In Relational Data Models, we model relation/table for every object in the domain. In case of Cassandra, this is not exactly the case.This post would elaborate more on what all aspects we need to consider while doing data modelling in Cassandra. Following is the rough overview of Cassandra Data Modeling.
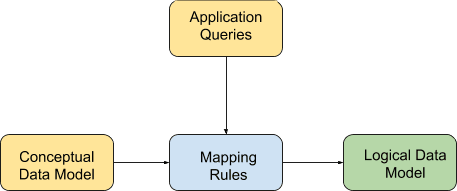
As we can see from the diagram above, Conceptual Data Modeling and Application Queries are the inputs to be considered for building the model. Conceptual Data Modeling remains the same for any modeling(Be it Relational Database or Cassandra) as it is more about capturing knowledge about the needed system functionality in terms of Entity, Relations and their Attributes(Hence the name – ER Model).
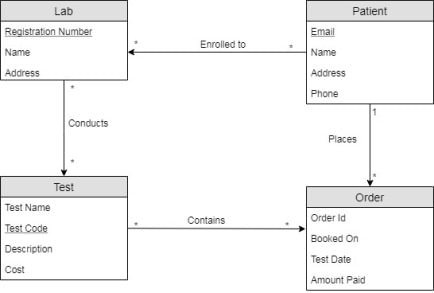
Consider the following example about a Pathology lab portal. This Pathology Lab Portal enables labs to register themselves with the portal that agrees to conduct all the tests suggested. Also it allows patients(users) to register with the portal to book test appointments with lab of his/her choice. Here is a relevant portion of the conceptual model that will be considered for data modeling in Cassandra:
Data modeling in Cassandra is query driven. So, the next step is to identify the application level queries that needs to be supported. For the example taken up, here are the list of queries that we are interested in:
- Q1: Get lab details by the specified registration number?
- Q2: Get all the pending orders that are to be served by a given lab in the order of bookings done?
- Q3: View user details by either his email id/phone number?
- Q4: Get all the pending orders for an user in the specified time period?
Mapping Rules: Once the application queries are listed down, the following rules will be applied to translate the conceptual model to logical model.
- Rule #1: List the attributes on which we will perform equality based queries. For ex: Find a lab by its registration number.
- Rule #2: List range based attributes that have to be used in the queries listed in the earlier step.
- Rule #3: Is there any ordering of the results that the application is interested in? For Ex: Return users sorted by their names in ascending/descending order?
From the conceptual model and queries, we can see that the entity ‘Lab’ has been used in only Q1. As Q1 is equality based, only Rule #1 can be applied from the Mapping rules. So the ‘Lab’ table can be designed as follows:
create table lab_detail(registration_number text, name text, address text, primary key(registration_number));
Entity ‘User’ has been used in Q3. The query specifies to fetch user details by either email id or phone number. In relation databases, we could have created a single user table with one of email id/phone number as identifier. If the data is huge in the table, then an index can be created on the non-identifier column to speed up the data retrieval. But in Cassandra, this is modeled in a different way. We can use 2 tables to address this:
create table users_by_email(email text primary key, phone_number text, first_name text, last_name text, address text);
create table users_by_phone(phone_number text primary key, email text, first_name text, last_name text, address text);
Secondary indexes can be used when we want to query a table based on a column that is not part of the primary key. But one has to be careful while creating a secondary index on a table. They are not recommended for many cases:
- It does not help when you create a index on high/low cardinality columns. If we index based on user title(Mr/Mrs/Ms), we will end up with massive partitions in the index.
- Similarly if we create index on email id, as most of the email ids are unique in which case it is better to create a separate table.
- Also we should not create indexes on columns that are heavily updated. These indexes can generate errors if the tombstones generated are much higher than the compaction process can handle.
As we can see that Secondary indexes are not a good fit for our user table, it is better to create a different tables that meets the application purpose. Note that Data duplication is quite common in Cassandra data modeling. But we should have a limit on how much data we are willing to duplicate for performance reasons. Now the problem with creating different tables is that one needs to be careful of possible Data consistency anomalies.
- What if updates succeeds in one table while it fails in other table?
