Editor’s Note: This guest post was authored by Charu Madan and Thomas Weise.
In today’s world of immense competition and customer churn, Telecom Providers are reinventing and transforming to be able to provide their customers with the best possible customer care and satisfaction. The primary goal is to minimize this churn and increase the customer lifetime value. Leveraging the power of big data and the ability to connect structured and unstructured sources of data is giving unprecedented information to providers, which can help them better serve their consumers.
However there are significant technical and operational challenges to accomplish this. And to run it in production 24*7, at scale, in a fully fault tolerant manner adds more layers of complexity. This is where most technologies are brought to their knees.
In this blog we will explore 3 key aspects:
- Explore a Telecom use case where Call Data Records (CDR) are received by MapR Streams and sent to Apache Apex core processing framework for analytics like deduping, dimensional compute and then sent to the DataTorrent Visual console for viewing the information.
- Provide details on the the two technologies being extremely complementary, in terms of the technical strengths and architectural advantages over others
- An Introduction to Apache Apex and its focus on an enterprise grade, fully fault tolerant data processing engine, which provides an architecture that is robust and can scale to meet the stringent needs in a Telecom and other mission critical use cases
Telecom Use case
In the Telecom industry, acquiring customers is expensive, but churn is a lot more expensive. Telecom companies lose customers due to the following reasons:
- Dropped Calls
- Lack of network coverage resulting in poor customer experience
- Bandwidth Issues
- Poor download times.
- Inordinate Service Wait Times
- Are the customer service reps trained well?
- Are the call centers staffed adequately?
- Are there some call centers that are a lot more busier than the others? Do we need to shuffle resources
Analyzing these trends in real time and using data from different sources from both streaming and static sources is a key enabler to get insight on the operational effectiveness of the Network and react in a timely manner to impact customer satisfaction and success. This use case illustrates a scenario to address the above issues. There is a continuous stream of customer Call Data Records (CDR) and Support Call Center statistics. The provider wants to provide a better customer experience by proactively evaluating performance and taking corrective actions. Analytics include monitoring of dropped calls, bandwidth usage patterns, service wait times across different service centers, tracking of customer satisfaction upon service call completion etc.
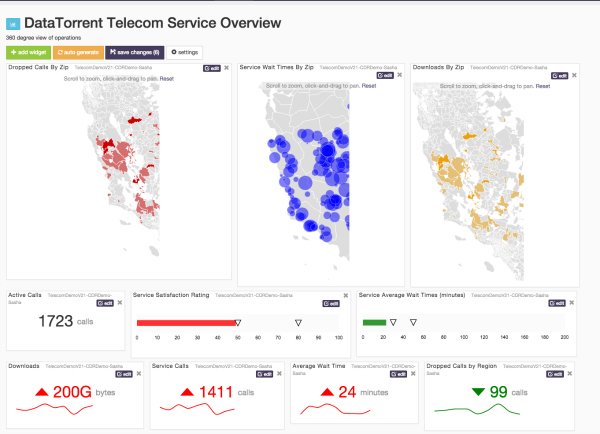
In this scenario, Apex uses MapR Streams to receive the telecom CDR records and call center statistics, which are then processed, enriched, and various metrics for multiple dimensions are computed and stored. The dashboard visualization works directly off the Apex application without the need to write the results to an external store. The data visualizations continually update in real time, as new data is processed. Dashboard widgets also support user-defined queries, such as displaying all dropped calls or service wait times for selected region.
Since the application solely relies on Apex and transitively on components of MapR (Streams, YARN, MapR-FS) it can leverage the scalability, performance and operability of the underlying infrastructure.
In this specific use case, CDR data coming from MapR Streams is being ingested by the Input Operator and then subsequently the data is enriched. The next stage in the pipeline is data is tagged by Geo’s and the relevant KPI’s are calculated. After this calculation, CDR data and the Geo tags are stored in MapR FS. The final output is then displayed in a visualization UI which shows the key metrics to the user with the goal of them being able to take appropriate business action.

