What does “Scale” even mean in the context of databases? When talking about scaling, people have jumped to the vendor-induced conclusion that:
- SQL doesn’t scale
- NoSQL scales
It is very obvious that NoSQL vendors make such claims. It has also been interesting that many NoSQL consumers made such claims, even if they probably confused SQL in general with MySQL in particular. They then go on about comparing MongoDB with MySQL scalability, which totally makes sense as MySQL is to SQL what MongoDB is to NoSQL.
Let’s get back down to earth…
… because in the last decades, there was no database to beat Oracle on the Transaction Processing Performance Council’s benchmarks. We trust that the CERN people have made an informed decision when they opted for Oracle Exadata and other Oracle products to manage their immensely huge data even before huge data was called Big Data.
So let’s make a quick comparison. Recently, Vlad Mihalcea has blogged about “lightning speed aggregation” (with MongoDB). He took a data set of 50 million records of the form:
created_on | value ------------------------------------------- 2012-05-02T06:08:47Z | 0.9270193106494844 2012-09-06T22:40:25Z | 0.005334891844540834 2012-06-15T05:58:22Z | 0.05611344985663891 ... | ...
These are random timestamps and random floats. He then aggregated this data with the following query:
var dataSet = db.randomData.aggregate([
{
$group: {
"_id": {
"year" : {
$year : "$created_on"
},
"dayOfYear" : {
$dayOfYear : "$created_on"
}
},
"count": {
$sum: 1
},
"avg": {
$avg: "$value"
},
"min": {
$min: "$value"
},
"max": {
$max: "$value"
}
}
},
{
$sort: {
"_id.year" : 1,
"_id.dayOfYear" : 1
}
}
]);And got a “mind-numbing”, lightning speed aggregation result:
Aggregation took:129.052s
129s for a medium-sized table with 50M records is lightning speed for MongoDB? Alright, we thought. Let’s try this with Oracle. Vlad had the courtesy to provide us with the sample data, which we imported into the following trivial Oracle table:
CREATE TABLESPACE aggregation_test DATAFILE 'aggregation_test.dbf' SIZE 2000M ONLINE; CREATE TABLE aggregation_test ( created_on TIMESTAMP NOT NULL, value NUMBER(22, 20) NOT NULL ) TABLESPACE aggregation_test;
Now, let’s load that data with sqlldr into my single-core licenced Oracle XE 11gR2 instance:
OPTIONS(skip=1)
LOAD DATA
INFILE randomData.csv
APPEND
INTO TABLE aggregation_test
FIELDS TERMINATED BY ','
(
created_on DATE
"YYYY-MM-DD\"T\"HH24:MI:SS\"Z\"",
value TERMINATED BY WHITESPACE
"to_number(ltrim(rtrim(replace(:value,'.',','))))"
)And then:
C:\oraclexe\app\oracle\product\11.2.0\server\bin\sqlldr.exe userid=TEST/TEST control=randomData.txt log=randomData.log parallel=true silent=feedback bindsize=512000 direct=true
Loading the records took a while on my computer with an old disk:
Elapsed time was: 00:03:07.70 CPU time was: 00:01:09.82
I might be able to tune this one way or another, as SQL*Loader isn’t the fastest tool for the job. But let’s challenge the 129s for the aggregation. So far, we hadn’t specified any index, but that isn’t necessary as we’re aggregating the whole table with all 50M records. Let’s do this with the following equivalent query to Vlad’s:
SELECT EXTRACT(YEAR FROM created_on), TO_CHAR(created_on, 'DDD'), COUNT(*), AVG(value), MIN(value), MAX(value) FROM aggregation_test GROUP BY EXTRACT(YEAR FROM created_on), TO_CHAR(created_on, 'DDD') ORDER BY EXTRACT(YEAR FROM created_on), TO_CHAR(created_on, 'DDD')
This took 32s on my machine with an obvious full table scan. Not impressive. Let’s try Vlad’s other query, filtering on a single hour, which executed in 209ms in his benchmark (what we believe is really not fast at all):
var dataSet = db.randomData.aggregate([
{
$match: {
"created_on" : {
$gte: fromDate,
$lt : toDate
}
}
},
{
$group: {
"_id": {
"year" : {
$year : "$created_on"
},
"dayOfYear" : {
$dayOfYear : "$created_on"
},
"hour" : {
$hour : "$created_on"
}
},
"count": {
$sum: 1
},
"avg": {
$avg: "$value"
},
"min": {
$min: "$value"
},
"max": {
$max: "$value"
}
}
},
{
$sort: {
"_id.year" : 1,
"_id.dayOfYear" : 1,
"_id.hour" : 1
}
}
]);Vlad generated a random date, which he logged as
Aggregating from Mon Jul 16 2012 00:00:00 GMT+0300 to Mon Jul 16 2012 01:00:00 GMT+0300
So let’s use exactly the same dates. But first, we should create an index on AGGREGATION_TEST(CREATED_ON):
CREATE TABLESPACE aggregation_test_index DATAFILE 'aggregation_test_index1.dbf' SIZE 2000M ONLINE; CREATE INDEX idx_created_on ON aggregation_test(created_on) TABLESPACE aggregation_test_index;
OK. Now let’s run the Oracle equivalent of Vlad’s query (note, there’s a new column in the GROUP BY, SELECT, ORDER BY clauses):
SELECT EXTRACT(YEAR FROM created_on), TO_CHAR(created_on, 'DDD'), EXTRACT(HOUR FROM created_on), COUNT(*), AVG(value), MIN(value), MAX(value) FROM aggregation_test WHERE created_on BETWEEN TIMESTAMP '2012-07-16 00:00:00.0' AND TIMESTAMP '2012-07-16 01:00:00.0' GROUP BY EXTRACT(YEAR FROM created_on), TO_CHAR(created_on, 'DDD'), EXTRACT(HOUR FROM created_on) ORDER BY EXTRACT(YEAR FROM created_on), TO_CHAR(created_on, 'DDD'), EXTRACT(HOUR FROM created_on);
This took 20s in a first run. To be fair, before running this statement, I cleared some caches. I believe that Vlad’s MongoDB was already “warmed up” for the second query:
alter system flush shared_pool; alter system flush buffer_cache;
Because when I ran the same query again, it only took 0.02 seconds as Oracle’s buffer cache kicked in, preventing actual disk access. I might have tuned my Oracle instance in a way to keep the whole table in memory from the first query, in case of which Oracle would have beat MongoDB by an order of magnitude.
