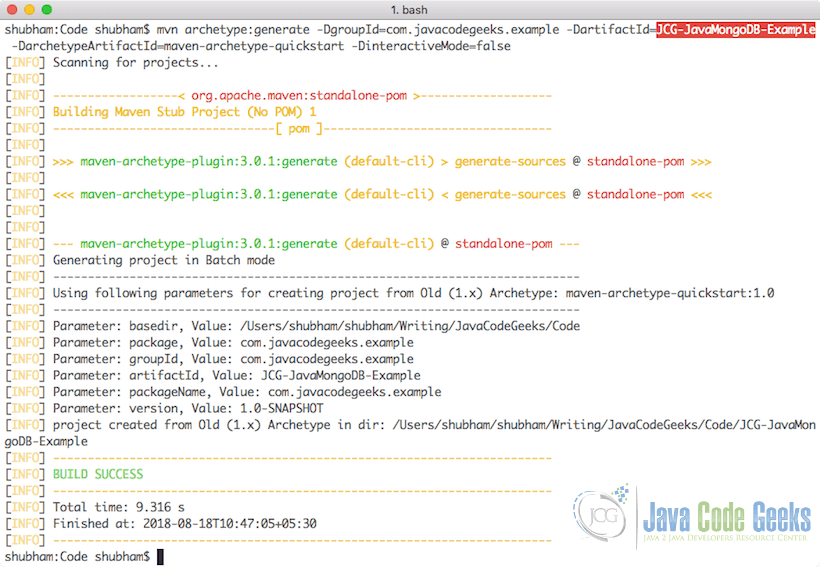
5. Adding Maven dependencies
Once you have created the project, feel free to open it in your favourite IDE. Next step is to add appropriate Maven Dependencies to the project. We will work with the following dependencies in our project:
mongo-java-driver: This dependency brings the MongoDB driver for Java into our dependencies.
Here is the pom.xml file with the appropriate dependencies added:
pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.javacodegeeks.example</groupId>
<artifactId>JCG-JavaMongoDB-Example</artifactId>
<packaging>jar</packaging>
<version>1.0-SNAPSHOT</version>
<name>JCG-JavaMongoDB-Example</name>
<url>http://maven.apache.org</url>
<dependencies>
<dependency>
<groupId>org.mongodb</groupId>
<artifactId>mongo-java-driver</artifactId>
<version>3.4.1</version>
</dependency>
</dependencies>
</project>
If you want to check and use a newer version for the driver, check the releases here.
Finally, to understand all the JARs which are added to the project when we added this dependency, we can run a simple Maven command which allows us to see a complete Dependency Tree for a project when we add some dependencies to it. This dependency tree will also show how many dependencies were added when we added some of our own dependencies in a well-placed hierarchial manner. Here is a command which we can use for the same:
Check Dependency Tree
mvn dependency:tree
When we run this command, it will show us the following Dependency Tree:

Clearly, this is a quite simple project as it has just one Maven dependency added into it.
6. Project Structure
Before we move on and start working on the code for the project, let’s present here the project structure we will have once we’re finished adding all the code to the project so that we know where to places classes we will make in this project:

We have used a single class in this application as it fulfilled all of our purposes. We can break this class into multiple classes based on operations we need to do and when our project expands to more complex operations.
7. Using MongoDB with Java
Now, we can start using MongoDB queries in the Java project we just made. We will start with basic CRUD operations followed by pagination implementation and much more queries. Before proceeding to the code examples, please make sure to install and run MongoDB on your machine.
7.1 Making a connection with MongoDB
The first step to work with a database in any application is to connect to it. We can connect to MongoDB by authenticating against the authentication-database (admin by default) in following manner:
MongoApp.java
System.out.println("Connecting to DB...");
List<MongoCredential> credentialsList = new ArrayList<>();
//Use username, authtication database and password in MongoCredential object
MongoCredential creds = MongoCredential.createCredential("db_user", "admin", "db_password".toCharArray());
credentialsList.add(creds);
ServerAddress serverAddress = new ServerAddress("localhost", 27017); //host and port
MongoClient mongoClient = new MongoClient(serverAddress, credentialsList);
System.out.println("Connected to MongoDB...");
The above code can be used when we are connecting to an authenticated database which is secured and has authentication enabled. If you haven’t secured your MongoDB installation yet, you can simply use:
MongoApp.java
MongoClient mongoClient = new MongoClient("localhost", 27017);
We are now ready to run various commands with this MongoClient object which has established and stored a DB connection in it.
