In my last post, I deployed a MapR cluster to the Azure cloud using the template available through the Azure Marketplace. My goal in doing this was to get a Drill-enabled cluster up and going in Azure as quickly as possible.
My emphasis on Azure indicates that I am probably making use of the Microsoft cloud for a broader range of activities than just running this one cluster. So, while I will load the bulk of the data I intend to use with Drill into the MapR cluster’s native filesystem, it’s likely that I will have already loaded some data into other Azure resources and will want to query these as well. To do this, all I need to do is load the appropriate drivers into the Drill environment and configure storage plug-ins within the cluster for each resource. That is the focus of this blog post.
My Test Environment
Before jumping into the technical details, it’s important to understand the Azure environment I’ve configured for this demonstration. In the last post, I provided a fairly granular breakdown of the assets that make up my three-node MapR cluster. Here, I’ll simply refer to that as a single resource to focus on the other Azure assets into which I will be integrating it.
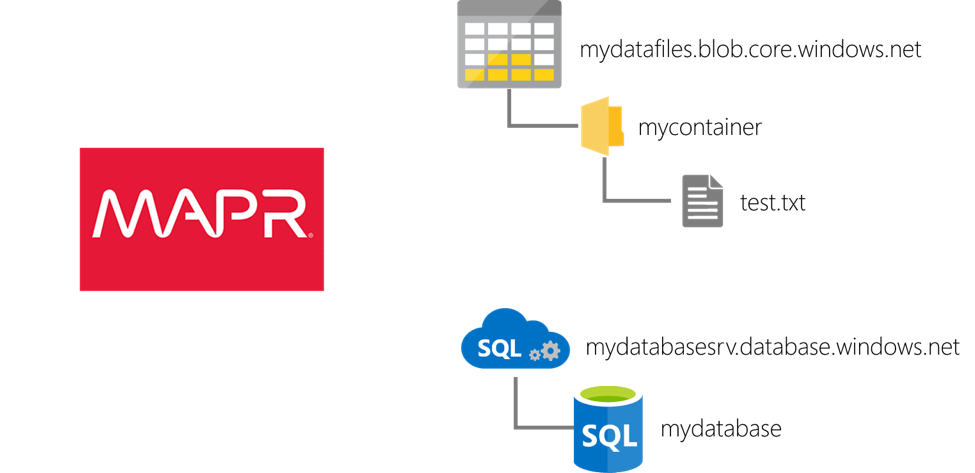
The first asset I will tap into is an Azure Storage account. An Azure Storage account is a logical container for the storage of a variety of data assets. For this demonstration, I will store files in the block blob portion of the account. Block blobs are the cheapest storage option in Azure Storage and are ideal when you wish to read whole files (as opposed to performing random reads on a file which is supported by the page blob type).
Azure Storage accounts are identified by a unique name: mydatafiles in this environment. The block blob portion of the account is therefore addressable as mydatafiles.blob.core.windows.net. Blobs are housed in containers: mycontainer in this environment. And into that container, I’ve uploaded a single, tab-delimited file named test.txt. (If you are creating an environment of your own, your storage account will require a different name, but you can use the same container and file names.)
The second asset to which I will connect is an Azure SQL Database. An Azure SQL Database is a Microsoft SQL Server (relational) database run in the cloud in a manner that eliminates most of the administrative overhead of a typical database. It also has many other benefits, making it a very popular choice for structured data storage in the Azure cloud.
My Azure SQL database is named mydatabase. I haven’t created any objects within it but will simply query some pre-existing tables in its catalog to demonstrate connectivity. This database is deployed within the context of a logical server which provides the database with an address: mydatabasesrv.database.windows.net in my environment. I’ve left the firewall on the server at its default settings so that the only traffic to which the database will respond will be traffic originating within the Azure cloud. (As before, if you are creating an environment of your own, your server will require a different name, but you can use the same database name.)
Connecting to Azure Storage
With the test environment in place, I will first connect Drill to my Azure Storage account. To do this, I will first SSH into node 0 of my cluster using the SysAdmin user name (mapradmin by default) and password (or certificate) created during cluster deployment.
NOTE For this sequence of steps, it is important that you perform these operations from node 0.
