I watched (COVID19-era version of “attended”) the latest spark Summit and in one of the keynotes Reynold Xin from Databricks, presented the following two images comparing spark usage on their platform on 2013 vs. 2020:
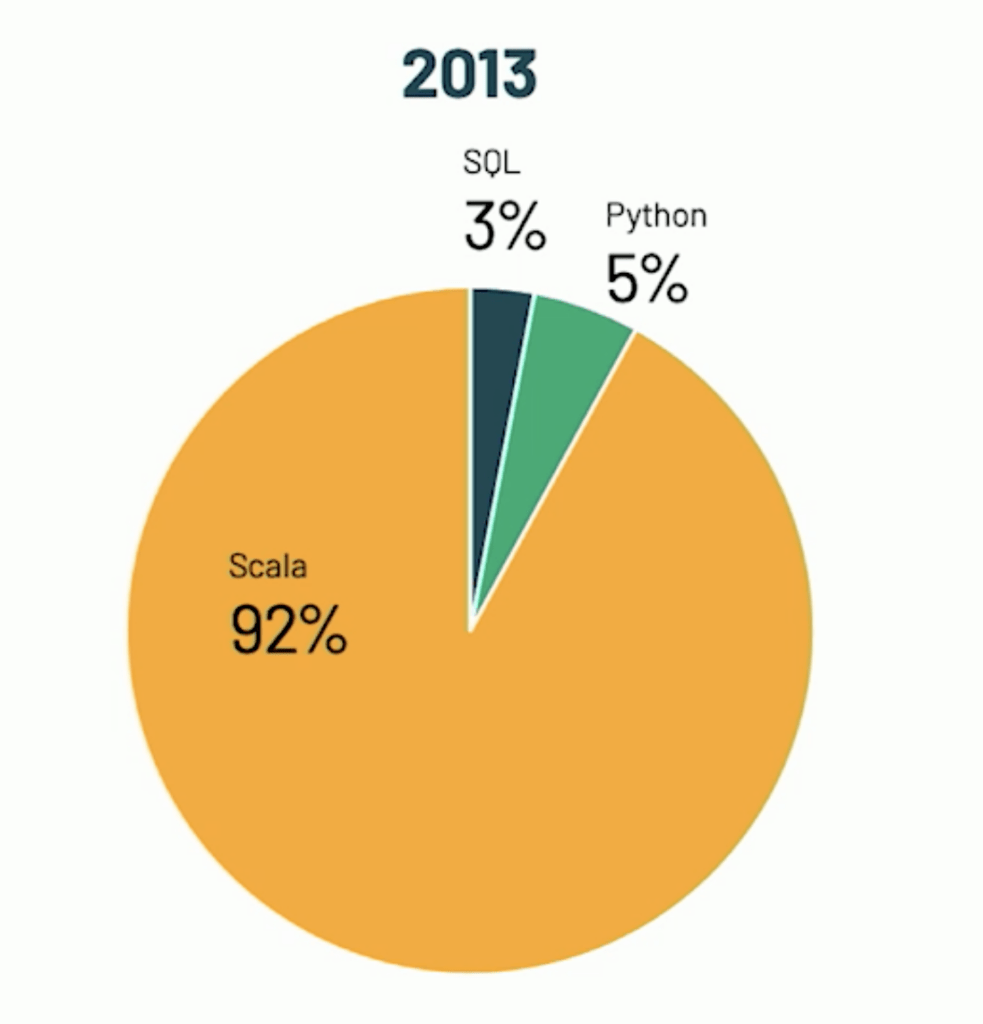
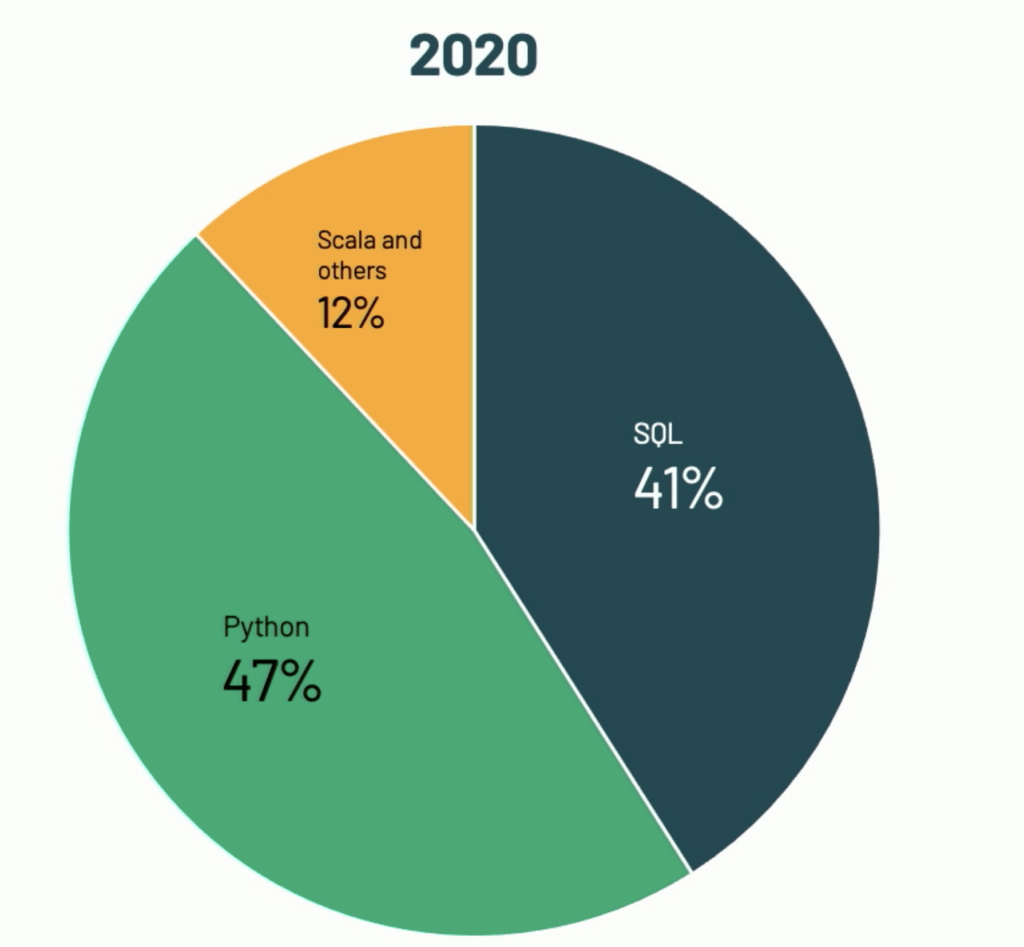
While Databricks’ platform is, of course, not the whole spark community, I would wager that they have enough users to represent the overall trend.
Incidentally, the same trends are also happening outside of the Spark world with SQL re-installing itself as the standard to access data, on traditional RDBMSs, so called “NoSQL” databases (that are getting SQL dialects) and NewSQL offerings. As for Python it is definitely the go-to language for machine-learning (we’ll see if Julia will be able to dethrone it)
Anyway, back to spark, considering these numbers it comes as no surprise that a lot of the efforts that are coming from Databricks are diverging away from Scala and making much more investment in Python:
- Koalas – which is an attempt similar to Dask i.e. trying to replicate pandas API on a distributed engine.
- Project Zen – improving the PySpark developer experience
I have to say, that in my opinion, these two initiatives are crucial for Spark to remain relevant for python development. I have an anecdotal example from a couple of years ago. I worked in a company where we developed predictive models that provide early alerting for medical deteriorations in ICU patients (the respiratory failure model was FDA approved during COVID-19). Since I had a lot of good experience with Spark (on JVM) we started out with PySpark and integrated it with our pandas based feature building (both medical oriented and data science oriented) that look at patient hospitalization