7.2 Show Existing Databases
We will start by displaying all databases which exist in our system which current user can access (if the installation is secured with authentication). To do this in Mongo shell, we can run the following simple command:
Show Databases with Mongo shell
show databases;
The same operation can be performed with following Java code snippet as well:
Show Databases with Java
// print existing databases mongoClient.getDatabaseNames().forEach(System.out::println);
This will show the existing databases in the system:
Output
admin local
In above output, local is the default Mongo database.
7.3 Create a Collection
We can create a collection in our database by following Java code snippet:
MongoApp.java
// get database
MongoDatabase jcgDatabase = mongoClient.getDatabase("JavaCodeGeeks");
// create collection
jcgDatabase.createCollection("authors");
jcgDatabase.createCollection("posts");
This is to be noticed that we never created the mentioned database. Still, MongoDB will not throw any error. It is optimistic and it understands that if a DB doesn’t exist, it will create one for you. If you run the show databases command again, we will see a different output this time:
Databases
JavaCodeGeeks admin local
The database was automatically created.
7.4 Save – Insert into a collection
In MongoDB, insertion works a little differently than other databases. While inserting, if an id is present in the database, it updates the same document, otherwise, it performs an insert operation. If we try to save a new author which doesn’t exist in the database, insertion will happen:
Insertion
MongoCollection<Document> authorCollection = jcgDatabase.getCollection("authors");
Document document = new Document();
document.put("name", "Shubham");
document.put("company", "JCG");
document.put("post_count", 20);
authorCollection.insertOne(document);
System.out.println("Inserted document = " + document);
When we run this code snippet, we will see that an _id is automatically assigned to this object which we can later to update the same document in our code:
Output
Inserted document = Document{{name=Shubham, company=JCG, post_count=20, _id=5b77c15cf0406c64b6c9dae4}}
7.5 Save – Update an existing document
Now that we have inserted a document in an existing collection in a database in our MongoDB, we can update it as we know its ID as well. We will perform an update operation with the following code snippet and update the author’s name:
Updating Document
//Find existing document
Document updateQuery = new Document();
updateQuery.put("name", "Shubham");
//Field to update
Document newNameDocument = new Document();
newNameDocument.put("name", "Shubham Aggarwal");
//Perform set operation
Document updateObject = new Document();
updateObject.put("$set", newNameDocument);
UpdateResult updateResult = authorCollection.updateOne(updateQuery, updateObject);
System.out.println("Documents updated: " + updateResult.getModifiedCount());
When we run this code snippet, we will see that at least one document was correctly modified in database:
Output
Documents updated: 1
As we noticed, in this provided code snippet, save followed the convention of update, because we used an object with given _id.
7.6 Getting all documents in a collection
It is easy to find all documents present in a collection for which we just need to provide a query object on which filtering is done before documents are fetched from collections. Let’s see how this can be done with Java code snippet:
Get all documents
Document searchQuery = new Document();
searchQuery.put("company", "JCG");
FindIterable<Document> documents = authorCollection.find(searchQuery);
for (Document document: documents) {
System.out.println(document);
}
We get following output once we run the above code:
Output
Document{{_id=5b77c15cf0406c64b6c9dae4, name=Shubham Aggarwal, company=JCG, post_count=20}}
There are many more operations which can be performed on a FindIterable object out of which, we will see some in coming sections.
7.7 Deleting a document
Deleting a document is easy. We just need to provide the filter query and work will be done.
pom.xml
Document deleteSearchQuery = new Document();
deleteSearchQuery.put("_id", new ObjectId("5b77c15cf0406c64b6c9dae4"));
DeleteResult deleteResult = authorCollection.deleteOne(deleteSearchQuery);
System.out.println("Documents updated: " + deleteResult.getDeletedCount());
We get following output once we run the above code:
Output
Documents updated: 1
Notice that we used the value of ID not as a String but as an ObjectId because that is what MongoDB understands. Although, it is completely possible to use a simple String as an ID as well, but other types are not supported for identification fields. Finally, notice that we used deleteOne method which deletes only a single document. Even if MongoDB finds more than one document for the provided filter (in case of ID, it cannot find more than one but possible in other cases), it would have still deleted just one document from them (the first matched document is deleted). To delete all the filtered documents, we can use deleteMany method.