Once logged in, I now need to download two drivers, i.e., the hadoop-azure and azure-storage drivers, to the /opt/mapr/drill/drill-1.6.0/jars/3rdparty/ directory on each node of my cluster. To assist with this, I’ll make use of the clustershell utility (clush) pre-installed on the MapR cluster with the -a option which launches the double-quote enclosed commands to run on all nodes in the cluster:
sudo clush -a "wget http://central.maven.org/maven2/org/apache/hadoop/hadoop-azure/2.7.3/had..." sudo clush -a "wget http://central.maven.org/maven2/com/microsoft/azure/azure-storage/4.4.0/..." sudo clush -a "mv *azure*.jar /opt/mapr/drill/drill-1.6.0/jars/3rdparty/"
With the drivers in place, I now need to configure Drill with the key used by the Azure Storage account to control access to its contents. I do this by adding the following block under the configuration node of the core-site.xml file located in /opt/mapr/drill/drill-1.6.0/conf/, substituting the name of my Azure Storage account and its key:
<property> <name>fs.azure.account.key.mydatafiles.blob.core.windows.net</name> <value>DrIhQUaOMvoydL0/+DcOuuWq8nj9TbwlLbFV4MIR7YdB1PihKQ==</value> </property>
At this point, the changes to the core-site.xml file have only been made on node 0, the node of the cluster into which I am logged in. To replicate these changes to the remaining nodes of my cluster, I can use the clustershell utility again, this time using the -w option to control on which nodes of the cluster to perform the prescribed operation:
sudo clush -w maprclusternode[1-2] -c /opt/mapr/drill/drill-1.6.0/conf/core-site.xml --dest /opt/mapr/drill/drill-1.6.0/conf/
Please note that I have deployed a three-node cluster. Clustershell is configured to recognize these nodes as maprclusternode0, maprclusternode1, and maprclusternode2. Having made changes to the core-site.xml file on maprclusternode0, clush only needs to operate against maprclusternode[1-2]. If you have a different number of nodes in your cluster, you will need to modify the value assigned to the -w option. Also, in this instance of the clustershell command, I have instructed clush to use SCP, i.e., -c option, to copy the local copy of core-site.xml to the appropriate destination on the target servers.
