Throughout the lifecycle of a company the IT architecture is bound to change multiple times. There can be many different reasons for such changes. One of the worst reasons for such change can be when developers get bored by a particular solution and just wish to follow whatever the newest hype happens to be.
Some of the reasons why the architecture changes happen to be better than the “bored developer”. In our case the triggering factor was related to the growth of the inbound traffic to our servers. In this post I am going to walk you through the changes in our architecture during the past six months.
Before jumping into details, some background about the service we needed to scale. Plumbr is operating in analytics/monitoring space where our Agents deployed next to the monitored nodes capture the information about how users interact with the monitored systems. The Agent’s job is to collect the data with minimal overhead and send it to the central Server to be processed.
The problem – too much traffic
The original version of the Server was built upon a simple monolith, processing data in a synchronous manner. This means that we used to have a simple Java servlet on our backend, responsible for:
- accepting & unzipping the data from Agent(s);
- verifying data integrity against checksums;
- decoding from binary format into domain classes;
- passing the data through different processors aggregating/filtering/enriching the data;
- saving the outcome into relational databases & filesystem;
- and finally, if everything went smoothly, responding to the Agent with 200 HTTP response code.
Being a simple and straightforward solution for the problem at hand, this solution has served us well. However, as our user base grew, several problems started to raise their ugly heads:
- The infrastructure, which was designed to process tens or hundreds of millions of events per day started to face throughput issues when the number of events we needed to process grew to billions of events per day.
- Unexpected traffic spikes from one customer started impacting other customers. The growing queue of unprocessed messages meant that all the customers experienced some delay in how fast the incoming events were processed.
- What had worked well with just a few hundred connected agents was already facing connectivity issues as the number of Agents kept growing. To make sure things will break, our product decided to ship our Agents to client nodes (browsers & mobile devices) as well, taking the number of connected Agents to millions.
- The synchronous nature of the communication created an unneeded coupling between Agents and our Server. Problems in Server could impact data receiving from Agents.
So, at least in hindsight it is clear that we needed to change something.
The requirements
Accepting that you have a problem is the first step to recovery. In addition, at least for software engineering, the encountered problems can be used as a source for refined requirements.
So we ended up extracting the following major requirements for the updated architecture. The new Server had to:
- be capable of processing 100 billion events per day;
- be capable of processing 99.9% of the events in under 30seconds;
- support 10 million simultaneously connected agents;
- isolate agents of one customer from another;
- decouple the data reception from data processing;
- be dynamically scalable dependent on the traffic volume.
The requirements are somewhat simplified to keep the post short and concise, but the original goals are preserved.
The Solution – Microservices & Kafka
I will save you from the weeks of trials-and-errors and will just present you the final solution we ended up with. New architecture builds upon decoupling three major phases of the event processing, which can in short be categorized as follows
- Receiving data.
- Processing data.
- Storing data.
The phases are isolated from one another via event queues as seen in the following diagram:
![]()
Data Receiver
One of the simplest requirements to solve was decoupling the data retrieval from data processing. The solution for this introduced the first microservice to our architecture, aptly named “Data Receiver”. The purpose of this microservice would be to
- accept data from Agents;
- verify checksum to ensure that data was not corrupted on the way;
- dump all received data in its raw format to an intermediate queue;
- acknowledge the Agent about successful data receival.
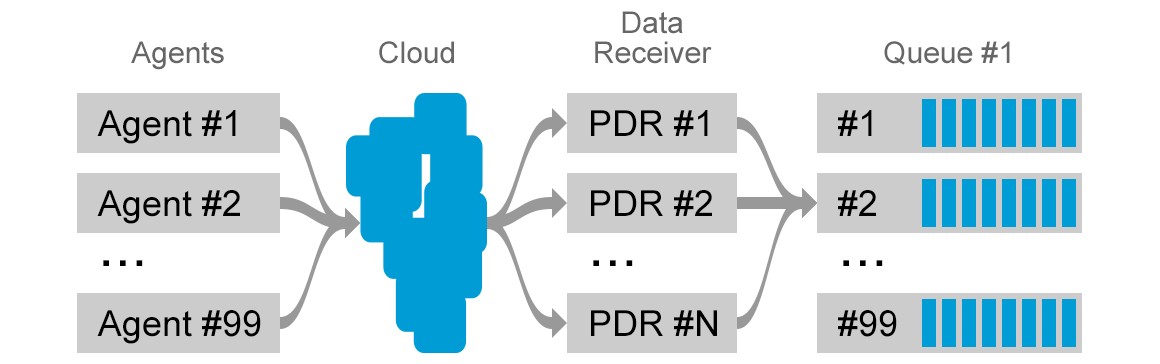
The moment we had identified the need to extract data receiving into a separate microservice we had created a new problem. What could be the technology for the intermediate storage? Especially considering that the storage will be facing a traffic volume of multiple terabytes per hour? What solutions could support multiple writers and readers without any interference, be distributed in nature, have scalability built in, support replication, etc?
