This is a second post in series describing our recent infrastructure / architecture transition in Plumbr. The first part focused upon event capturing part of the architecture. In the current post we are analyzing how the captured events are stored and are later accessed via user interface. Again, the post walks you through the motivation for the change & describes the choices we made.
For the readers unfamiliar with what we do, first some background to give you the context. Plumbr is designed to monitor every user interaction with an application. These interactions are captured by Agents deployed in the nodes the interaction participating. The captured interactions are sent to Server where the interactions are stored to be queried later.
The Requirements
From such interactions Plumbr captures different attributes to be stored and queried. This gave us the founding requirements for the data structure with different dimensions:
- start and end timestamp of the interaction;
- identity of the user performing the interaction;
- the operation accomplished (add item to shopping cart, create new invoice, etc);
- outcome of the interaction (successful/slow/failed);
- for unsuccessful interaction the root cause(s) in source code;
In addition every interaction has a number of metrics. An example of such a metric can be the total duration of the interaction in milliseconds.
Besides the structure of the data, the data access use cases are relevant when picking the storage. Following are some examples of how our users access the dataset:
- Show me the daily active users trend for a particular application over the past month.
- What were the top three root causes affecting my site performance the most last week?
- Compare the current and last week performance of the checkout operation. Present me the results via comparing the latency distributions for both periods.
Last category of requirements to take into account was by no surprise the non-functional requirements part. From the various NFRs, the trickiest one to fulfill was to make sure we could quickly access vast amounts of data. We had to answer the questions like above from a dataset containing multiple trillions of events. And such answers were to be given in under few seconds.
The Solution
The structural and access patterns of the data made it obvious that we are dealing with a textbook definition of time-series data. After acknowledging the fact, it became painfully obvious that the original decision to store everything in relational database might not have been the best decision.
So we went searching for a new storage solution suitable for time-series data. After testing InfluxDB, Cassandra, MonetDB and Druid, against the requirements we ended up with Druid. In the following sections I will walk you through the most important concepts in Druid allowing us to fulfill the requirements.
Data roll-up
The questions that Plumbr is designed to answer are analytical in nature. This makes it possible to base the answers upon aggregations, instead of individual events. Understanding this, we configured Druid to perform data roll-up during data ingestion. Roll-ups allow us to shift the cost of (some) aggregations and computations to data storage phase instead of the data access phase.
If this sounded too complex, check out the following example. Let us use the following five events representing two different event types (logging in and paying an invoice) all taking place between 12:20 and 12:21 on the same day:
| ID | Event type | Start | End |
|---|---|---|---|
| #1 | login() | 12:20:02 | 12:20:04 |
| #2 | pay() | 12:20:05 | 12:20:10 |
| #3 | login() | 12:20:03 | 12:20:20 |
| #4 | login() | 12:20:42 | 12:20:44 |
| #5 | pay() | 12:20:45 | 12:20:46 |
Now we can roll these five events up to just two entries in the Druid storage:
| Range | Event type | Event count |
|---|---|---|
| 12:20 – 12:21 | login() | 3 |
| 12:20 – 12:21 | pay() | 2 |
As a result of the roll-up we avoided storing individual events. We were able to accomplish this thanks to the event characteristics: instead of storing individual events we rolled the events up to just two individual values in Druid with pre-computed aggregates. The benefit of the roll-up is measurable both in terms of reduced storage requirements and the speedup of the queries.
In our case the outcome of the roll-up is the reduction of the raw events by ten to hundred-fold, depending on the particular application we end up monitoring. The price we had to pay for this is also clear – the minimal granularity of the data access operations is capped at one minute.
Data partitioning
Apparently time-series are … well, dependant on time �� So we have a continuous series of 1-minute buckets containing rolled up data. Most of the queries on such buckets of data perform simple associative aggregations (sum, avg, max and alike).
The associative nature of the aggregations means that Druid can split the original query into separate chunks, run those subqueries in parallel on multiple nodes and then just combine partial results to calculate the final answer. To give you a better idea about this, let’s consider the following example:
User requests the system to “give me the list of the 10 most used endpoints from the www.example.com application during the last 7 days”.
Instead of executing the original query in a single node, Druid Broker will split the query into sub-queries, each requesting data from one day from the 7-day period and execute each sub-query in a different Historical node.:
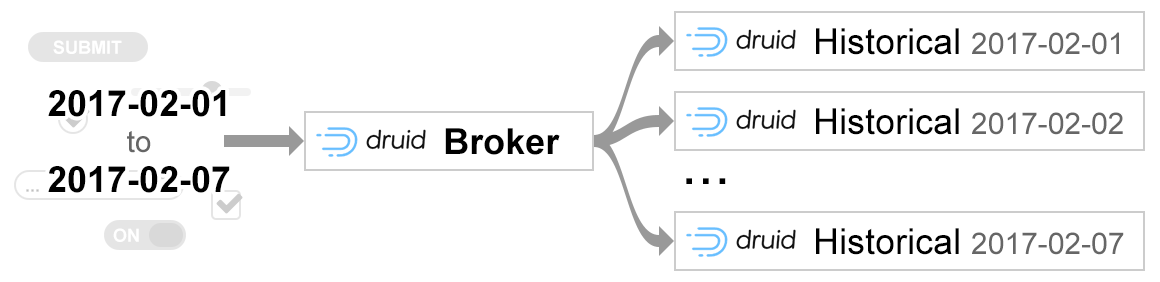
After all the nodes have responded, all that remains is to aggregate the results in the Broker and send it back to the client sending the request.