Another option is to tune indexing. Let’s remove our existing index and replace it with a “covering” index as such:
DROP INDEX idx_created_on; CREATE INDEX idx_created_on_value ON aggregation_test(created_on, value) TABLESPACE aggregation_test_index;
Let’s again flush caches:
alter system flush shared_pool; alter system flush buffer_cache;
And run the query…
- First execution: 0.5s
- Second execution: 0.005s
From the execution plan, I can now tell that the query didn’t need to access the table any longer. All relevant data was contained in the index:
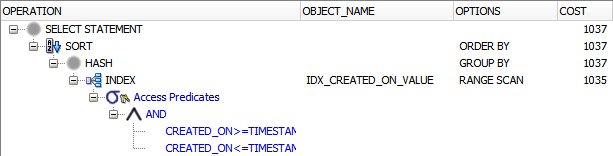
Now that starts getting impressive, right?
So, what conclusion can we draw from this?
Here are a couple of findings:
Don’t jump to conclusions
First off, we should be careful with jumping to any conclusion at all. We are comparing apples with oranges. We’d even be comparing apples with oranges when comparing Oracle with SQL Server. Both benchmarks were quickly written, hacked-up benchmarks that do not represent any productive situations. What we can say already now is that there is not a significant winner when aggregating data in a 50M records table, but Oracle seems to perform better very quickly on an SSD (MongoDB) vs. HDD (Oracle) disk benchmark!
To be fair, my computer has a better CPU than Vlad’s:
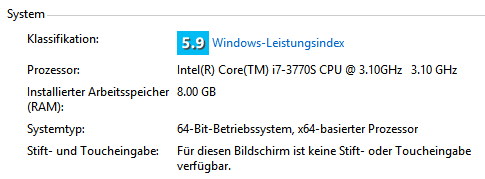
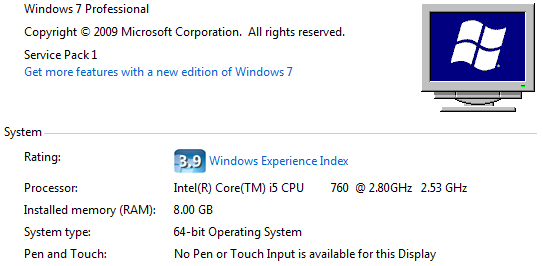
Both SQL and NoSQL can scale
Much of the NoSQL scaling debate is FUD. People always want to believe vendors who tend to say “their product doesn’t do this and that”. Don’t buy it immediately. Run a smallish benchmark as the above and see for yourself, scaling up is not a problem for both SQL and NoSQL databases. Don’t be blinded by Oracle’s initial “slow” query execution. Oracle is a very sophisticated database that can tune itself according to actual need, thanks to its cost-based optimiser and its statistics.
And, nothing keeps you (and your DBA) from using all of your tool’s features. In this example, we have only scratched the surface. For instance, we might apply IOT (Index-organised Table) or table partitioning, if you’re using Oracle Enterprise Edition.
50M is not Big Data
CERN has Big Data. Google does. Facebook does. You don’t. 50M is not “Big Data”. It’s just your average database table.
200ms is not fast
Obviously, you might not care too much how long it takes to prepare your offline report on a dedicated batch reporting server. But if you have a real user on a real UI waiting for it… If they do, 200ms is not fast, because they might be running 20 of these queries. And there might be 10’000 of these users. In a real OLTP system, having such reporting queries around even means that Oracle 0.005s aren’t fast!
So, in other words…
… don’t jump the SQL ship just yet!

Hi Lukas!
Great article! Can you share your testing 50M rows dataset with me? I’d like to perform same query on Redshift.
Thanks, Petr
Petr, that would be very interesting as a comparison! I’ll PM a link to the data file to you, so you can download it. Would be great if you could backlink to Vlad’s and my blog posts for the comparison:
– Vlad: http://vladmihalcea.wordpress.com/2013/12/19/mongodb-facts-lightning-speed-aggregation/
– Our original post: http://blog.jooq.org/2013/12/19/mongodb-lightning-fast-aggregation-challenged-with-oracle/
That was a good read, thanks for the detail. I’ve been reading about some of the in-memory functionality of SQL Server 2014, I would be interested in doing a similar test there and seeing the differences.
Yes indeed. Also, upcoming Oracle versions will support more in-memory querying. RDBMS seem to pull the last registers in vertical scalability…
nice read but where is the scale? you run all on a single pc. can you just perform the same on let say 20 machines and share results? i doubt you can do so for any sql
Good point. I didn’t have time (or the incentive) to do a more realistic benchmark that also checks for scaling out. 20 machines are certainly not going anywhere close to producing significant benchmarks either.
From an Oracle perspective, a relevant publication has been made by CERN who are using Oracle extensively to scale: http://www.oracle.com/technetwork/database/availability/active-data-guard-at-cern-1914404.ppsx
I don’t know about comparable MongoDB case studies.