8. The _id field Decoded
Every MongoDB document has an _id field which is an unique identifier for a given document in a collection. It looks something like:
_id
{
"_id" : ObjectId("5b77c15cf0406c64b6c9dae4")
... other fields ...
}
Many a times, people (definitely not developers) think that is a randomly generated token of String which is carefully chosen so that it remains unique across any number documents saved in this collection. But this is not the case. Each _id of all documents in MongoDB is a 12-byte hexadecimal number that ensures the uniqueness of the document in a collection. It is generated by MongoDB if not provided by the developer himself (in which case the meaning of that String will completely change but still remain the unique identifier in the collection).
Of the 12 bytes, the initial 4 bytes depicts the current timestamp, the following 3 bytes presents the machine identifier, the next 2 bytes describes the process ID for the MongoDB server on this machine, and the last 3 bytes are simple auto-increment counter maintained by MongoDB server. This can also be explained with a simple diagram:

This field also represents the primary key of each document in a MongoDB collection.
9. Limitations of MongoDB
Although MongoDB can scale a lot and has super-fast indexes, it also has some possible disadvantages. We used the term “possible” as this might or might not be a disadvantage for your use-case. Let’s see some of these disadvantages here:
- The maximum size which each document can occupy is 16MB.
- The maximum document-nesting level in a MongoDB document is 100
- The database name is limited to 64 characters
- If we apply an index on any field, that field value cannot contain more than 1024 bytes
- A hashed index cannot be unique
- You cannot rollback automatically if data is more than 300 MB. Manual intervention is needed in such cases
As we mentioned, these are some disadvantages which might never occur in your application and you won’t have to do anything for the same.
10. MongoDB vs RDBMS
The battle of MongoDB and RDBMS databases is never-ending. Developers always have a long debate over which one is faster or better than the other but the answer is, there is no comparison between the two because of use-cases under which each of these are used. To mention, let’s describe the advantages of MongoDB over RDBS databases here:
- Collections in the MongoDB database are schemaless. Documents inserted in collections can have different sets of fields without having to do anything extra at the application level or database level.
- MongoDB has rich query support. MongoDB supports dynamic queries on a database.
- Conversion or mapping between database objects and application objects is simple as most of the application supports JSON mapping with database objects.
- Integrated memory support allows the user to access data in a much faster way.
MongoDB is not magically faster. If you store the same data, organised in basically the same fashion, and access it exactly the same way, then you really shouldn’t expect your results to be wildly different. After all, MySQL and MongoDB are both GPL, so if Mongo had some magically better IO code in it, then the MySQL team could just incorporate it into their codebase.
People are seeing real-world MongoDB performance largely because MongoDB allows you to query in a different manner that is more sensitive to a workload. For example, consider a design that persisted a lot of information about a complicated entity in a normalised fashion. This could easily use dozens of tables in MySQL (or any relational database) to store the data in a normal form, with many indexes needed to ensure relational integrity between tables.
Now consider the same design with a document store. If all of those related tables are subordinate to the main table (and they often are), then you might be able to model the data such that the entire entity is stored in a single document. In MongoDB, we can store this as a single document, in a single collection. This is where MongoDB starts enabling superior performance.
11. Conclusion
In this lesson, we quickly got acquainted to using MongoDB in a simple maven-based Java application and performed CRUD operations on our collections with an updated API.
We also studied various advantages of MongoDB. Though there can be many use-cases in which you will want to use MongoDB over a SQL database, I think Schema flexibility is most probably the most important factor which affects this decision. MongoDB provides us with an ability to store data or documents in a collection which can have different fields which can help a lot during the development phase of an application but also in ingesting data from multiple sources that may or may not have the same properties and schema associated with them. In comparison with an RDBMS database where columns have to be predefined and having sparse data can be penalized, in MongoDB this is the norm and it’s a feature that most use cases share. Having the ability to deep nest attributes into documents, add arrays of values into attributes and all the while being able to search and index these fields helps application developers exploit the schema-less nature of MongoDB.
Finally, Scaling and sharding are the most common patterns for MongoDB use cases. Easily scaling using built-in sharding and using replica sets for data replication and offloading primary servers from read load can help developers store data effectively. Even apart from the advantages MongoDB offers, MongoDB still has some critics which mention that scale is not something we need in every application and so, nullifying the one of the most important factors which favours MongoDB.
12. Download the Source Code
This was a MongoDB Tutorial with Java programming language.
You can download the full source code of this example here: MongoDB Example
