In my first post, I showed how you might quickly deploy a Drill-enabled cluster to the Azure cloud using the MapR template available in the Azure Marketplace. In my next post, I showed you how you might get that Drill-enabled cluster to query an Azure Storage account as well as an Azure SQL Database. In this post, I want to focus on using this cluster as a data source with Power BI, a data discovery tool that’s popular with users of Microsoft technologies.
The Data Set
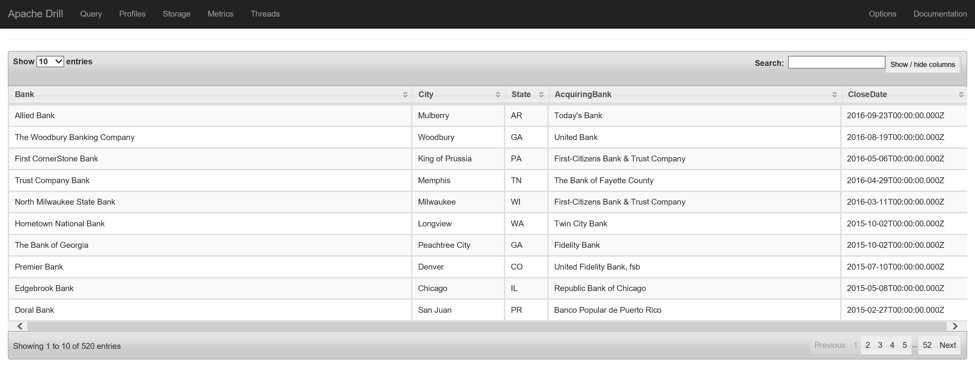
To get started, I’ll load a data set to my Drill cluster. I’ll do this by first opening an SSH session into node 0 of my cluster using the SysAdmin user name (default is mapradmin) and password created at cluster deployment. Once logged in, I then download the Failed Bank List, managed by the Federal Deposit Insurance Corporation, to the local file system and place the CSV file into the cluster file system:
wget http://www.fdic.gov/bank/individual/failed/banklist.csv sudo hadoop fs -mkdir /fdic/ sudo hadoop fs -put banklist.csv /fdic/banklist.csv rm banklist.csv
With the file loaded into the MapR file system, it can now be accessed in Drill using the dfs plugin. With this query, I focus on banks closed since 2008:
SELECT
Bank,
City,
State,
AcquiringBank,
CloseDate
FROM (
SELECT
columns[0] as Bank,
columns[1] as City,
columns[2] as State,
columns[4] as AcquiringBank,
TO_DATE(columns[5], 'd-MMM-yy') as CloseDate
FROM dfs.`fdic/banklist.csv`
WHERE columns[0] <> 'Bank Name'
) a
WHERE DATE_PART('year', CloseDate) >= 2008; 
NOTE Consider deploying your query as a view within Drill. This will allow some BI tools to more easily pickup schema information like column data types.
NOTE Your storage plugin can be configured to read the header line from CSVs (and other text file types). This is done by adding the extractHeader property to the storage plugin’s file type definition as illustrated here. This configuration is more performant and will allow you to reference column names directly without having to use the columns[n] identifiers. Still, this requires the files of this type associated with the storage plugin to make consistent use of header lines.
Connecting with Power BI
With data accessible through Drill, I can now focus on connecting to it through Power BI. The first thing I need to do is make sure I have the latest version of the Power BI Desktop tool, available for free here.
Next, I need to determine whether it’s the 32-bit or 64-bit version of the Power BI Desktop tool, which has been installed to the desktop. To do this, I launch Power BI, close the splash screen, and from the File menu, click Help and then About. The resulting dialog identifies the bitness of the app.
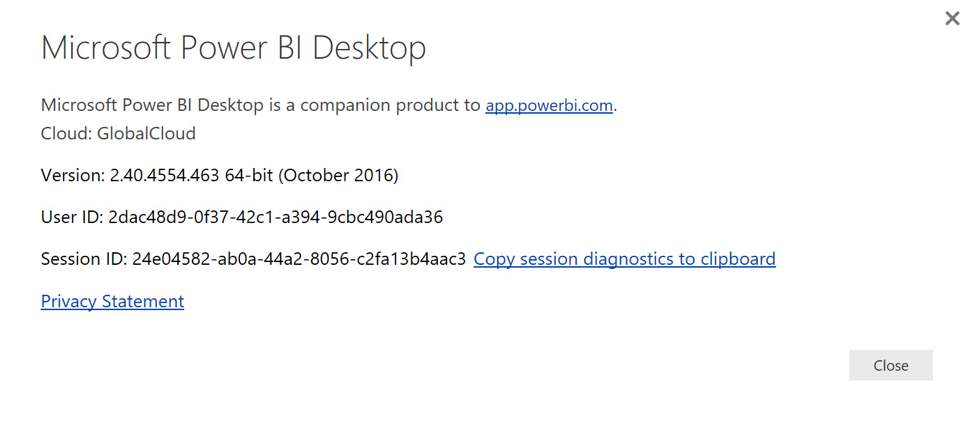
With the bitness of Power BI known, I can now download the appropriate ODBC Driver for Drill, matching the bitness of the driver with the bitness of the app. (If you are reviewing the instructions provided with the ODBC Driver, you do not need to configure the driver beyond its basic installation supported by the MSI.)
