Continuously build, test and monitor your Microservices for optimal performance.
Summary
For companies migrating their architecture to microservices, anti-patterns can be a major obstacle to success. Here’s how to identify and avoid them.
In my last article, Microservice Patterns That Help Large Enterprises Speed Development, Deployment and Extension, we went over some deployment and communication patterns that help keep microservices manageable as you use more of them. I also promised that in my next post, I’d get into how microservice patterns can become toxic, create more overhead and unreliability, and become an unmanageable mess. So let’s dig in.
First things first: Patterns are awesome.
They help formalize ideas into reusable chunks that you can distribute and communicate easily to your teams. Here are some useful things that patterns do for engineering departments of any size:
- Make ideas distributable
- Lower the barriers to success for junior members
- Create building blocks
- Create consistency in disparate/complex systems
Patterns are usually an intentional act. When we put patterns in place, we’re making a clear choice and acting on a decision to make things less painful. But not all patterns are helpful. In the case of the anti-pattern, it has the potential to create more trouble for the engineering team and the business.
The Anatomy of An Anti-Pattern
Like patterns, anti-patterns tend to be identifiable and repeatable.
Anti-patterns are rarely intentional, and usually you identify them long after their effects are visible. Individuals in your organization often make well-meaning (if poor) choices in the pursuit of faster delivery, rushed deadlines, and so on. These anti-patterns are often perpetuated by other employees who decide, “Well, this must be how it’s done here.”
In this way, anti-patterns can become a very dangerous norm.
For companies that want to migrate their architecture to microservices, anti-patterns are a serious obstacle to success. That’s why I’d like to share with you a few common anti-patterns I’ve seen repeated many times in companies making the switch to microservices. These moves eventually compromised their progress and created more of the problems they were trying to avoid.
Data Taffy
The first anti-pattern is the most common—and the most subtle—in the chaos and damage it causes.
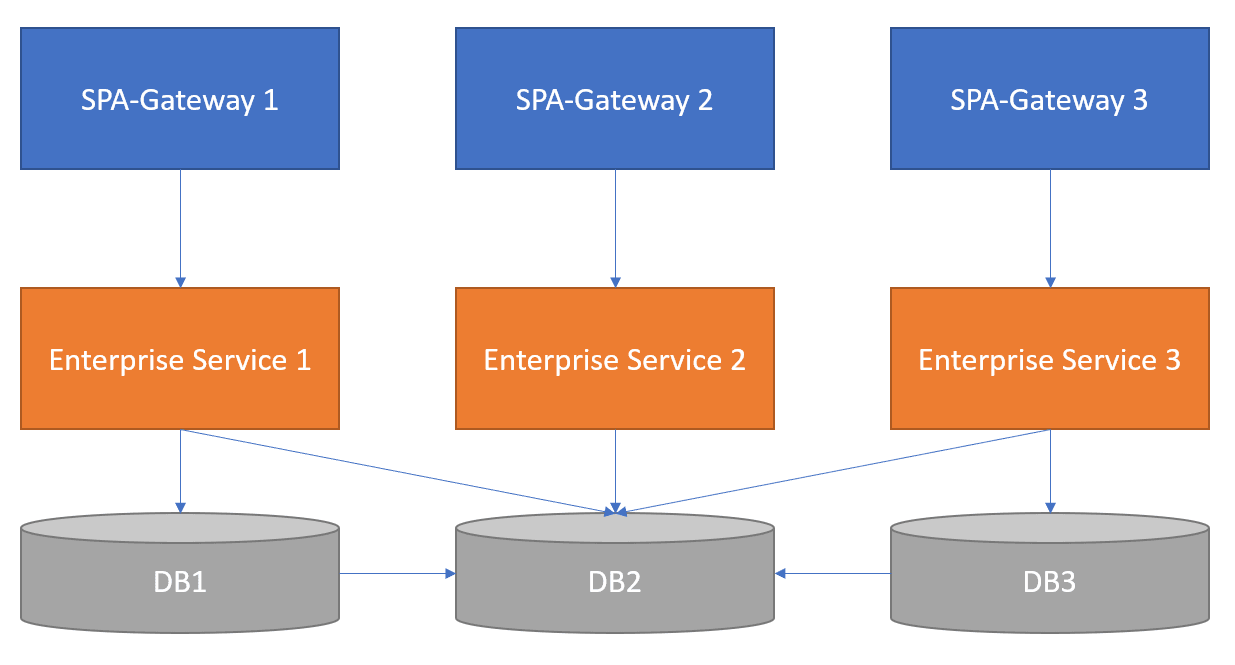
The Problem
The data taffy anti-pattern can manifest in a few different ways, but the short explanation is that it occurs when all services have full access to all objects in the database.
