Your logs tell a story – or at least they should be. It is safe to assume that all software applications have some type of logging.
With logging in this context I mean messages generated in response to events occurring in an application from its deployment until its undeployment. These messages are usually transported to a different system for consumption. Their purpose is to inform about what is happening in the application and are not part of the application’s functionality.
In many applications, logging is executed as an afterthought. Something we do but we do not think much about. Moreover, there are a lot of (valid) concerns regarding the dangers that can arise from excessive logging and the “clutter” they cause to the codebase. These will not be addressed in this article. I am interested in how to perform deliberate logging, because I believe that logging, when done properly, can bring our application to the next level. So, why do we log?
We log to communicate useful (and often actionable) information to an interested party. It can be to ourselves when trying to debug why the application does not behave as expected. Maybe we log users’ behavior in order to understand them better and help us build a better experience for them. Or we might log because it is mandatory due to regulations.
I will attempt a categorization and will group logs under:
- User behavior: data concerning the journey of users while using our application. We use them so we can improve their experience
- Debug: information which help us in times of trouble, when things in the application do not behave as expected
- Performance: metrics that help us understand how our application components perform under varying load and reveal areas we need to improve
- Regulatory compliance: some applications are required to retain certain logs for auditing, assist in non-repudiation controls, etc.
- Security: logs that help us establish baselines, recognize attacks in real time and respond
- Business: concern data state and processes taking place due to users’ activity and use of the application. This type of data are the most immediate to our application’s purpose
- System: I greatly generalize here, to include all logs related to things like operating system, databases, application lifecycle, its maintainers, etc. It provides information about the environment our application runs on
The categorization above aims to convey that not all logs are the same. The way we handle them should not be the same either. We could evaluate and characterize our logs based on the following properties:
- Criticality: How important is the message? It would not be a big deal to drop some logs related to user behavior but we cannot drop logs that are required for auditing
- Frequency & size: How often are messages generated? And of what size? Some events happen more often than others and the log payload can differ in size. We have to handle each in an appropriate way, for example to prevent bottlenecks
A picture is worth a thousand words so evaluating the log categories based on the above properties (I am not being precise here) could look something like this:
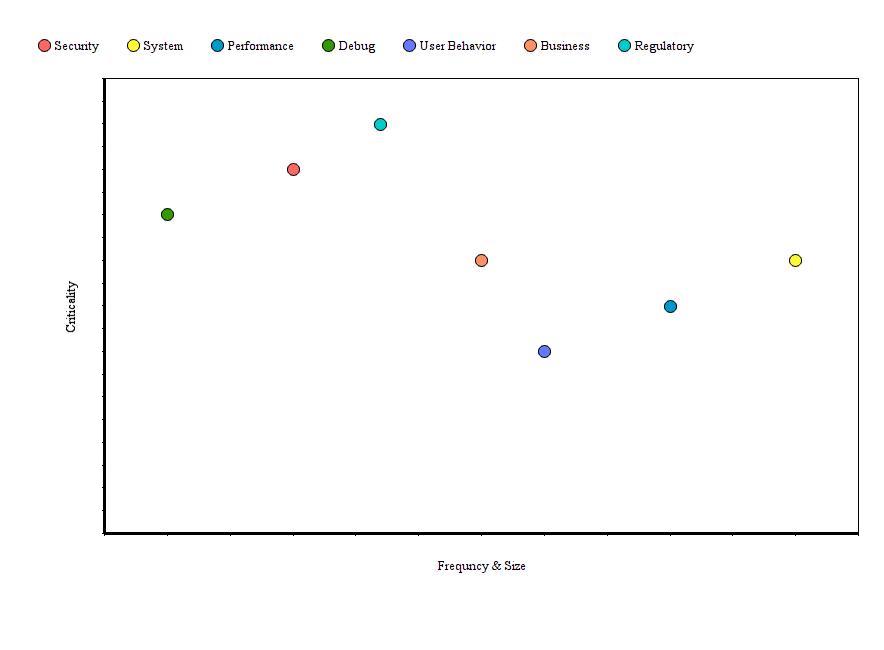
I argue that the differences in their nature could justify each log category to be handled differently during the logging lifecycle.
