For the past 25 years, applications have been built using an RDBMS with a predefined schema that forces data to conform with a schema on-write. Many people still think that they must use an RDBMS for applications, even though records in their datasets have no relation to one another. Additionally, those databases are optimized for transactional use, and data must be exported for analytics purposes. NoSQL technologies have turned that model on its side to deliver groundbreaking performance improvements.
Here is the presentation I gave at Strata+Hadoop World in Singapore. I walked through a music database with over 100 tables in the schema, and demonstrated how to convert that model for use with a NoSQL database. This blog post is a summary of this presentation.

Why Does This Matter?
Let’s set the stage for why it’s important to evolve from RDBMS to NoSQL + SQL:
- 90% + of use cases I have experienced over the past 20 years are not use cases that require a relational database. They require a persistent store of some sort. Most of the time, those relational databases are chosen because they are supported by IT teams, which makes it very easy to productionize.
- RDBMS data models are more complex than a single table. When you start wanting to traverse the relationships of relational models, they’re complicated. One-to-many relationships require multiple tables, and creating code to persist data takes time.
- Inferred (or removed) keys are used without actual foreign keys. This practice makes it difficult for other analysts to understand the relationships.
- Transactional tables never look the same as analytics tables. From an engineering perspective, software gets written for transactional tables, and then you come up with some ETL process to convert that data into a star schema, or whatever other data warehouse model you’re following, and then run your analytics. These processes take significant time to build, maintain and to operate.
The goal here is to create an “as-it-happens” business and shorten the data-to-action cycle. If I can get rid of having to create ETL process to go from transactional to analytic tables, I’m going to speed up the data-to-action cycle; this is my goal.
Changing Data Models
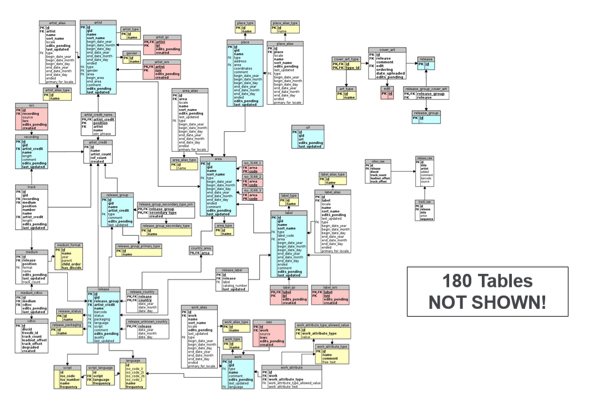
The data model above is actually part of a music database; in fact, there are 180 tables missing from that diagram. This shows that these types of data models can get very complicated, very fast. Overall, this schema has 236 tables to describe seven different types of things. If you are a data analyst, and you want to dig through this schema to find new knowledge, it is probably not going to be easy to write queries to join the 236 tables.
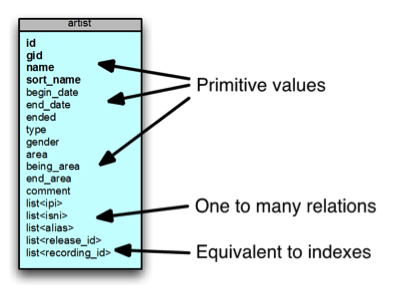
We could take a subset like artist, and we could break it down into one single table, as shown above. In the table, you can see a couple of lists at the bottom. A relational database doesn’t really support the list concept. For many-to-many and one-to-many you have to create special mappings. If we have them all in one single table like this, we can have the nested hierarchy of data objects all together. We can even put other things in here like references to other IDs that we want, and then have the ability to support all the different use cases that we have.
From a music database perspective, if I said, “Given that relational database schema, find for me all of Elvis’ work,” it would be difficult. But with the data model shown above, this is what the query would look like.