That doesn’t sound so bad, right?
You want to be able to create complex queries and complex data-ingestion scenarios to go across many domains. So at first glance, it makes sense to have everything call what it needs directly from the database. But that’s a problem when you need to scale an individual domain in your application. Rarely does data grow uniformly across all domains, but rather does so in bursts on individual domains. Sometimes it’s very difficult to predict which domains will grow the fastest. The entangled data becomes a lot like taffy: difficult to pull apart. It stretches and gets stuck in the cogs of business.
In this scenario, companies will have lots of stored procedures, embedded complex queries across many services, and object relationship managers all accessing the database—each with its own understanding of how a domain is “supposed” to be used. This nearly always leads to data contamination and performance issues.
But there are even bigger challenges, most notably when you need to make structural changes to your database.
Here’s an example based on a real-life experience I had with a large, privately owned company, one that started small and expanded rapidly to service tens of thousands of clients. Say you have a table whose primary key is an int starting at 0. You have 2,147,483,647 objects before you’ll run out of keys—no big deal, right?
So you start building out services, and this table becomes a cornerstone object in your application that every other domain touches in some meaningful way. Before you know it, there are 125 applications calling into this table from queries or stored procedures, totaling some 13,000 references to the table. Because this is a core table it gets a ton of data. Soon you’re at 2,100,000,000 objects with 10,000,000 new records being added daily.
You have four days before things go bad—real bad.
You try adding negative values to buy time, not realizing that half the services have hard-coded rules that IDs must be greater than 0. So you bite the bullet and manually scrub through EVERY SERVICE to find every instance of every object that has been created that uses this data, and then update the type from an integer to a large integer. You then have to update several other tables, objects, and stored procedures with foreign key relationships. This becomes a hugely painful effort with all hands on deck frantically trying to keep the company’s flagship product from being DOA.
Clearly, not an ideal scenario for any company.
Now if this domain was contained behind a single service, you’d know exactly how the table is being used and could find creative solutions to maintain backwards compatibility. After all, you can do a lot with code that you simply can’t do by changing a data value in a database. For instance, in the example above, there are about 800 million available IDs that could be reclaimed and mapped for new adds, which would buy enough time for a long-term plan that doesn’t require a frantic, all-hands-on-deck approach. This could even be combined with a two-key system based on a secondary value used to partition the data effectively. In addition, there’s one partitionable field we could use to give us 10,000x more available integers, as well as a five-year window to create more permanent solves with no changes to any consuming services.
This is just one anecdote, but I have seen this problem consistently halt scale strategies for companies at crucial times of growth. So try to avoid this anti-pattern.
How to Solve
To solve the data taffy problem, you must isolate data to specific domains only accessible via services designed to service them. The data may start on the same database but use schema and access policy to limit access to a single service. This enables you to change databases, create partitions, or move to entirely new data storage systems without any other service or system having to know or care.
Dependency Disorder
Say you’ve switched to microservices, but deployments are taking longer than ever. You wish you had never tried to break down the monolith. If this sounds familiar, you may be suffering from dependency disorder.