NOTE If you run into a problem with the next set of steps, try restarting the Drill service using the MapR Dashboard (accessible via HTTPS on TCP port 8443).
With all the driver components in place, I can now create a storage plugin within Drill to target my Azure Storage account. To do this, I log in to the Drill Console as described in the previous post and navigate to the Storage page.
The configuration of the plugin I will create will very closely mirror that of the default dfs plugin. So before creating the new plugin, I click the Update button next to the dfs plugin, copy its configuration information, and click the Back button to return to the Storage page.
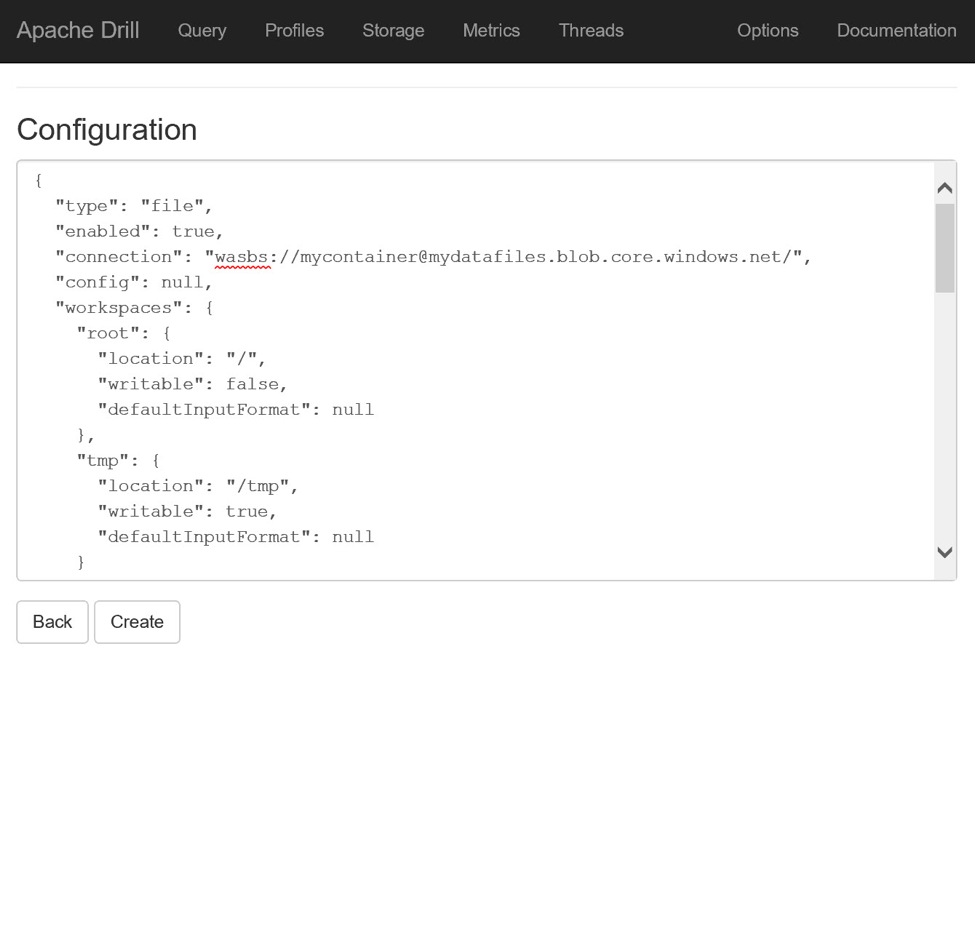
With the configuration information for the dfs plugin in hand, locate the New Storage Plugin section at the bottom of the Storage page, enter a name for the new plugin, e.g., mydatafiles, and click the Create button. In the resulting Configuration page, delete the null keyword and replace it with the copied configuration information. Locate the connection key within the configuration JSON and replace its value with wasbs://mycontainer@mydatafiles.blob.core.windows.net/, making appropriate substitutions for the Azure Storage account and container names. (The wasbs:// protocol instructs Drill to use the drivers previously loaded and to have them communicate with the Storage account using HTTPS.)
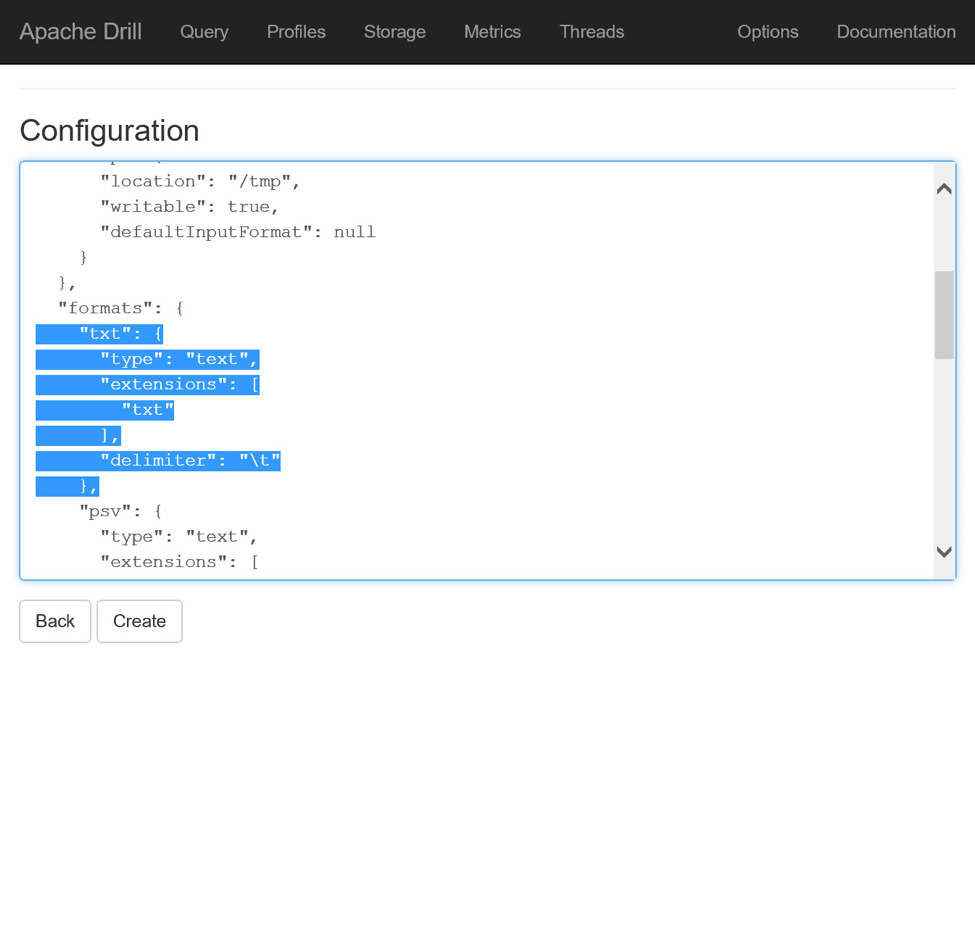
Before leaving this page, scroll through the configuration information until you find the formats key. This key contains a number of child key-value pairs that instruct Drill on how to interpret files in particular formats. Add the following key under formats, telling Drill to interpret files with txt extensions as tab-delimited text:
Click the Create button to create the Storage plugin. You should see a banner message indicating success. Once you see that, click Back to return to the Storage page. You should now see your plugin listed under the Enabled Storage Plugins section of the page.