time-series data. We got all that to work with Spark but, the cryptic error message and the problematic memory tuning, with two runt-times JVM and python passing data back and forth, drove us to replace this with a new solution we built using Dask. That solution was both easier to work with and used less resources.
The other thing Spark needs to stay relevant, is to provide a good dev experience for deep learning projects. DeepLearning4J can work with Spark, but I think we already established that’s not where spark is heading, nor where ML innovation is happening. The more interesting work on adding Deep-learning to Spark is “project Hydrogen”.
“Project Hydrogen’ is an on-going effort since spark 2.4. It still has some way to go but it already yielded interesting changes like spark on GPUs and barrier scheduler . Barrier scheduler is particularly interesting as it is an additional execution scheduler that is not map/reduce and more aligned with MPI (there are good explanations here and here). This enables things like HorovodRunner and better integration with TesorFlow (better vs. Yahoo’s TensorFlowOnSpark) as can be seen in the example code (posted on the repo):
from spark_tensorflow_distributor import MirroredStrategyRunner
# Adapted from https://www.tensorflow.org/tutorials/distribute/multi_worker_with_keras
def train():
import tensorflow as tf
import uuid
BUFFER_SIZE = 10000
BATCH_SIZE = 64
def make_datasets():
(mnist_images, mnist_labels), _ = \
tf.keras.datasets.mnist.load_data(path=str(uuid.uuid4())+'mnist.npz')
dataset = tf.data.Dataset.from_tensor_slices((
tf.cast(mnist_images[..., tf.newaxis] / 255.0, tf.float32),
tf.cast(mnist_labels, tf.int64))
)
dataset = dataset.repeat().shuffle(BUFFER_SIZE).batch(BATCH_SIZE)
return dataset
def build_and_compile_cnn_model():