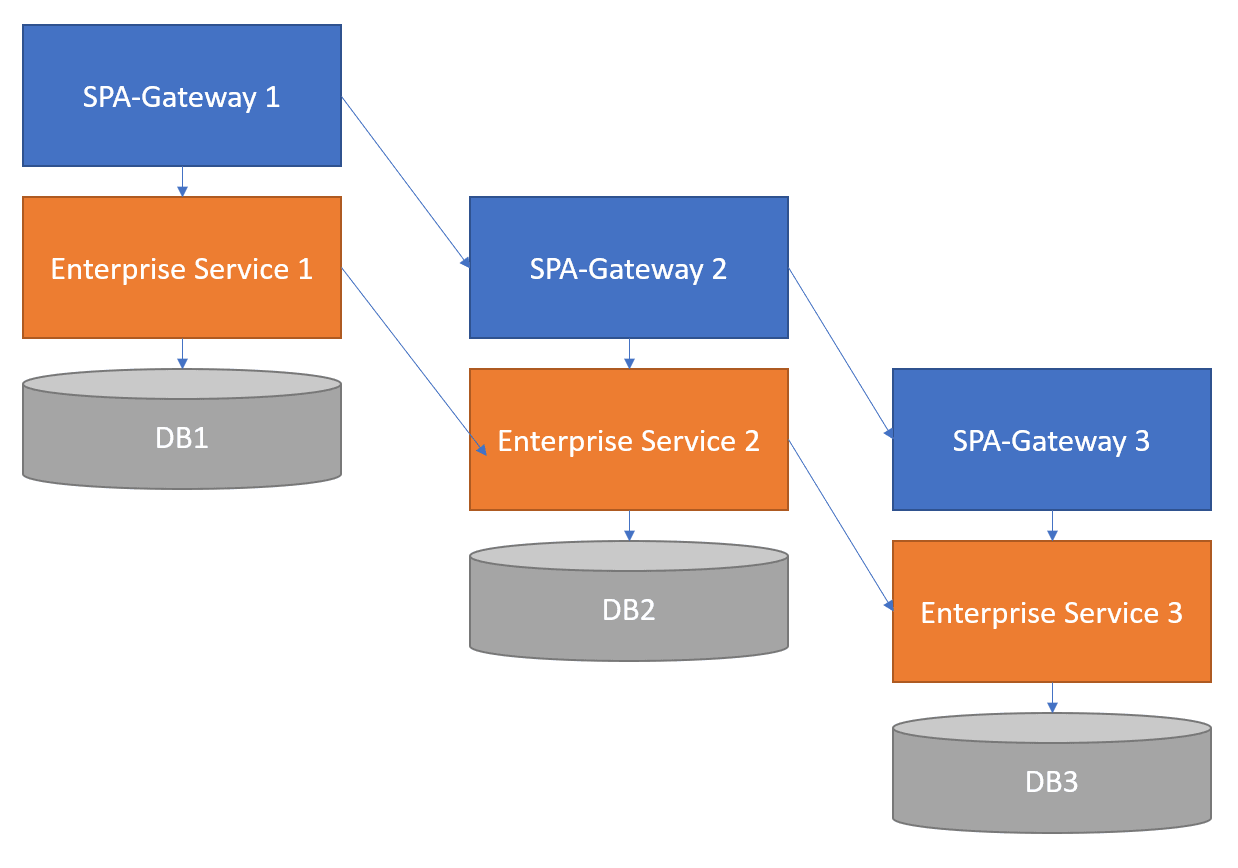
The Problem
Dependency disorder is one of the easiest anti-patterns to detect. If you have to know the exact order that services must be deployed to keep them from failing, it’s a clear signal the dependencies have become nested in a way that won’t scale well. Dependency disorder generally comes from domains calling sideways from one domain’s stack to another (instead of down the stack from the UI to the gateway) and then to the services that enable the gateway. Another big problem resulting from dependency disorder: unknown execution paths that take arbitrarily long times to execute.
How to Solve
An APM solution is a great starting point for resolving dependency disorder problems. Try to utilize a solution that provides a complete topology of your service execution paths. By leveraging these maps, you can make precision cuts in the call chain and refocus gateways to make fan-out calls that execute asynchronously rather than doing sideways calls. For some examples of helpful patterns, check out part one of this series. Ideally, we want to avoid service-to-service calls that create a deep and unmanageable call stack and favor a wider set of calls from the gateway.
