What can you learn from ordering a cup of coffee?
Try asking for a cappuccino made with much less espresso than normal… generally, you won’t get what you ask for, even if you ask for it in a variety of different ways. I’ve done this experiment: I love coffee, but I need to drink it very weak—mostly milk—and just a ½ shot of espresso. Yet when I order it that way, I’m given a regular strength cappuccino, except when I’m given an extra strength one.
To get this right, I have even tried asking for “a cup of foamy steamed milk and serve the shot of espresso on the side,” so I could tip in just half the shot myself. Instead, the server cheerfully brought me a cappuccino with two shots of espresso in the cup plus an extra shot on the side.
The trouble is, pre-conceptions can get in the way of hearing what is actually being said.
It’s not just a concern when ordering coffee. Something similar can happen as we investigate new and innovative big data technologies and techniques. I used the cappuccino example in a talk I presented recently at the Strata + Hadoop World Conference in London. The talk, titled “Building Better Cross Team Communication,” highlighted the importance of identifying and addressing the difference in how each side thinks the world works when two groups that have different experience and skills come together. Soliciting feedback on what your audience thinks you meant is one simple but effective technique to expose the barriers that pre-conceptions may place in way of useful communication.
But it turns out that these problems are not limited to communication between people of very different skill sets. When you think about it, it’s not surprising that having a lot of experience in a particular area could make it more likely that you will be led astray by pre-conceptions, especially when you encounter real innovation. Someone less knowledgeable about how things used to work is also less apt to misinterpret how something new actually does work. So people experienced in a particular field may be the ones who will miss key aspects of a new technology. Consider this big data example I’ve encountered several times over the last two months when discussing new technology for handling streaming data.
Here’s what happened: There’s a rapidly growing interest in getting value from streaming data, and with that, interest in emerging stream-based technologies. When people work with streaming data, they not only need a message processing tool (such as Apache Spark Streaming, Apache Flink, Apache Apex or Apache Storm), they also need a message transport technology—something to collect streaming data from continuous events and publish it to the applications that need it. Many people who work with streaming data at scale are familiar with one such message transport, known as Apache Kafka.
Here’s where the pre-conceptions may come in. Usually Kafka is run on a separate cluster from the data processing and data storage. So when people hear about a new messaging technology called MapR Streams, they may assume that it also must run on a separate cluster from the stream processing or data storage, as does Kafka. That’s not correct. In making this assumption, based on their experience with Kafka, they may miss out on recognizing one of MapR Streams’ key advantages: while MapR Streams supports the Kafka API, it is built directly into the MapR Converged Data Platform.
In other words, the MapR Streams messaging transport feature does not need a separate cluster.
This idea is shown in the following diagram:
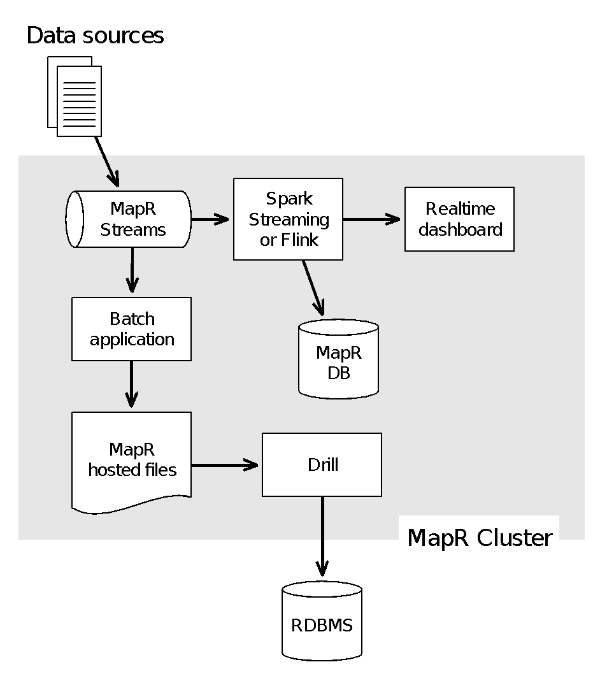
Message transport and stream processing on the same cluster: This diagram shows that because MapR Streams is part of the MapR Converged Data Platform, streaming transport for the message queue runs on the same cluster as the stream processing (Apache Spark Streaming, Apache Flink, Apache Storm, etc.). The MapR Converged Data Platform also has an integrated NoSQL database (MapR-DB) and distributed filesystem (MapR-FS). A whole range of open source tools from the big data ecosystem (such as Apache Drill’s big data SQL engine) also can run on the same cluster.