Searching for Elvis
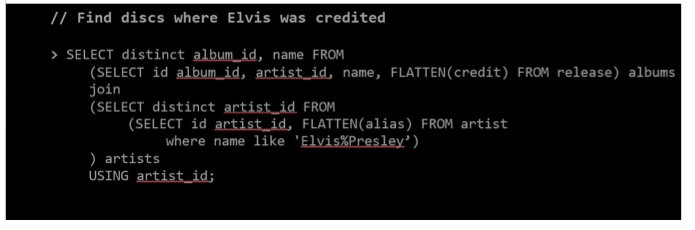
This is a pretty simply nested select query; I don’t have to join hundreds of tables to find what I’m looking for because I have a JSON document model that I can query.
Benefits
- Extended relational model allows massive simplification. If you are a software engineer, writing code to persist your data from your internal data structures to a relational database, even if you’re using something like Java Persistence API, you still have to write code, do a mapping, and test serialization and deserialization. You then have to figure out what things are lazily loaded, and what things are not. If you can write everything as a JSON document, you are going to take about 100x out of your development time for your persistent store.
- Simplification drives improved introspection. We have tools like Apache Drill which allow us to query JSON data, and you can try this out.
- Apache Drill gives very high performance execution for extended relational queries.
A New Database for JSON Data
If you want to get into transactional workloads, you probably want to be using a document database. This is where OJAI (Open JSON Application Interface) comes in. OJAI is the API for the document database that MapR-DB exposes. Some of the entry points in this API do things like insert, find, delete, replace, and update.
For further examples of working with JSON in Java and for creating, deleting, and finding documents in Java OJAI, download the presentation.
Querying JSON Data and More
If you really want to streamline your data-to-action cycle, you need to be able to get in and really query this data. That means enabling data science teams, data analysts, and business analysts to get at the data. If you have people who know how to write ANSI SQL, you can use Apache Drill. It is not a SQL variant; it supports ANSI SQL 2003. You get the ability with the familiarity of SQL, but along with that, you get the benefits that come along with NoSQL, so you don’t have to worry about how to optimize your database for the different use cases that you have.
Drill Supports Schema Discovery On-The-Fly
Apache Drill supports schema discovery on-the-fly. Moving from schema-on-write to schema on-the-fly is a pretty drastic step. So while Drill can read from Hive and use Hive’s metastore, it does not require Hive. If you want to install Drill on your laptop and start querying files, you can do that. It’s pretty nice to have such a low barrier to entry with a technology like this. It does not require a Hadoop cluster, and it does not require anything but a Java virtual machine.
Drill’s Data Model is Flexible
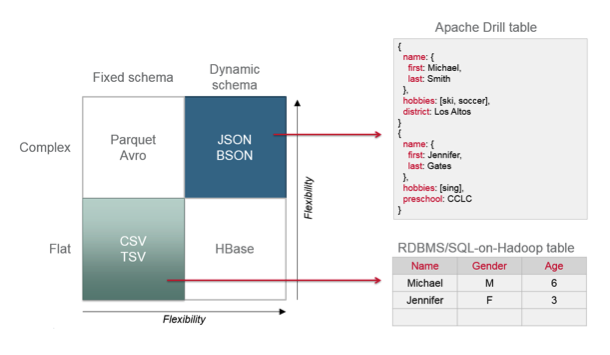
Schema discovery on-the-fly: what exactly does that mean? I’ve got an example on the right in that diagram. These two JSON documents actually have different fields in them. As Drill goes record by record, it dynamically generates and compiles code on-the-fly to handle the schema discovery that it finds. It can handle all of these different records with different schemas as it goes. None of the other SQL-on-Hadoop technologies can do this.
Enabling “As-It-Happens” Business with Instant Analytics
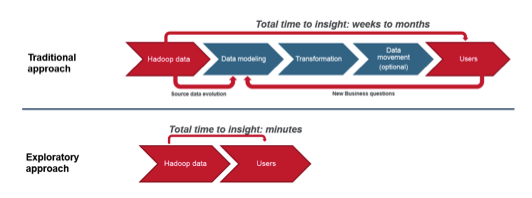
What we do is we essentially get rid of all the middle men in this process to allow people to get at the insights in their data. The goal in most businesses is to enable the people who are data analysts and data scientists to get at the data and ask their questions as quickly as possible. When you have all these stage gates that they have to go through to get data in to figure out how to join that with the data warehouse data that you have, it’s rather complicated, and it usually requires going through a DBA. Keep in mind that I’m not telling you to get rid of your DBAs, and I’m not telling you to throw out good data modeling practices. But with tools like Apache Drill, you can shorten the entire data-to-action cycle by enabling people to bring in their own data sources, and run joins across these data sources with the data that you’ve generated in your business on-the-fly.