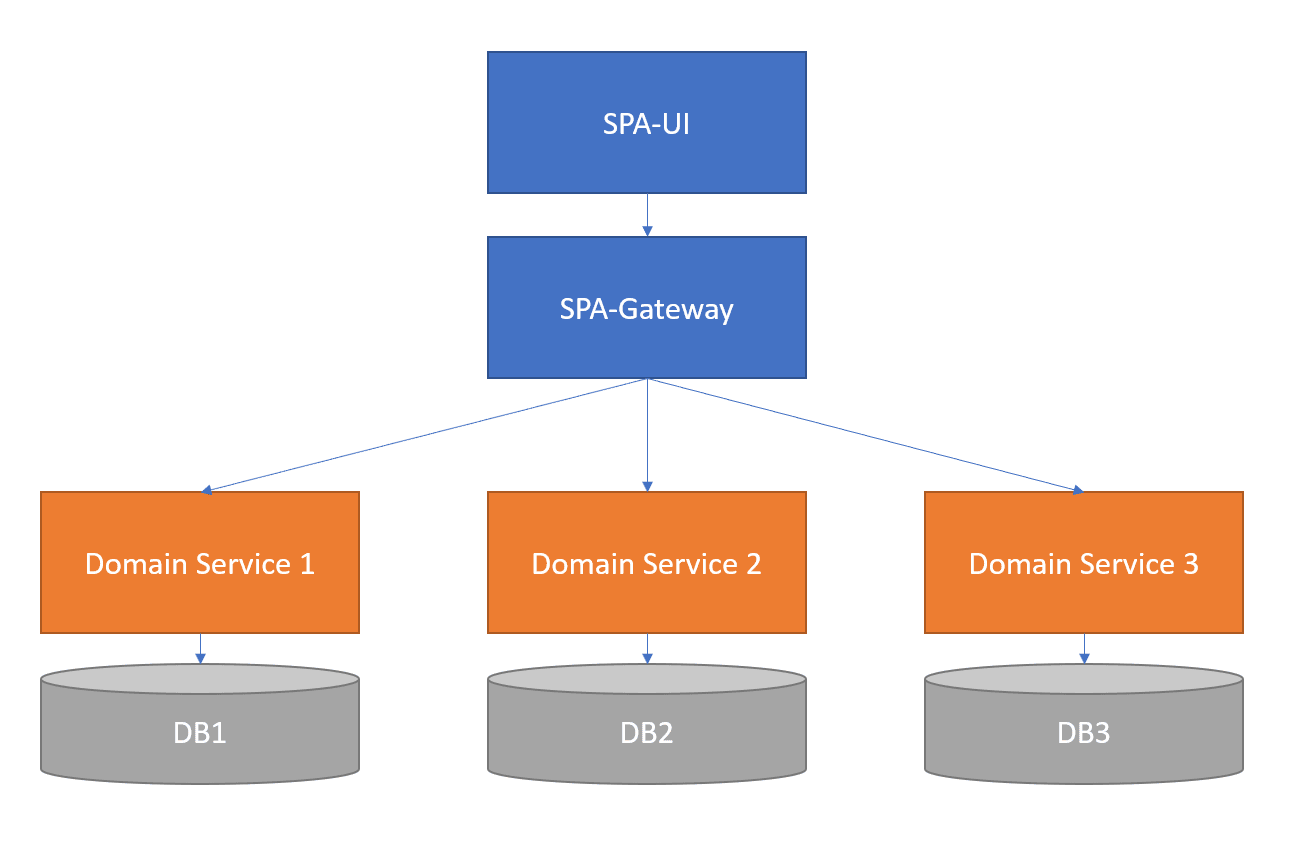
Microlith
Microliths basically are well-meaning, clear-service paths that take dependency disorder to its maximum entropic state.
