Achieving Sub Second SQL JOINs and building a data warehouse using Spark, Cassandra, and FiloDB
Evan loves to design, build, and improve bleeding edge distributed data and backend systems using the latest in open source technologies. He is the creator of the FiloDB open-source distributed analytical database, as well as the Spark Job Server. He has led the design and implementation of multiple big data platforms based on Storm, Spark, Kafka, Cassandra, and Scala/Akka, including a columnar real-time distributed query engine. He is an active contributor to the Apache Spark project, and a Datastax Cassandra MVP. He has built Spark applications since Spark 0.8, Cassandra since 0.6. He is a big believer in GitHub, open source, and meetups, and have given talks at various conferences including Strata, Spark Summit, Cassandra Summit, FOSS4G, and Scala Days. He has a Bachelors and Masters of Electrical Engineering, with distinction, from Stanford University.
This article dives into how Spark SQL does multi-table JOINs and how we achieved really fast JOINs using Datastax DSE (Spark and Cassandra), and FiloDB.
Background
At Tuplejump, we help different enterprises build modern big data platforms based on the latest technologies. One of our clients is Element Financial Services, a leading fleet management and equipment finance company. They have picked Datastax Enterprise as a go-to platform for replacing their data warehouse and powering their next analytics and BI platform. Datastax Enterprise provides a stable, easy to setup Cassandra installation with Apache Spark support built-in, enterprise features, and professional support from Datastax.
What makes the adoption of Datastax Enterprise, Cassandra, and Spark challenging for building a data warehousing and BI platform? First, the platform is expected to meet current SLAs for reporting and ad-hoc analytics through existing BI tools. Cassandra is a rock-solid distributed database, but it is more designed for thousands of concurrent, small reads and writes, and not so much for traditional analytics workloads which involve scanning millions of records. The variety and ad-hoc nature of the queries prevented widespread use of pre-aggregation. Meeting the expectations would require pushing the platform to its limits and innovating. Second, due to both existing queries, reports, and usage patterns, the normal Cassandra data modeling technique of denormalizing all tables was not possible. Slowing changing dimension tables and other business requirements means that JOINs are preferable compared to increasing ETL complexity by an order of magnitude. JOINs are not yet very efficient in Apache Spark, though they are improving with every release. Thus, we set our goals on being able to execute JOIN queries on Datastax Enterprise in under 5 seconds, with some concurrency.
The Plan
We started by modeling fact and dimension tables such that the majority of queries could be expressed as single-partition queries. To be more specific, given partition keys A, B, and C, the fastest queries happen when they query data with a WHERE clause looking like WHERE A = val1 AND B = val2 AND C = val3. These predicates result in an exact match for one Cassandra partition, and the Spark-Cassandra connector is able to reduce the query to a single Spark partition / thread, and query just one Cassandra node. (This is often referred to as predicate pushdown) Queries with other predicate combinations resulted in either multi-partition queries or whole table scans, which would take minutes. Modeling our tables in this way maximizes Cassandra’s advantage of fine-grained partitioning and filtering.
The next step is join optimization. Let’s say you have this query:
SELECT t1.col1, t2.col2 FROM small_table t1, big_table t2 WHERE t2.a = t1.a AND t1.a = 'XYZ'
Let’s say that column a is the partition key for both tables t1 and t2. Thus, Cassandra will get the predicate pushdown for reading from a single partition for table t1 (t1.a = ‘XYZ’), but initiate a full-table scan on t2, due to having no filter on t2.a. This would be really slow. One option is to force users to specify an additional predicate by hand, such that you have this query:
SELECT t1.col1, t2.col2 FROM small_table t1, big_table t2 WHERE t2.a = t1.a AND (t1.a = 'XYZ' AND t2.a = 'XYZ')
This query is better as you have partition key predicate pushdown for both tables t1 and t2. Rather than needing to change user behavior and/or change the way that BI tools are used, however, we invested into writing a custom Spark Hive Thrift Server that can intercept the SQL queries, analyze them, and transform the logical plan to automatically augment JOIN predicates. (How to do that should be the topic of another entire post) The custom server also gives us an opportunity for other custom plan transformations, such as picking the most optimal Cassandra table to answer a given query and substituting that table in the query plan. We are in the process of contributing some of these optimizations back to Spark via SPARK-13219.