We’ve seen some changes with the advent of Hadoop and other big data-related technologies. Technology changes very slowly in the BI space. In data visualization, it was the first area to really allow self-service. This happened roughly fifteen years ago, when people could actually create their own visualizations without having to go through a developer. This was great, as it really helped people get insights into their data faster.
Evolution Towards Self-Service Data Exploration
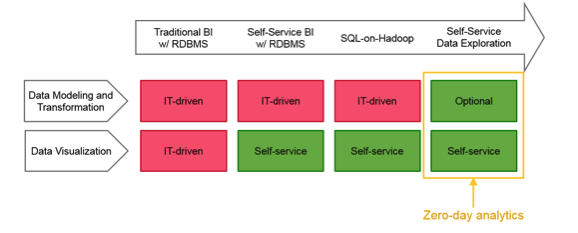
But when we went to SQL-on-Hadoop, nothing really changed. It was a technology swap out. People that started using Hadoop for data analytics swapped out Hadoop for their data warehouse. Now we have the ability to make it so they can do everything. They don’t have to depend on others to come up with new insights. This creates the concept of zero-day analytics. They don’t have to wait; they can find it now.
Drill breaks down queries very simply. It allows you to specify storage plug-ins, and Drill can connect to HBase, MapR-DB, MongoDB, Cassandra, and there’s a branch of it being built for Apache Phoenix. There are connectors that are currently being built for Elasticsearch. It can query delimited files, Parquet files, JSON files, and Avro files. When I talk about Drill, I usually talk about Drill being the SQL-on-everything query engine. You can reuse all your existing tools. It ships with ODBC and JDBC drivers so you can plug it in very easily within your development environment or into your BI tools.
Security Controls
Drill does not require a third party metastore for security. It uses file system security, which means there’s nothing new to learn, and nothing complicated to figure out. You have the ability to put security in groups on views, and on files in your data store, and query it.
Granular Security via Drill Views
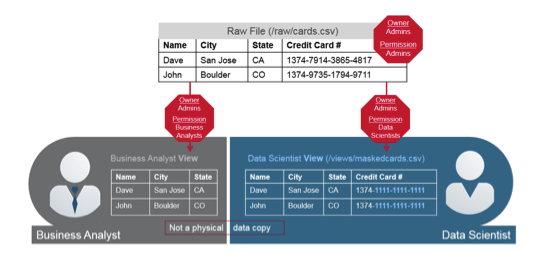
This gives you the ability to create views on top of data, and then create security groups around those views. If you’re the data owner, you can make it so that no one else can access the raw data. But if I create a view that gets rid of the credit card number, or masks it, I can make it so you’re in the group that can read that view. You don’t have direct access to the data, but through security impersonation, it has the ability to hop users, and it makes sure that it can query the data the way that you require. Keep in mind that it does not require additional security store; it uses the file system security. With Apache Drill, security is logical, granular, decentralized, and provides self-service with governance. It’s a pretty compelling choice when it comes to running SQL queries against your data.
- To get an in-depth look at using Drill with Yelp, check out this presentation.
Want to learn more? Check out these resources:
- Get started with Free MapR On-Demand Training
- Test Drive Drill in the cloud with AWS
- Learn how to use Drill with Hadoop using the MapR Sandbox
- Try out Apache Drill in 10 minutes
- Download Apache Drill for your cluster and start exploring
- Check out the comprehensive tutorials and documentation
- Drilling into Healthy Choices
- The Evolution of Database Schemas Using SQL + NoSQL
| Reference: | How to Evolve from RDBMS to NoSQL + SQL from our JCG partner Jim Scott at the Mapr blog. |