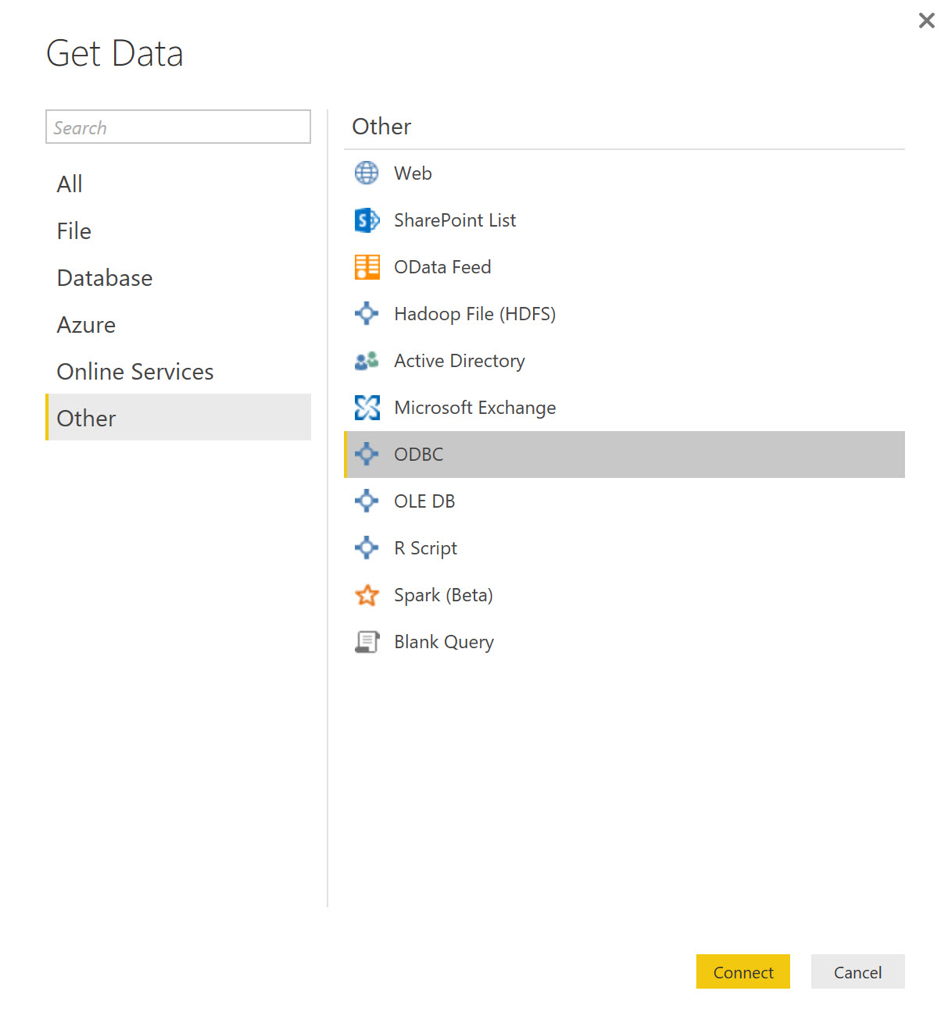
Now that everything is in place, I launch Power BI and, from the splash screen, select Get Data. In the resulting Get Data dialog, I select Other from the left-hand navigation and then ODBC in the resulting list.