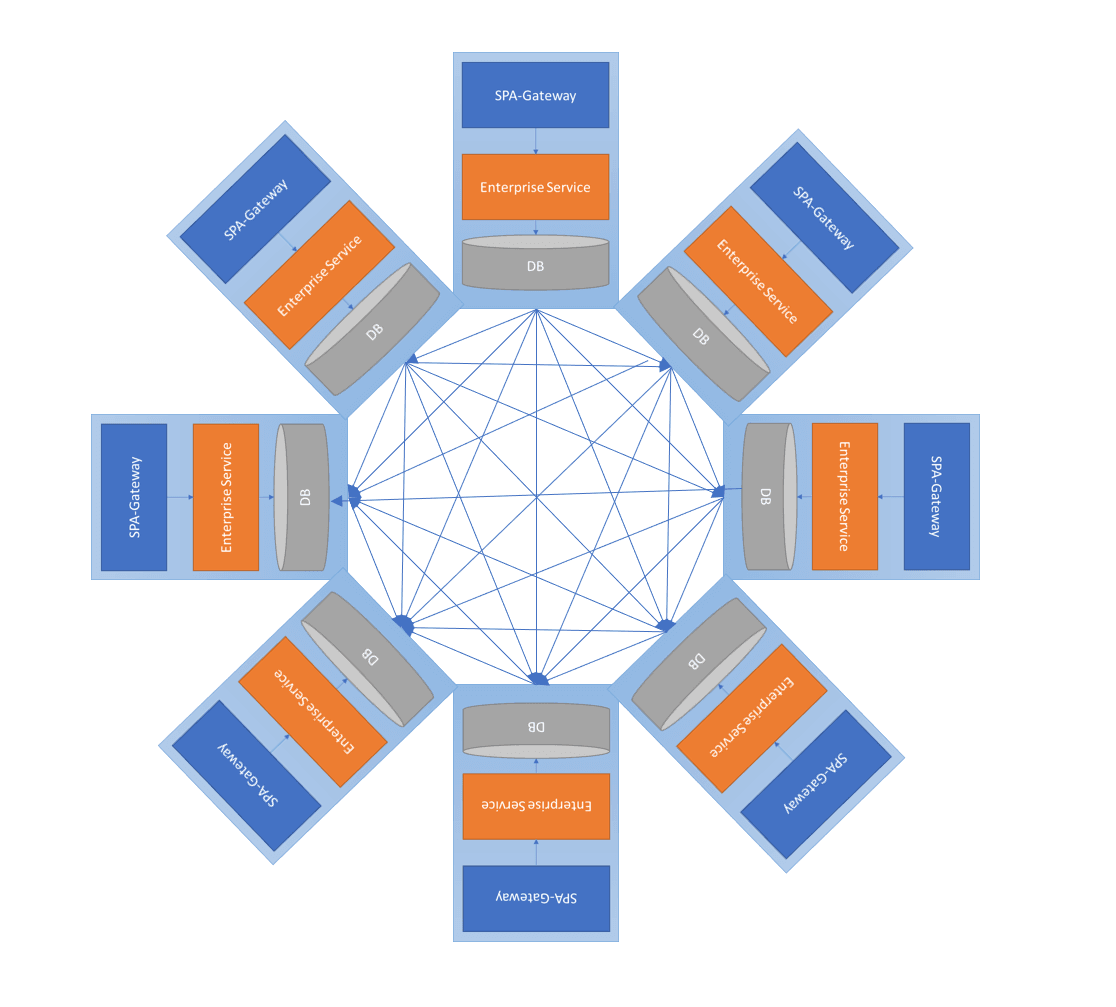
The Problem
Imagine having a really well-designed service, database and gateway implementation that you decide to isolate into a container—you feel great! You have a neat-and-tidy set of rules for how data gets stored, managed and scaled.
Believing you’ve reached microservice nirvana, you breathe a sigh of relief and wait for the accolades. Then you notice the releases gradually start taking longer and longer, and that data-coupling is happening in weird ways. You also find yourself deploying nearly the entire suite of services with every deployment, causing testing issues and delays. More and more trouble tickets are coming in each quarter, and before you know it, the organization is ready to scrap microservices altogether.
The promise of microservices is that there are no rules—you just put out whatever you want. The problem is that without a clear definition of how data flows down the stack, you’re basically creating a hybrid problem between data taffy and dependency disorder.
How to Solve
The mediation process here is effectively the same as with the dependency disorder. If you are working with a full-blown microlith, however, it will take some diligence to get back to stable footing. The best advice I can give is, try to get to a point where you can deploy a commit as soon as it’s in. If your automation and dependency orders are well-aligned, new service features should always be ready to roll out as soon as the developer commits to the code base. Don’t stand on formality. If this process is painful, do it more. Smooth out your automated testing and deployment so that you can reliably get commits deployed to production with no downtime.
Final Thoughts
I hope this gets the wheels spinning in your head about some of the microservices challenges you may be having now or setting yourself up for in the future. This information is all based on my personal experiences, as well as my daily conversations with others in the industry who think about these problems. I’d love to hear your input, too. Reach out via email, chase.aucoin@appdynamics.com; Twitter, https://twitter.com/ChaseAucoin; or LinkedIn, https://www.linkedin.com/in/chaseaucoin/. If you’ve got some other thoughts, I’d love to hear from you!
Continuously build, test and monitor your Microservices for optimal performance.