After spending a few days in the Internet and some weeks in experiments, the chosen tool for the job was Apache Kafka. The publish-subscribe model on distributed logs of data in the self-replicating clusters seemed like the best fit for our needs.
Almost by accident, picking Kafka also gave us the isolation between customers we were after. When data is captured by Plumbr Data Receiver microservice, it is stored it in original binary format into a Kafka topic assigned to a particular customer. Having dedicated topics per customer gave us the flexibility to build separate consumers for particular topics, throttle processing of some topics or drop some topics entirely in case of a data flood.
Data Processor
Next step in the process was now reading the accepted data from the queue and convert it into various domain objects representing different events. Such events were now passed for dedicated processors, specific to the particular event. Not going into too much details here, but the rules involved composing certain events into one, transforming some events and dropping unnecessary events.
This processing is currently done via a single microservice labeled “ Data Processor”. We already see both the need and possibility to further decouple the processing activities into more fine-grained microservices, but for the time being we are satisfied with the result.
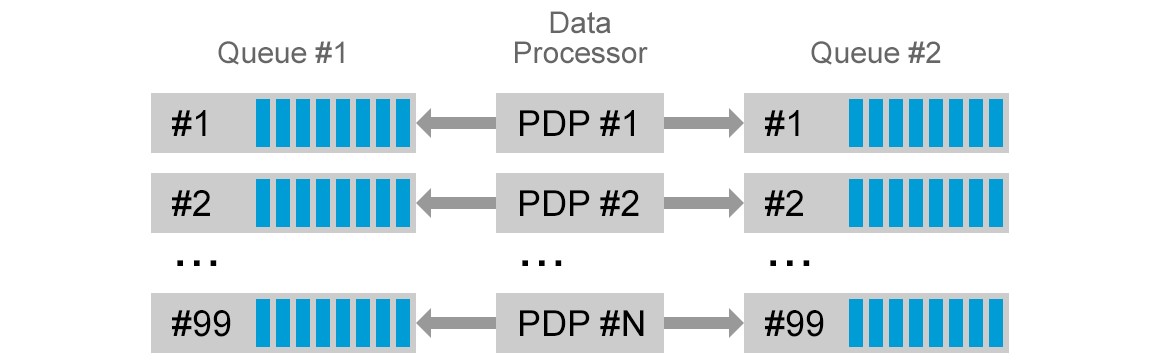
When the data processing part is completed, the outcome is again written to Kafka topics partitioned by customer identity.
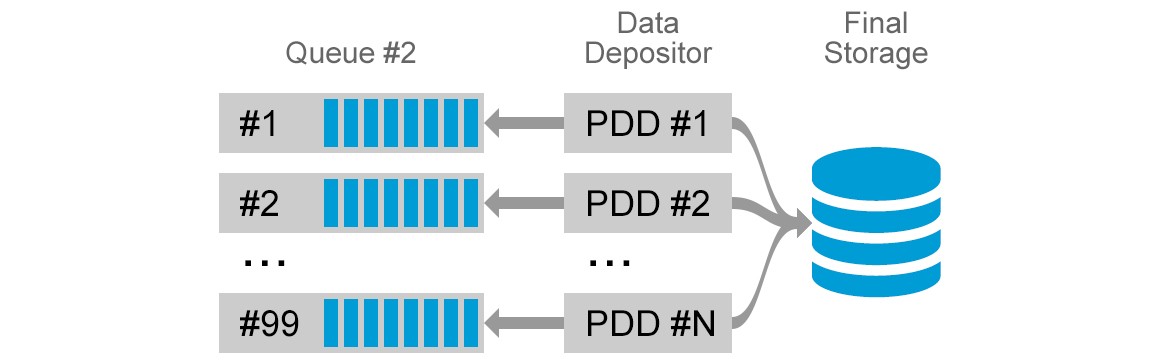
Data Depositor
Last processor in the flow is called Data Depositor. This microservice will be subscribing to the second queue and is responsible for storing the assembled data from topics at the pace the data storage can keep up with. The way we have partitioned the storage so that this does not end up being an issue for us will be covered in the next post.
Take-away
As a result of the changes, we now have the infrastructure, which offers sub-1000ms end-to-end latency for 99.9% of the events at the traffic volume we designed the architecture for. In addition, the data is automatically replicated across multiple Kafka brokers, almost eliminating the need for manual backup procedures. In case of the broker failures new one is started within minutes with Kafka taking care of the redundancy in the background.
Different customers are isolated from one another, meaning that data floods from one customer are no longer impacting other customers. The infrastructure itself allows us to throttle/drop data at different layers.
Different microservices can now be scaled dynamically. Partitioning by the customer identity we can just spawn more nodes in the layer where the processing cannot keep up with the traffic volume.
Sounds too good and structured to be true? Indeed, many of the decisions we made ~six months ago were based on gut feeling and started to make sense only in hindsight. So if you are struggling with an architecture overhaul and are worrying that your train of thoughts does not yet form so clearly, don’t worry. Just start going and you will get there.
| Reference: | Processing billions of events/day from our JCG partner Nikita Salnikov Tarnovski at the Plumbr Blog blog. |