With the drivers in place and the plugin configured, you can how query the Azure Storage account. Navigate to the Query page of the Drill Console and submit the following SQL query to see a listing of the files in the storage account:
SHOW FILES FROM `mydatafiles`;
NOTE The name of the plugin in this query is wrapped in back ticks, properly known as grave accents.
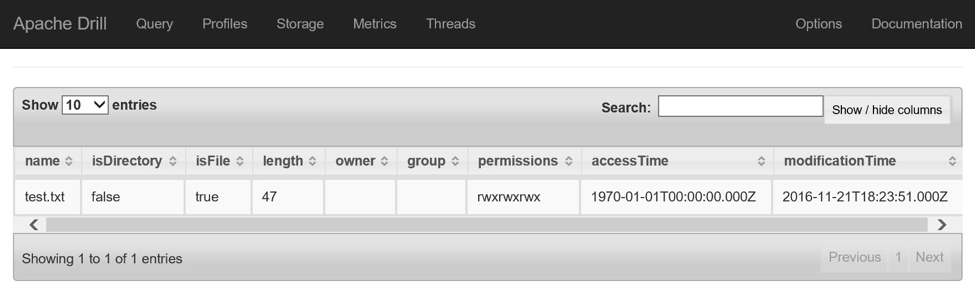
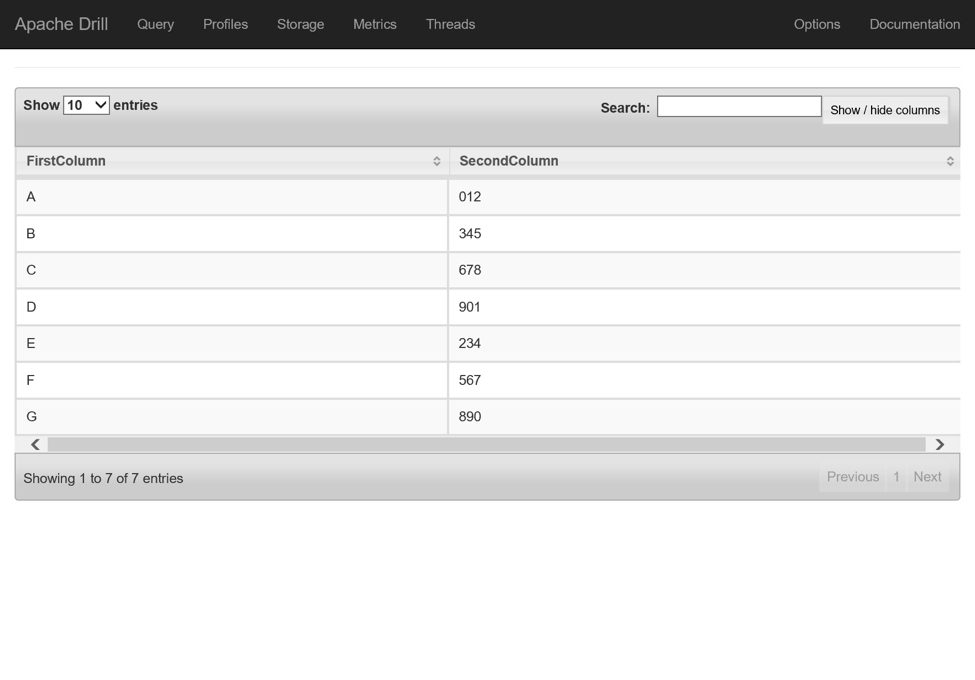
To query the test.txt file loaded into the Storage account, enter a query as follows:
SELECT columns[0] as FirstColumn, columns[1] as SecondColumn FROM mydatafiles.`test.txt`
NOTE In this query, the file name is wrapped in back ticks but the plugin’s name does not require it. For more information on querying text files, check out this document.