If this sounds like an implementation of the famous MapReduce algorithm then you are correct, it indeed is. As a result you are greeted with significant query speedup with zero effort from the developers. Side-effect of the approach is getting close to linear horizontal scaling from your infrastructure. Just add more servers to your cluster, make sure partitioning in time is configured according to usage patterns and Druid will take care of the rest.
Real-time data vs historical data
Druid has a built-in separation of concerns between serving the historical and real-time data. In our case “real-time” translates to “last hour”. As we receive and process data from Plumbr Agents via different micro services, Druid will be constantly fed with new data points :
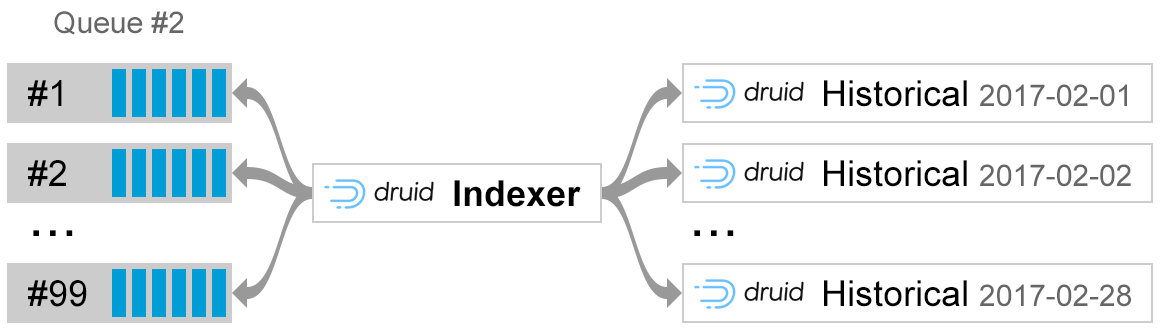
A dedicated indexing node (Indexer) consumes the incoming feed. The very same Indexer will be responsible for answering all (sub)queries about the most recent data from the last hour.
Once per hour, this indexing node converts the raw feed into rolled up data and hands it off to nodes where the data will be stored. These nodes are called Historical nodes. The approach allows Druid to efficiently query two datasets with different characteristics:
- Recent data which is still likely to be changed is queried from raw events in the Indexer node
- Older data, which is not expected to change, is queried from Historical nodes, where the raw events are already rolled up.
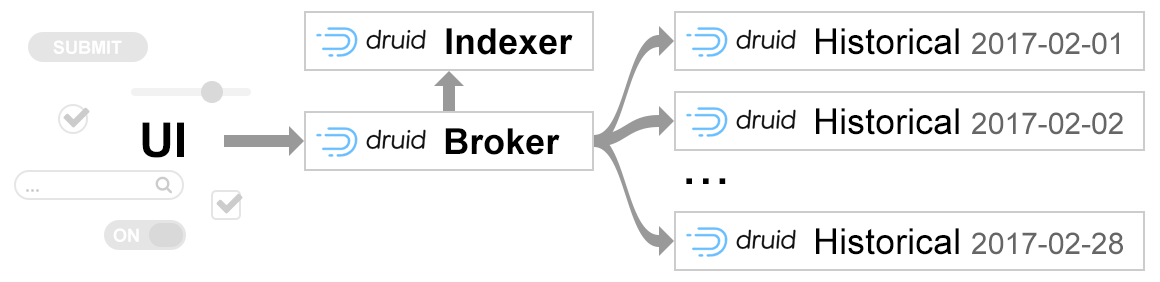
The downside of the approach is the write-only format for the historical data. Making changes to the data in historical nodes is not possible. The only way to update the data is the regenerate entire segments from raw event stream
Take-away
The data processing and storage changes took us six months to implement, test and roll out. We are still polishing the outcome – major changes like this do not tend to expose the full complexity on the whiteboard and tests. I myself have had my fair share of 2AM alerts in the morning when something has not been working as expected.
But I cannot even imagine the life without the new architecture. The synchronous processing on the monolith backed by a relational database feels like a nightmare from a distant past I am trying to forget.
| Reference: | Storing and querying trillions of events from our JCG partner Nikita Salnikov Tarnovski at the Plumbr Blog blog. |