- How to maintain data consistent in both the tables so that querying data in both tables for a user fetches the same result?
Although Cassandra does not support referential integrity, there are ways to address these issues – Batches and Light Weight Transactions(LWT). Note that batches in Cassandra are not used to improve the performance as it is in the case of relational databases. Batches here are used to achieve atomicity of operations whereas asynchronous queries are used for performance improvements. Incorrect usage of batch operations may lead to performance degradation due to greater stress on coordinator node. More on this here. LWT can be used to achieve data integrity when there is a necessity to perform read before writes(The data to be written is dependent on what has been read). But it is said that LWT queries are multiple times slower than a regular query. One needs to be extra careful when using LWTs as they don’t scale better.
Another way of achieving this is to use the Materialized views. They address the problem of application maintaining multiple tables referring to same data in sync. Instead of application maintaining these tables, Cassandra takes the responsibility of updating the view in order to keep the data consistent with base table. As a result, there will be a small performance penalty on writes in order to maintain this consistency. But once the materialized view is created, we can treat it like any other table. Now that we have an understanding of views, we can revisit our prior design of users_by_phone:
create table users_by_email(email text primary key, phone_number text, first_name text, last_name text, address text);
create materialized view users_by_phone as
select * from users_by_email where phone_number is not null and email is not null and primary key(phone_number, email);
Note that ‘is not null’ constraint has to be applied on every column in the primary key. So we have addressed Q1 and Q3 in our application workflow so far. We are now left with Q2 and Q4:
- Q2: Get all the pending orders that are to be served by a given lab in the order of bookings done?
- Q4: Get all the pending orders for an user in the specified period?
Order details has to be fetched by user in one case and by lab in other case. In Relational Databases, we would have modeled Order, User and Lab as different relations. Q2 and Q4 can be achieved on these relations using JOIN queries on reading data. This has to be modeled in Cassandra differently as read level joins are not possible. Data denormalization has to be done to achieve this use case. As part of denormalization, data gets duplicated. But as discussed briefly earlier, one of the thumb rules in Cassandra is to not see Data Duplication as bad thing. We basically trade off over space compared to time. For the following reasons, Cassandra prefers join on write than join on read.
- Data duplication can be scaled up by adding more nodes to the cluster whereas joins do not scale with huge data.
- Also Data duplication allows to have a constant query time whereas Distributed Joins put enormous pressure on coordinator nodes. Hence it suggests joins on write instead of joins on read. As lab and user are two different entities altogether, these queries can be modelled using two different tables.
A general recommendation from Cassandra is to avoid client side joins as much as possible. So we model the ‘Orders’ entity from Conceptual model using a table(orders_for_user) and a view(orders_for_lab) in Logical Model as done earlier. Mappings Rules #1(Equality based attributes: user_id) and #2(Range based attributes: booking_time) have to be considered for creating table that supports Q4. Columns order_id and test_id are added as part of the primary key to support uniqueness of the row.
create table orders_for_user(user_id text, order_id text, lab_id text, test_id text, booking_time timestamp, amount_paid double, primary key(user_id, booking_time, order_id, test_id));
Similarly the view can be modeled considering Mapping Rules #1(Equality based attributes: lab_id) and #3(Clustering order for attributes: booking_time)
create materialized view orders_for_lab as
select * from orders_for_user where lab_id is not null and order_id is not null and test_id is not null and user_id is not null primary key(lab_id, booking_time, test_id, order_id, user_id) with clustering order by(booking_time asc, order_id asc, test_id asc, user_id asc);
One last point to be considered is when modeling data is to not let the partition size grow too big. A new field can be added to the partition key to address this imbalance issue. For Ex: If some labs are getting too many orders compared to others, this will create imbalanced partitions there by distributing more load to few of the nodes in the cluster. To address this issue, we can add a bucket-id column that groups 1000 orders per lab into one partition. The load is distributed equally among all nodes of the cluster in this way.
Published on Java Code Geeks with permission by Prasanth Gullapalli, partner at our JCG program. See the original article here: Data Modeling in Cassandra Opinions expressed by Java Code Geeks contributors are their own. |