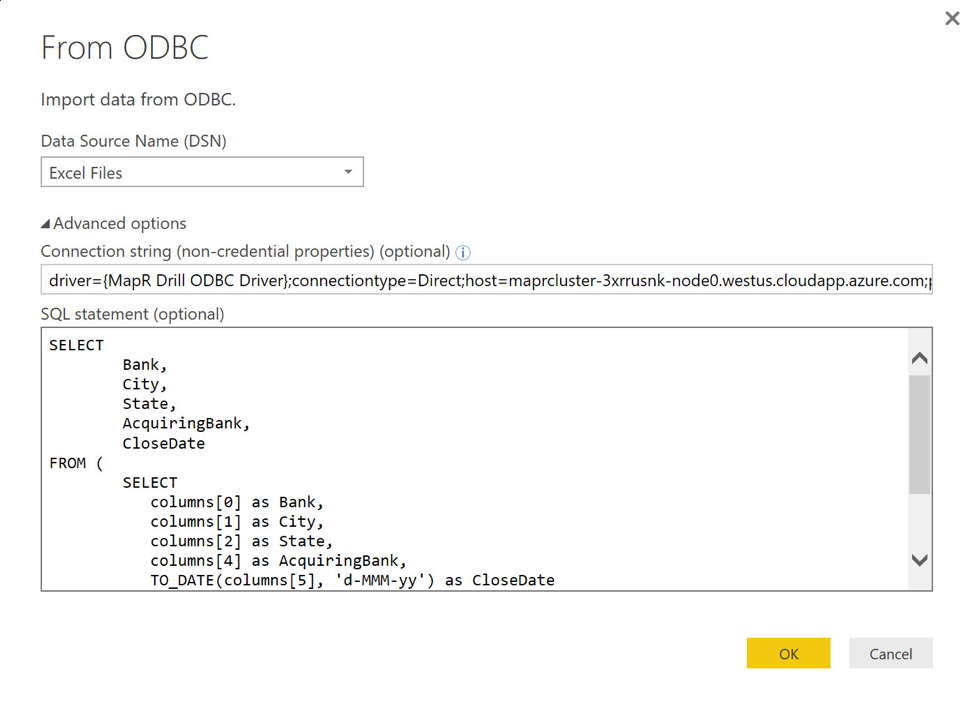
Clicking Next takes me to the From ODBC dialog. Here, I click on the Advanced options item, ignoring the Data Source Name (DSN) drop-down, and enter a connection string with the appropriate substitution for the host parameter:
driver={MapR Drill ODBC Driver};connectiontype=Direct;host=maprcluster-3xrrusnk-node0.westus.cloudapp.azure.com;port=31010;authenticationtype=No Authentication
Notice the connection string employs a Direct connection type, indicating that the app will speak directly to one of the nodes in the cluster (as identified by the host parameter) and not to the ZooKeeper service. ZooKeeper is in use on the cluster but is not exposed externally, given the network security group changes made during my earlier deployment. Even if ZooKeeper were exposed, it tracks the nodes of the cluster using their internal names so that any app outside the virtual network containing the cluster would not be able to leverage the information in ZooKeeper to form a connection. The only option that works here is the Direct connection type.
NOTE For more information on network connectivity to an Azure-deployed Drill cluster, please check out this blog post.
Notice, too, that the No Authentication option is set as the Drill environment deployed with the template defaults to this authentication type. Should you change the authentication type employed by the cluster, you will need to choose a different option for this parameter.
Returning to the From ODBC dialog, I enter the SELECT statement from above into the SQL statement (optional) text box. When entering the SQL statement, be sure to omit the closing semi-colon used in the earlier example.
Clicking OK takes me to the Access a data source using ODBC driver dialog ,where I’m asked to provide security information. Since I’m using the No Authentication authentication type, I simply choose Default or Custom from the left-hand navigation and do not enter any additional information in the optional textbox.
Clicking Connect takes me to a data preview page. If I need to shape the data further, using the capabilities of Power BI, I can click the Edit button, but as the data is already in good shape, I simply click Load to proceed.