Apex and MapR Converged Platform
MapR has traditionally focused on high performance and enterprise readiness, with the file system (MapR-FS) as important foundation. As new components are being added around it, the converged platform becomes a complete, integrated stack that covers all the infrastructure needs for big data applications. The most recent example is the addition of MapR Streams, which adds the missing messaging piece to the puzzle. At the very core are capabilities such as cross datacenter geo-distributed replication and failover, that are unique. There are key themes that resonate with RTS and Apex and make it an ideal choice to complement the application framework layer:
- Focus on fault tolerance, high availability, high performance and SLA support. Focus on enterprise-grade operability.
- Direct support for MapR Streams in Apex via Kafka 0.9 API support. Jointly developed, certified and benchmarked with MapR. An example project can be found here.
- DataTorrent RTS adds the capability to build real-time visualization for use cases that are MapR focus and provides the management tool.
- Apex is compatible with MapR-FS through the Hadoop File System interface and the support was certified.
Introduction to Apache Apex
Apache® Apex (http://apex.apache.org/) is a data-in-motion processing platform that helps to unlock the potential of Hadoop by providing a framework for application development that enables more use cases. Apex comes equipped with essential capabilities for low-latency processing of unbounded data, horizontal scalability, high availability, operability and, importantly, ability to integrate with the existing enterprise infrastructure through a comprehensive library of connectors and functional building blocks.
Apex development started 2012 at DataTorrent and it was built to run natively on Hadoop. The compute resources are scheduled and processes managed through YARN and the Hadoop file system is used to checkpoint state. With its Hadoop native architecture, Apex can take full advantage of the underlying infrastructure and can pass on the benefits to the user.
Hadoop infrastructure originally only supported MapReduce as an application framework, and this was limiting use cases and adoption. With the introduction of Hadoop 2.0, there are alternatives and new frameworks that provide greater flexibility and capabilities to address a broader set of use cases. Now an ever increasing number of alternatives is aiming to fill this gap in the wider big data ecosystem. Apache Apex has an engine for fast and scalable in-memory stream processing. It caters to real-time and batch processing use cases. Apache Apex It aims to deliver delivers superior performance, enterprise readiness and low barrier to entry. Some of the key value points are summarized below: for its focus area:
- Fault tolerance and High Availability, Apex guarantees no loss of data and computational state and exactly-once semantics. In the event of failure, automatic recovery will restore state and resume processing.
- High performance, low-latency stream processing engine, suitable for low millisecond SLA requirements.
- Scalability, provides advanced partitioning schemes and configuration driven platform behavior that don’t require rewrite of the business logic.
- Java based, accessible to widely available application development skillset and ecosystem of 3rd party software. API that is easy to adapt for Java developers and allows reuse of existing functionality.
- Separation of functional and operational specification, no paradigm restriction (like MapReduce) from a platform perspective. This significantly improves the success rate of a big data project.
- A broad library of ready to use building blocks to integrate well with other technologies that solve problems in adjacent spaces (databases, messaging etc.).
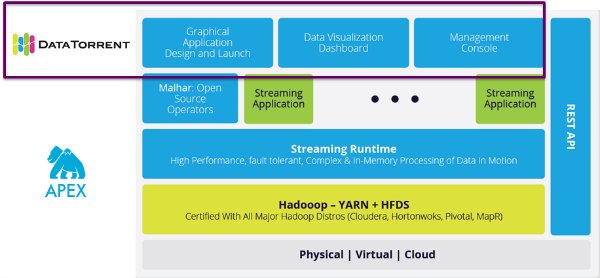
DataTorrent RTS provides components on top of Apex to enhance the user experience. For monitoring, management and debugging of Apex applications, the management console (dtManage) provides a full featured GUI. It is powered through an open and certified REST API, which is part of the management service (dtGateway). It extends the operability focus of Apex with a frictionless installation process, simplified administration and comprehensive security support with a variety of authentication mechanisms plus RBAC.
The other important component in the RTS offering is a data visualization framework (dtDashboard) that is designed to fill another gap for a complete user experience in Hadoop. The user can define in dashboards that visualize the data as it is being processed by Apex applications.
Conclusion
To conclude, Apache Apex is an enterprise grade application framework for stream processing and analytics. It is used in production in large fortune 100 companies, in mission and business critical applications. MapR converged platform (infrastructure layer) combined with Apache Apex (application layer) can provide compelling advantages for use cases where high performance, high availability and no data loss are must haves.
| Reference: | Apache Apex on MapR Converged Platform from our JCG partner Karen Whipple at the Mapr blog. |
