We’re all guilty of logging malpractice. Don’t think so? These statistics might change your mind
We won’t sit here and ask you questions with obvious answers like, do you use log files to monitor your application in production? We all use logs, and there can be useful information stored there if you know how to find it. But, logs are far from perfect.
In most cases, logs don’t point to the root cause of issues in production. In this post, we’ll be looking at some of the reasons why log files just aren’t enough to create a comprehensive monitoring solution for your application.
Let’s look at the numbers.
1. 20% of errors never make it to the logs in production
We can talk until we’re blue in the face about how logs don’t give sufficient visibility into applications in production, but let’s start with a reality check.
At least 20% of exceptions that occur in production will never make it to the logs at all. Researchers at the University of Waterloo pulled data from over half a million Java projects that included 16M catch blocks and segmented these into groups based on the action taken.
This is what they found:
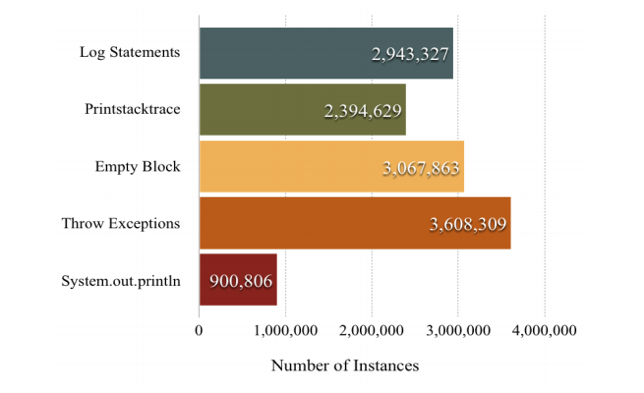
We can take this one step further, grouping these actions into 3 main categories:
- Documenting what happened by either writing something to the logs, printing a stack trace or printing out information to the console.
- Rethrowing an exception, probably a wider abstraction that one of the methods further up the call stack would know how to handle.
- And… Nothing. Swallowing the exception without any clues as to where it came from or why it happened. And looks like it even happens at least as often as logging it which is quite alarming to say the least.
Now, before we get into the real meat of what’s wrong with logs, let’s take a moment to go over the numbers here. 3,067,863 Empty Blocks appears in this research of 16 million catch blocks. That’s around 20% of exceptions that aren’t showing up in the logs at all. That’s not a great place to start.

2. ⅔ of Logging Statements are turned off in production
In another study based on GitHub research, we can see the distribution of the log-levels for the Java projects. INFO and DEBUG took the two biggest pieces of the pie, and together add up to 57.8% of the logging statements. We know, though, that these logging statements are usually turned off in production along with TRACE-level logs which made up another 5.2% of the logs.

Based on this distribution, and what we know about how logs are used, we can determine that 63% of logging statements aren’t running in production.
So far we’ve talked about the amount of exceptions that are occurring right under our noses without being written the logs, and now the amount of logs that we don’t have access to in our production environments.
What do we get from our logs then?
3. More than 50% of logging statements don’t include ANY information about the variable state at the time of an error
So, let’s talk about the information that we DO get from our logs.
We’re interested in the ways in which developers use their logs to, first, identify that an issue has occurred, and second, investigate what went wrong. We’ve already determined that identification of errors using log files isn’t exactly a bullet-proof strategy. At least 20% of exceptions won’t be written to the logs at all, and ⅔ of the logs that we DO add won’t be turned on during production. Basically, we already have a problem.
But we want to know what kinds of things we should (or shouldn’t) be putting in our logs so that when something does go wrong, we’ll be able to fix it. A common practice for understanding and resolving errors in production is to try to reproduce it. And in order to reproduce an error in production, it helps to have a least some idea of the variable state. Looking to the numbers again, we see that more than 50% of logging statements don’t include any variables, and more than 95% of them have 2 or fewer. Yikes!

This means that there’s limited information about the state of the application that is captured in the logs, and finding out what actually happened will probably feel like searching for a needle in a log file. If it’s even there. If it’s not, you’ll have to add logging statements, hope the error happens again, pull the relevant logs, and hope that you caught the right context. This process can take days, if not weeks.
4. Developers Spend 25% of Their Time on Troubleshooting
And now, for the implications of these shocking logging numbers. The bottom line is that relying on logs for monitoring purposes in your production environment just isn’t enough. Ultimately, using logs for troubleshooting in production means that identifying and investigating the issue takes much longer than it should.
We hear all the time from engineering teams that their developers are spending 20, 40, 50% of their time on troubleshooting tasks that take them away from new projects and features that they’re working on concurrently. The cost of context switching to troubleshooting mode is real. Looking at the average, we found that 25% of their time is spent on solving (or trying to solve) production issues. That means they’re dedicating more than a full day of their work week to troubleshooting.
Don’t think it’s that bad? Wait until you see the financial implications of dedicating that much time and resources to troubleshooting.
5. The Ultimate Cost of Logging Malpractice
One company that we spoke with on the topic of production monitoring told us that they have 100 developers working on their product, and that they end up spending about 20% of their time on troubleshooting tasks. On top of that, they have another 21 support engineers that spend 50% of their time on troubleshooting. That basically means that they’re paying 30 full-time developers just to work on troubleshooting tasks. With salaries and expenses that can reach $200K a year or more, that adds up to around $6 million per year!
It’s not hard to do the math on this. With just 20 developers spending 25% of their time on debugging tasks, that’s the same as paying 5 developers a full-time salary to do manual labor and hopefully solve the problems that come up. That could mean hundreds of thousands of dollars a year spent on troubleshooting labor alone.
Clearly, 25% is a lot of time and resources masquerading as a minority percentage. Twenty-five percent is more than a full day out of your work week. Twenty-five percent means adding another full-time employee for every 3 developers. Twenty-five percent means potentially millions of dollars wasted every year.
Final Thoughts
Logs that show how code executes are an ideal thing, but spending too much time trying to find logged information that doesn’t exist is a real thing.
We all use log files, but it seems that most of us take them for granted. With the numerous log management tools out there we forget to take control of our own code – and make it meaningful for us to understand, debug and fix.
| Published on Java Code Geeks with permission by Tali Soroker, partner at our JCG program. See the original article here: 5 Shocking Stats That Prove Logs Are Inadequate Opinions expressed by Java Code Geeks contributors are their own. |