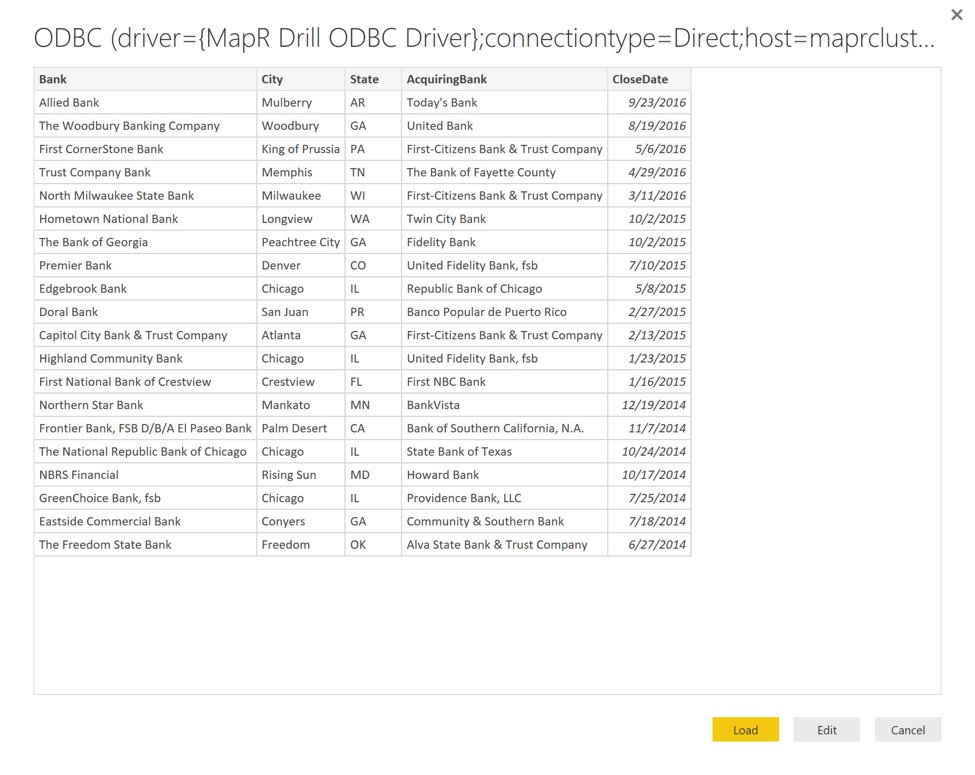
With data loaded into the Power BI desktop app, I can proceed to build an interactive report. If you are new to Power BI and would like to learn more about how to build reports, check out the videos and tutorials found here.
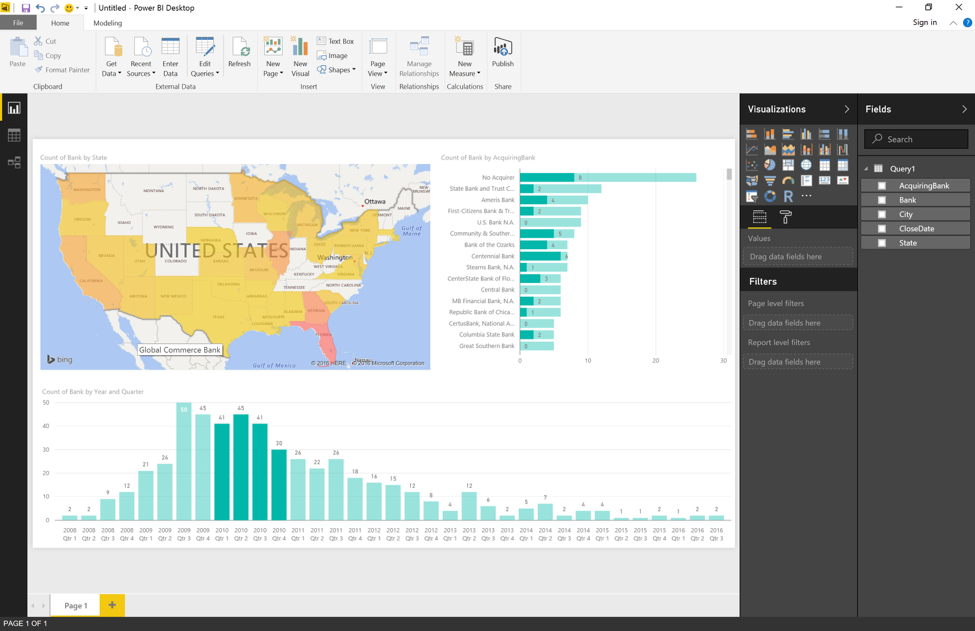
A Few Closing Thoughts
I am very fond of Power BI. It’s an excellent tool for data shaping and modeling, and the capabilities you get – even with the free version – are incredible. That said, I have two suggestions to the Power BI team for improving interactivity with Drill.
First, I’d like to see the application provide native support for the ODBC Driver for Drill. This would enable users to connect to a Drill cluster, have the Power BI tool retrieve schema information, and allow users to build data sets interactively without having to write any SQL statements.
Second, I’d like to see the application provide support for live queries against Drill. The default mode for Power BI is to extract data to a surprisingly robust in-memory cache, which is what I did in this demonstration. But with some data sources capable of rapid query response, such as Spark, Power BI provides an option to perform live queries against the back end. This allows updates to that back end to be immediately visible without having to schedule an automated refresh of the cache. Drill is capable of supporting this, and so I’d like to see this option available in Power BI.
The good news here is that the Power BI team maintains a UserVoice site, where suggestions for improvements can be submitted and voted upon. The information collected through this site directly affects development priorities for the Power BI team, so if you’d like to see these changes implemented in the Power BI product, please vote for them here.
| Reference: | Connecting to Apache Drill with Power BI (Part 3) from our JCG partner Bryan Smith at the Mapr blog. |