The idea of not needing a separate cluster is so surprising to those used to Kafka that they may just wrongly assume that it is required for MapR Streams message transport as well, even when they hear the words “integrated into the MapR Converged Data Platform.” Note that there are many useful implications of this convergence:
- Single management and security
- Less hardware required, generally
- Simplicity of design, with file storage, tables, and streaming all part of the same platform
- Very long-term storage of messages is possible since replica of each topic partition in MapR Streams does not have to fit on one machine, but instead can be distributed across the cluster
- Very high performance because MapR Streams is based on the same technology that makes the MapR File System fast
Transition to Big Data Paradigm
The challenge is, how do you transform your thinking so that you take full advantage of new technologies and techniques? This is a broad issue for people transitioning to big data—it’s not unique to MapR Streams. As people begin to work with large-scale data, they need to do more than just plug in the technology and learn which knobs to turn. To get the most value from data, practitioners also need to transform how they think about data and how they design solutions.
Flexibility is one new advantage that may be overlooked because of traditional assumptions. Here are several ways in which flexibility comes into play. Modern large-scale distributed systems make it reasonable in terms of cost and access to store huge amounts of data, sometimes even in raw form. That means that the decision about how to structure data for specific projects can be deferred—you don’t have to know all the ways in which you’ll want to use data at the time that you set up data ingest.
Why is that helpful? For one thing, you can capture data now, as events happen and as data is available, even if you’ve not yet fully built your project teams and plans. That might mean streaming data or batch ingest, but the point is to capture it and thus capture the future value. But it also means that data can be transformed and processed in different ways for different projects. Distributed systems including Apache Hadoop distributions introduced this new style of working with data. In Chapter 5 of the book Real World Hadoop (O’Reilly, 2015), my co-author Ted Dunning and I describe how many companies make the first step into big data in the form of reducing stress on their enterprise data warehouse by offloading some expensive ETL onto a Hadoop cluster. Later, other groups might process that same data for use in a NoSQL database, such as MapR-DB in the case of the MapR Platform. Or they might do a different analysis and export the results to the fields of a searchable document in Apache Solr or ElasticSearch.
Apache Drill, a big data SQL query engine, is another very flexible tool. Surprisingly, Drill supports standard ANSI SQL but also works directly on a wide range of big data sources including complex, self-describing formats such as Parquet and JSON, often with little or no pre-processing required. This capability not only expands the range of data sources but also makes data exploration easier.
Tools such as Apache Kafka or MapR Streams invite broad flexibility in development because a stream-based architecture can use the streaming message queue to support a micro-services approach. We describe how this works in Chapter 3 of Streaming Architecture (O’Reilly March 2016).
All of these tools violate pre-conceptions about how data has to be structured and whether it needs to be heavily processed before it can be usefully queried. They make it easy to build flexible and high performing architectures in ways that are very different from how high performance applications were built not long ago.
The Take-Away Lesson
To get the full value of big data approaches, don’t just rely on assumptions based on your previous experience. Recognize that new technologies not only can save time and money when working at scale, but they also open the door to new ways to work with data.
And when you hear about new technologies, please don’t just assume that I want two shots of espresso.
Want to learn more? Check out these resources:
- Streaming Architecture by Ted Dunning and Ellen Friedman
- Download MapR Sandbox with Apache Drill
- Beyond Real-Time Data Applications Whiteboard Walkthrough

| Reference: | Getting Past Preconceptions: How to Use Innovative Big Data Technologies from our JCG partner Ellen Friedman at the Mapr blog. |