The logging lifecycle is pretty straight forward. Recorded logs are being transported, in order to be persisted, indexed, analyzed and possibly (automated) reactions will take place. The type of logs (criticality, frequency) will be factors in our design of the transport phase so that we allow logging to enhance our applications without hampering its main functionality. The way in which the logs are recorded will play role on the effectiveness and efficiency of analysis and reactions. So how we should write logs? And what should be in them to provide context and tell a story?
The how is simple. We want logs to be easy to understand by both humans and machines and we have a perfect format for that, JSON. All data should be entered as clear key-value pairs. Next, what should we log? As we mentioned we need to tell a story, give context and remove all the “fat” from it. In order to tell a story, every log should provide:
- Who: service reference id, application name and version
- Does what: log/event type (e.g., security) and subtype (e.g., unauthorized request)
- On behalf of whom: some form of user or system identification
- For what reason: specific business functionality (request) the system works on
- When and for how long: timestamp
- From where: source id
- On what: target id
- As response to what: parent process or request
This way, the event logged is described in context, with all the necessary information, in a format that can be easily analyzed by both humans and machines.
For the sake of completion I must mention what not to log. For this, I simply refer to OWASP as they can do a much better job at it than me [1]. So your logs must not contain:
- Application source code
- Session identification values (consider replacing with a hashed value if needed to track session specific events)
- Access tokens
- Sensitive personal data and some forms of personally identifiable information (PII) e.g. health, government identifiers, vulnerable people
- Authentication passwords
- Database connection strings
- Encryption keys and other master secrets
- Bank account or payment card holder data
- Data of a higher security classification than the logging system is allowed to store
- Commercially-sensitive information
- Information it is illegal to collect in the relevant jurisdictions
- Information a user has opted out of collection, or not consented to e.g. use of do not track, or where consent to collect has expired
And last thing on what not to log. Record only information that is of interest to someone. Remove the fat. For example, is anyone in your team interested in which thread the process took place? If yes, great – log it. If not, then it shouldn’t be logged.
It all sounds peachy but in practice there are challenges. I believe that in most applications logging is performed suboptimal. Even if there are clear guidelines, conventions and strategies in a company on how to log, I would expect they are not followed by everyone. Developers come and go. Logging is not “respected” much in general. So the reality is that each developer throws some logs here and there on their own language (i.e., idioms), to the log level they see fit. Crucial information about the event could be missing while unnecessary information could clutter the logs depending on the skills of each developer. All types of (heterogeneously phrased) logs are recorded and persisted somewhere. Later, great efforts take place to parse, index, analyze and make use of these logs. But we can and should do better.
An interesting idea and a relatively low cost investment would be to create a small framework on top of your preferred logging library which provides a “logging facade” for the developers. All these items discussed in the article regarding what you should (or shouldn’t) log, the format and the different handling for different categories of logs would be abstracted and handled by the framework. An intuitive and easy to use interface would be available for the developers. Deliberate logging practices would be applied and your applications and operations would be better off. How to do that? It would definitely make a good topic for another article.
References and inspiration:
[1] https://www.owasp.org/index.php/Logging_Cheat_Sheet
[2] https://www.codeproject.com/Articles/42354/The-Art-of-Logging
[3] https://www.symantec.com/connect/articles/building-secure-applications-consistent-logging
[4] http://jasonwilder.com/blog/2013/07/16/centralized-logging-architecture/
[5] https://www.loggly.com/blog/measuring-the-impact-of-logging-on-your-application/
[6] https://logmatic.io/blog/beyond-application-monitoring-discover-logging-best-practices/
[7] http://dev.splunk.com/view/logging/SP-CAAAFCK
| Published on Java Code Geeks with permission by Tasos Martidis, partner at our JCG program. See the original article here: The value of deliberate logging Opinions expressed by Java Code Geeks contributors are their own. |