Finally, in order to achieve the concurrency needed, we ran the Hive Thrift Server and any other Spark apps using FAIR scheduler mode spark.scheduler.mode=FAIR. We have observed that on a cluster, even for large Cassandra scan jobs taking up all threads, that Spark is able to schedule concurrent jobs running within the same app.
Use all Cassandra Tables
Here is the DAG and event timeline visualization from the Spark UI of running a 4-table JOIN reporting query on a small DSE 4.8 cluster. The nontrivial query consists of selecting 29 columns from 4 tables, 3 join columns, and 27 grouping columns. The partitions in the largest tables contain many thousands of rows each.

Spark’s DAG Visualization is a great tool to show the different stages, how they are related, and what operations take place in each stage. You can see that there are two different kinds of stages here – 7, 8, 9, and 12 consists mostly of MapPartitions and Filter, and have no dependencies on other stages. These are the stages that read data from Cassandra tables in parallel (MapPartitions) and filter them. Stages 10, 11, and 13 are the Join stages (ShuffleHashJoin), and the lines indicate how Spark executes a 4-table join: first the data from 7 and 8 are joined in stage 10; then the results of 10 and the data from 9 are joined; and so forth.
From looking at the event timeline, you can draw several conclusions:
* The total query time is approx. 6 seconds.
* The four read stages are happening in parallel, one in each thread, thanks to the single partition predicate pushdown. Yay!
* The reads occupy most of the query time. The shuffle stages are the tiny ones at the end that depend on the read stages; they take up perhaps 1/4 second.
* The query is bottlenecked on the reads for two of the tables, which takes approx. 5 seconds each. These are the reads containing the most data. Thus, shuffles are not the bottleneck.
Overall, the plan worked fairly well. Using good data modeling with partition key pushdowns enabled reads to be parallelized, yet contained to one thread per table. Can we do better and improve on those long reads?
Use mixed Cassandra + FiloDB Tables
We decided to store data from the two largest tables (one a fact table, one a large dimension table) into FiloDB, which stores data into Cassandra in a columnar format optimized for fast analytical/OLAP queries. FiloDB has a data model similar to Cassandra’s, meaning we can utilize the same strategy of single-partition lookups to effectively filter queries. When the two large Cassandra tables are substituted for FiloDB tables, here are the results:
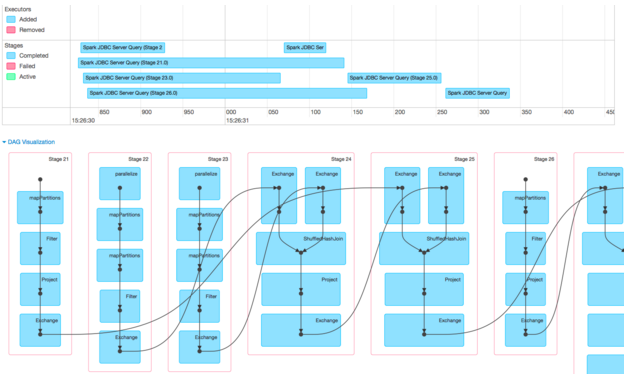
We’ll focus on the event timeline, since the DAG is the same except for the stage numbers. Note that the timeline scale is now in Milliseconds, and the entire 4-table JOIN query finishes in just over half a second! What enabled this speedup is the use of FiloDB, which reduced the previous 5 second reads to under 250ms each. (The FiloDB stages are 22 and 23, the ones with the “parallelize” at the top of each stage, as the FiloDB data source uses sc.parallelize / sc.makeRDD, while the Spark Cassandra Connector has a custom RDD class).
By using FiloDB to store the largest tables, we were able to achieve sub-second JOIN times for a nontrivial query spanning four tables and meet desired SLAs. At the same time, the solution still fits within the Datastax Enterprise / Spark / Cassandra stack, simplifying operations and maintenance for a lower TCO.
Where to go from here
You’ve hopefully seen the strategies and technologies that, when put together, can accelerate real world JOIN queries on Spark and Cassandra – even 4-table JOINs can run sub-second!
For more information on FiloDB, come and check out our O’Reilly Webcast, or feel free to check out the Github project. For more information on Datastax Enterprise, please visit the landing page.
If you are interested in working on leading edge big data technologies such as Spark, Cassandra, and FiloDB, consider joining our effort at Element and Tuplejump!
| Reference: | Achieving Sub Second SQL JOINs and building a data warehouse using Spark, Cassandra, and FiloDB from our JCG partner Evan Chan at the Planet Cassandra blog. |
