We use ActiveMQ as our messaging layer – sending large volumes of messages with a need for low-latency. Generally it works fine, however in some situations we’ve seen performance problems. After spending too much time testing our infrastructure I think I’ve learned something interesting about ActiveMQ: it can be really quite slow.
Although in general messages travel over ActiveMQ without problems, we’ve noticed that when we get a burst of messages we start to see delays. It’s as though we’re hitting some message rate limit – when we burst above it messages get delayed, only being delivered at the limit. From the timestamps ActiveMQ puts onto messages we could see the broker was accepting messages quickly, but was delayed in sending to the consumer.
I setup a test harness to replicate the problem – which was easy enough. However, the throughput I measured in the test system seemed low: 2,500 messages/second. With a very simple consumer doing basically nothing there was no reason for throughput to be so low. For comparison, using our bespoke messaging layer in the exact same setup, we hit 15,000 messages/second. The second puzzle was that in production the message rate we saw was barely 250 messages/second. Why was the test system 10x faster than production?
I started trying to eliminate possibilities:
- Concurrent load on ActiveMQ made no difference
- Changing producer flow control settings made no difference
- Changing consumer prefetch limit only made the behaviour worse (we write data onto non-durable topics, so the default prefetch limit is high)
- No component seems to bandwidth or CPU limited
As an experiment I tried moving the consumer onto the same server as the broker and producer: message throughput doubled. Moving the consumer onto a server with a higher ping time: message throughput plummeted.
This led to an insight: the ActiveMQ broker was behaving exactly as though there was a limit to the amount of data it would send to a consumer “at one time”. Specifically I realised, there seemed to be a limit to the amount of unacknowledged data on the wire. If the wire is longer, it takes longer for data to arrive at the consumer and longer for the ack to come back: so the broker sends less data per second.
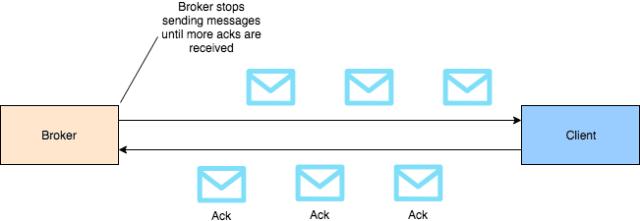
This behaviour highlighted our first mistake. We use Spring Integration to handle message routing on the consumer side, we upgraded Spring a year ago and one of the changes we picked up in that version bump was a change to how the message driven channel adapter acknowledges JMS messages. Previously our messages were auto-acknowledged, but now the acknowledgement mode was “transacted”. This meant our entire message handling chain had to complete before the ack was sent to the broker.
This explained why the production system (which does useful work with the messages) had a much lower data rate than the test system. It wasn’t just the 1ms ping time the message had to travel over, the consumer wouldn’t send an ack until the consumer had finished processing the message – which could take a few milliseconds more.
But much worse, transacted acknowledgement appears to prevent the consumer prefetching data at all! The throughput we see with transacted acknowledgement is one unacknowledged message on the wire at a time. If we move the consumer further away our throughput plummets. I.e. the broker does not send a new message until it has received an acknowledgement of the previous. Instead of the consumer prefetching hundreds of messages from the broker and dealing with them in turn, the broker is patiently sending one message at a time! No wonder our performance was terrible.
This was easily fixed with a spring integration config change. In the test system our message throughput went from 2,500 messages/second to 10,000 messages/second. A decent improvement.
But I was curious, do we still see the broker behaving as though there is a limit on the amount of unacknowledged data on the wire? So I moved the consumer to successively more distant servers to test. The result? Yes! the broker still limits the amount of unacknowledged data on the wire. Even with messages auto acknowledged, there is a hard cap on the amount of data the broker will send without seeing an acknowledgement.
And the size of the cap? About 64KB. Yes, in 2018, my messaging layer is limited to 64KB of data in transit at a time. This is fine when broker and consumer are super-close. But increase the ping time between consumer and broker to 10ms and our message rate drops to 5,000 messages/second. At 100ms round trip our message rate is 500 messages/second.
This behaviour feels like what the prefetch limit should control: but we were seeing significantly fewer messages (no more than sixty 1kB messages) than the prefetch limit would suggest. So far, I haven’t been able to find any confirmation of the existence of this “consumer window size”. Nor any way of particularly modifying the behaviour. Increasing the TCP socket buffer size on the consumer increased the amount of data in-flight to about 80KB, but no higher.
I’m puzzled, plenty of people use ActiveMQ, and surely someone else would have noticed a data cap like this before? But maybe most people use ActiveMQ with a very low ping time between consumer and broker and simply never notice it?
And yet, people must be using ActiveMQ in globally distributed deployments – how come nobody else sees this?
| Published on Java Code Geeks with permission by David Green, partner at our JCG program. See the original article here: ActiveMQ Performance Testing Opinions expressed by Java Code Geeks contributors are their own. |

I haven’t worked on ActiveMQ but plenty of tests on WMQ. I wish I had sufficient stats for comparison of the two. But out of curiosity, have you seen how this behaviour varies when you have multiple consumer threads?
Multiple consumer threads increase the message rate (roughly linearly for a small number of threads, from memory) – which is fine, if you don’t care about message ordering.