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, 3, activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax'),
])
model.compile(
loss=tf.keras.losses.sparse_categorical_crossentropy,
optimizer=tf.keras.optimizers.SGD(learning_rate=0.001),
metrics=['accuracy'],
)
return model
train_datasets = make_datasets()
options = tf.data.Options()
options.experimental_distribute.auto_shard_policy = tf.data.experimental.AutoShardPolicy.DATA
train_datasets = train_datasets.with_options(options)
multi_worker_model = build_and_compile_cnn_model()
multi_worker_model.fit(x=train_datasets, epochs=3, steps_per_epoch=5)
MirroredStrategyRunner(num_slots=8).run(train)
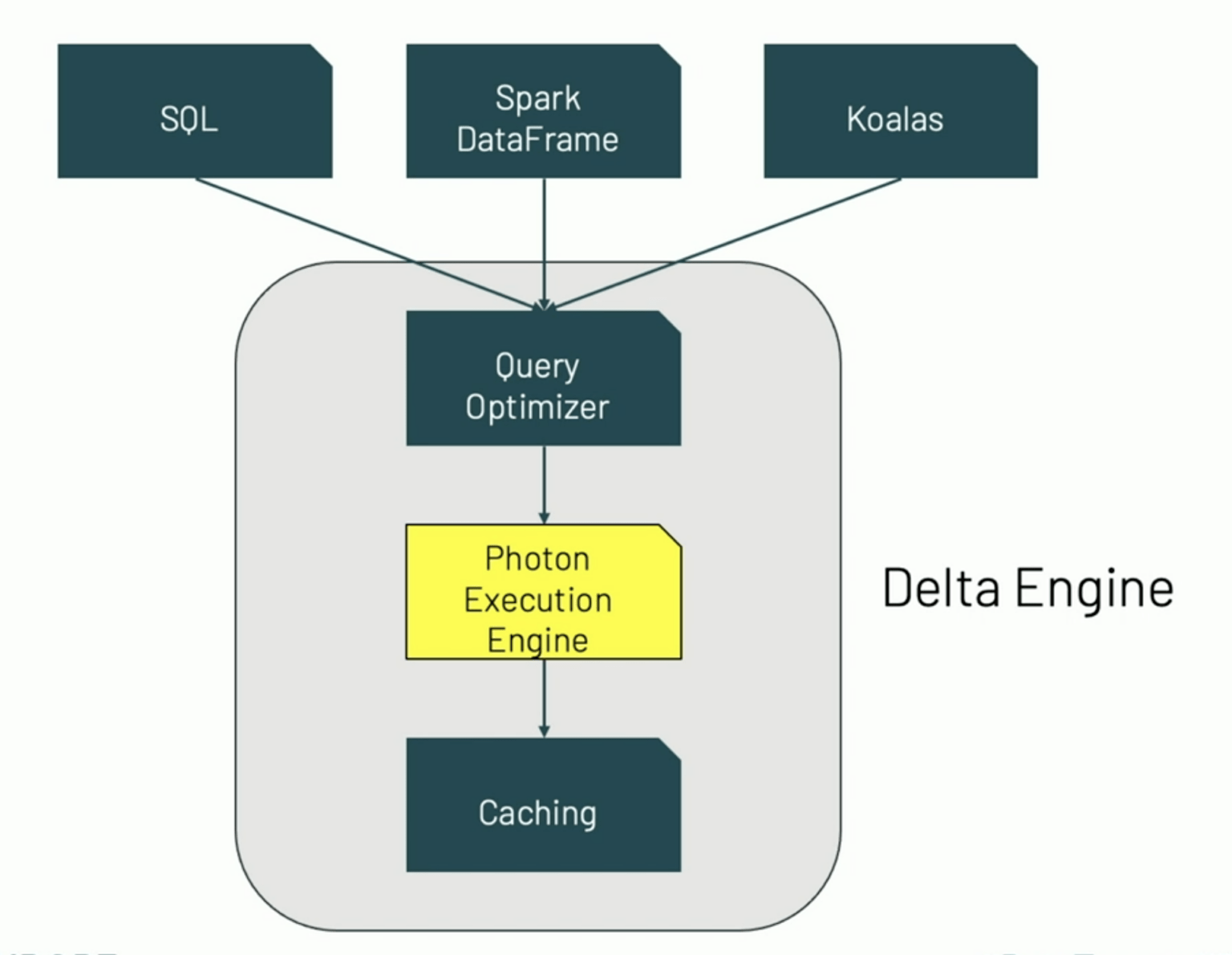
Lastly, if python is taking center-stage, the whole JVM (Scala in this case) is becoming more of a nuisance Spark needs to tag along vs. the advantage it used to be (and still is in many use cases – but we’re talking trends here). Indeed, in a couple of other session on the Spark summit, Databricks talked about the Photon execution engine (depicted below) they are currently developing and is available on Azure Databricks . According to the “brochure” it brings 20x performance improvement over spark 2.4 – this was done by reimplementing Spark’s engine in C++ and I don’t know if this would become open-source or not ,I am not even sure if this is the beginning of the end or just the end of the beginning for spark – I am sure it is a big deal. One other sure thing these changes in spark are bad news for Scala (but that’s for another post :) )
Published on Java Code Geeks with permission by Arnon Rotem Gal Oz, partner at our JCG program. See the original article here: Where is Apache Spark heading? Opinions expressed by Java Code Geeks contributors are their own. |