Connecting to an Azure SQL Database
The steps for connecting Drill to an Azure SQL Database are a bit simpler than those performed with an Azure Storage account. To get started, I’ll SSH to the node 0 and download the latest SQL Server JDBC drivers to each of the nodes in the cluster using clustershell:
sudo clush -a "wget https://download.microsoft.com/download/0/2/A/02AAE597-3865-456C-AE7F-61..." sudo clush -a "tar -xzvf sqljdbc_6.0.7728.199_enu.tar.gz" sudo clush -a "mv sqljdbc_6.0/enu/sqljdbc*.jar /opt/mapr/drill/drill-1.6.0/jars/3rdparty/" sudo clush -a "rm -r sqljdbc*"
Next, I’ll open the Drill Console, navigate to the Storage page, and create a new plugin with the following configuration (using the appropriate substitutions for the server name, database name, user name and password):
{
"type": "jdbc",
"driver": "com.microsoft.sqlserver.jdbc.SQLServerDriver",
"url": "jdbc:sqlserver://mydatabasesrv.database.windows.net:1433;databaseName=mydatabase",
"username": "myusername",
"password": "mypassword",
"enabled": true
}Once created (with a name of mydatabase), I can test connectivity with a simple query:
SELECT * FROM mydatabase.sys.objects;
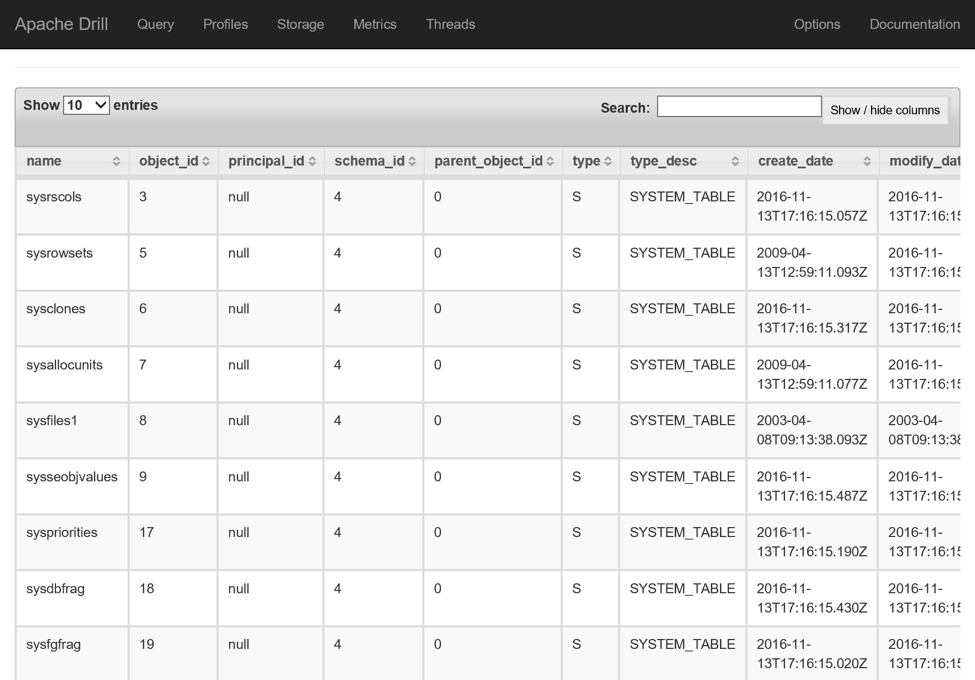
In this post, you’ve learned how to use the Drill-enabled cluster to query an Azure Storage account as well as an Azure SQL Database. In the next post, we’ll review how to use this cluster as a data source with Microsoft Power BI.
| Reference: | Connecting a Drill-enabled MapR Cluster to Azure Resources (Part 2) from our JCG partner Bryan Smith at the Mapr blog. |
