Faker is an Open Source Python package that generates synthetic data that could be used for many things such as populating a database, do load testing or anonymize production data for development or ML purposes. Generating fully random data isn’t a good choice: with Faker you can drive the generation process and tailor the generated data to your specific needs: this is the greatest value provided by Faker. This package comes with 23 built-in data providers, some other providers are available from the community. The available data providers cover majority of data types and cases, but it is possible any way make the generated data more meaningful by implementing a custom provider.
Faker supports Python 3.6+ and it is available for installation through PyPI or Anaconda.
Here’s a code example that shows how to implement a custom provider to generate synthetic data following the structure and constraints as for this Kaggle dataset related to a restaurant data with consumer ratings and save them into CSV files.
The sample dataset contains users profile data and has 19 features. For simplicity I am going to consider only 10 of them:
- userID: starts with ‘U’ followed by 4 digits
- latitude: a decimal number within the -90, 90 degrees range
- longitude: a decimal number within the -180, 180 degrees range
- smoker: can be true or false
- drink_level: abstemious, casual drinker or social drinker
- dress_preference: no preference, formal or informal
- ambience: solitary, family or friends
- transport: on foot, car owner or public
- marital_status: single, married or widow
- hijos: independent, dependent or kids
The Python code that can generate mock data for this features is the following:
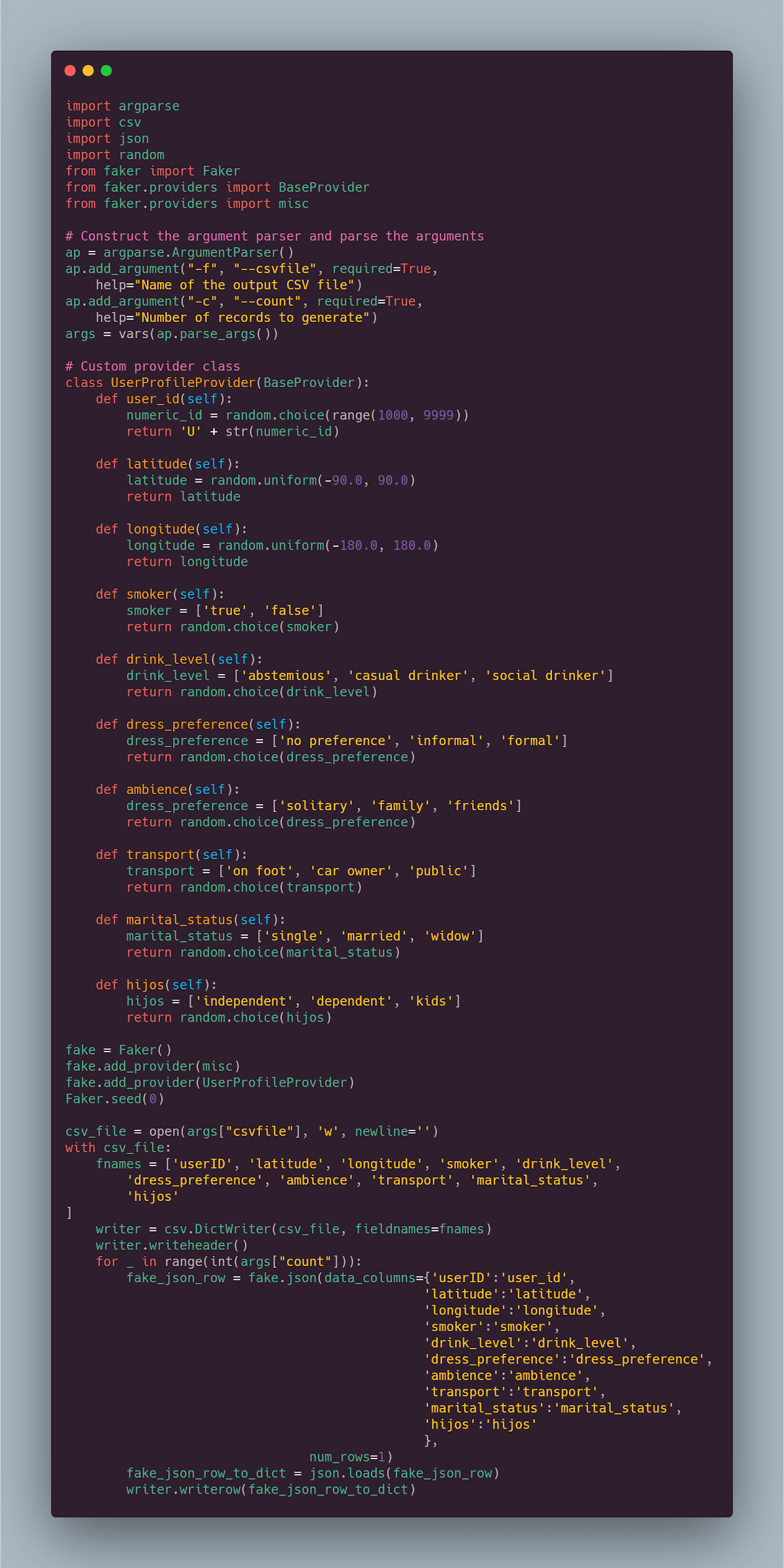
It combines a built-in Faker provider with a custom one. The Faker class creates and initializes a faker generator and
delegates the data generation to providers.
Here is a sample of the generated data after executing the code above:
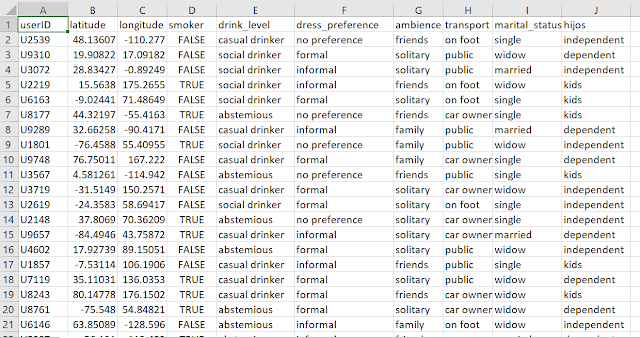
Faker supports localization (also multiple locales for the same data generation task) and can be executed also from a command-line through the faker command.
Definitely a tool worth using. It is already part of mine and my teams Python arsenal since months.
Published on Java Code Geeks with permission by Guglielmo Iozzia, partner at our JCG program. See the original article here: Generating Meaningful Mock Data with Faker Opinions expressed by Java Code Geeks contributors are their own. |

