As continuation of big data query system blog, i want to share more techniques for building Analytics engine.
Take a problem where you have to build system that will be used for analyzing customer data at scale.
What options are available to solve this problem ?
– Load the data in your favorite database and have right indexes.
This works when data is small, when i say small less then 1TB or even less.
– Other option is to use something like elastic search
Elastic search works but it comes up with overhead of managing another cluster and shipping data to elastic search
–Use spark SQL or presto
Using these for interactive query is tricky because of minimum overhead that is required to execute query can be more than latency required for query which could be 1 or 2 sec.
-Use distributed In-Memory database.
This looks good option but it also has some issues like many solution is proprietary and open source one will have overhead similar to Elastic Search.
– Spark SQL by removing Job start overhead.
I will deep dive in to this option. Spark has become number one choice for build ETL pipeline because of simplicity and big community support and Spark SQL can connect to any data source (JDBC,Hive ,ORC, JSON, Avro etc).
Analytics query generate different type of load, it only needs few columns from the whole set and executes some aggregate function over it, so column based database will make good choice for analytics query.
Apache Parquet is a columnar storage format available to any project in the Hadoop ecosystem, regardless of the choice of data processing framework, data model or programming language.
So using Spark data can converted to parquet and then Spark SQL can be used on top of it to answer analytics query.
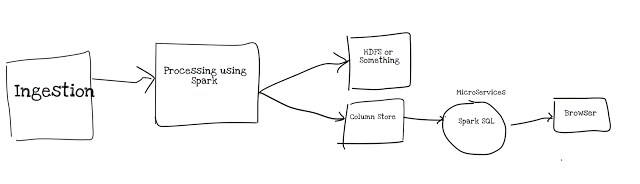
To put all in context convert HDFS data to
parquet(i.e column store), have a micro services that will open Sparksession , pin data in memory and keep spark session open forever just like database pool connection.
Connection pool is more than decade old trick and it can be used for spark session to build analytics engine.
High level diagram on how this will look like:
Spark Session is thread safe, so no need to add any locks/synchronization.
Depending on use case single or multiple spark context can be created in single JVM.
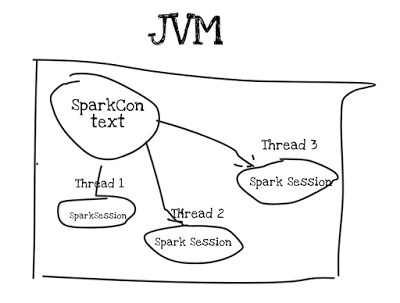
Spark 2.X has simple API to create singleton instance for SparkContext and handles thread based SparkSession also.
Code snippet for creation spark session
def newSparkSession(appName: String, master: String) = {
val sparkConf = new SparkConf().setAppName(appName).setMaster(master)
val sparkSession = SparkSession.builder()
.appName(appName)
.config(sparkConf)
.getOrCreate()
sparkSession
}Caution
All this works fine if you have micro service running on single machine but if this micro service is load balanced then each instance will have one context.
If single spark context requests for thousands of cores then some strategy is required to load balancing Spark context creation. This is same as database pool issue, you can only request for resource that is physically available.
Another thing to remember that now driver is running in web container so allocate proper memory to process so that web server does not blow up with out of memory error.
I have create micro services application using Spring boot and it is hosting Spark Session session via Rest API.
This code has 2 types of query
– Single query per http thread
– Multiple query per http thread. This model is very powerful and can be used for answering complex query.
Code is available on github@sparkmicroservices
| Published on Java Code Geeks with permission by Ashkrit Sharma, partner at our JCG program. See the original article here: Spark Microservices Opinions expressed by Java Code Geeks contributors are their own. |

This is really very well explained. Is it explained using Spring boot anywhere on this site?
thanks for sharing