I’ve recently encountered a very interesting question on Stack Overflow by an unnamed user. The question was about generating a table of the following form in Oracle, using a table valued function:
Description COUNT ------------------- TEST1 10 TEST2 15 TEST3 25 TEST4 50
The logic that should be implemented for the COUNT column is the following:
- TEST1: count of employees whose sal < 10000
- TEST2: count of employees whose dept > 10
- TEST3: count of employees whose hiredate > (SYSDATE-60)
- TEST4: count of employees whose grade = 1
Challenge accepted!
For this exercise, let’s assume the following table:
CREATE TABLE employees (
id NUMBER(18) NOT NULL PRIMARY KEY,
sal NUMBER(18, 2) NOT NULL,
dept NUMBER(18) NOT NULL,
hiredate DATE NOT NULL,
grade NUMBER(18) NOT NULL
);
INSERT INTO employees
VALUES (1, 10000, 1, SYSDATE , 1);
INSERT INTO employees
VALUES (2, 9000, 5, SYSDATE - 10, 1);
INSERT INTO employees
VALUES (3, 11000, 13, SYSDATE - 30, 2);
INSERT INTO employees
VALUES (4, 10000, 12, SYSDATE - 80, 2);
INSERT INTO employees
VALUES (5, 8000, 7, SYSDATE - 90, 1);How to calculate the COUNT values
In a first step, we’re going to look into how to best calculate the COUNT values. The simplest way is to calculate the values in individual columns, not rows. SQL newbies will probably resort to a canonical solution using nested SELECTs, which is very bad for performance reasons:
SELECT
(SELECT COUNT(*) FROM employees
WHERE sal < 10000) AS test1,
(SELECT COUNT(*) FROM employees
WHERE dept > 10) AS test2,
(SELECT COUNT(*) FROM employees
WHERE hiredate > (SYSDATE - 60)) AS test3,
(SELECT COUNT(*) FROM employees
WHERE grade = 1) AS test4
FROM dual;Why is the query not optimal? There are four table accesses to find all the data:
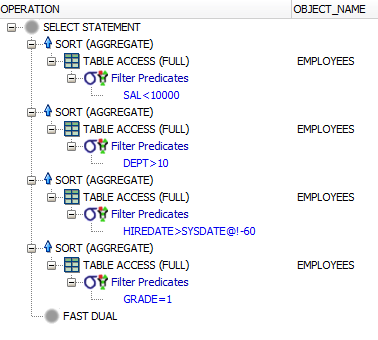
If you add an index to each individual column being filtered, chances are at least to optimise individual subqueries, but for these kinds of reports, the occasional full table scan is perfectly fine, especially if you aggregate a lot of data.
Even if not optimal in speed, the above yields the correct result:
TEST1 TEST2 TEST3 TEST4 ----------------------------- 2 2 3 3
How to improve the query, then?
Few people are aware of the fact that aggregate functions only aggregate non-NULL values. This has no effect, when you write COUNT(*), but when you pass an expression to the COUNT(expr) function, this becomes much more interesting!
The idea here is that you use a CASE expression that transforms each predicate’s TRUE evaluation into a non-NULL value, an the FALSE (or NULL) evaluation into NULL. The following query illustrates this approach
SELECT
COUNT(CASE WHEN sal < 10000 THEN 1 END)
AS test1,
COUNT(CASE WHEN dept > 10 THEN 1 END)
AS test2,
COUNT(CASE WHEN hiredate > (SYSDATE-60) THEN 1 END)
AS test3,
COUNT(CASE WHEN grade = 1 THEN 1 END)
AS test4
FROM employees;… and yields again the correct result:
TEST1 TEST2 TEST3 TEST4 ----------------------------- 2 2 3 3
Using FILTER() instead of CASE
The SQL standard and the awesome PostgreSQL database offer an even more convenient syntax for the above functionality. The little known FILTER() clause on aggregate functions.
In PostgreSQL, you’d write instead:
SELECT
COUNT(*) FILTER (WHERE sal < 10000)
AS test1,
COUNT(*) FILTER (WHERE dept > 10)
AS test2,
COUNT(*) FILTER (WHERE hiredate > (SYSDATE - 60))
AS test3,
COUNT(*) FILTER (WHERE grade = 1)
AS test4
FROM employees;This is useful when you want to cleanly separate the FILTER() criteria from any other expression that you want to use for aggregating. E.g. when calculating a SUM().
In any case, the query now has to hit the table only once. The aggregation can then be performed entirely in memory.
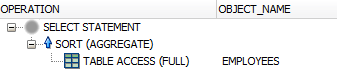
This is always better than the previous approach, unless you have an index for every aggregation!
OK. Now how to get the results in rows?
The question on Stack Overflow wanted a result with TESTn values being put in individual rows, not columns.
Description COUNT ------------------- TEST1 2 TEST2 2 TEST3 3 TEST4 3
Again, there’s a canonical, not so performant approach to do this with UNION ALL:
SELECT 'TEST1' AS Description, COUNT(*) AS COUNT FROM employees WHERE sal < 10000 UNION ALL SELECT 'TEST2', COUNT(*) FROM employees WHERE dept > 10 UNION ALL SELECT 'TEST3', COUNT(*) FROM employees WHERE hiredate > (SYSDATE - 60) UNION ALL SELECT 'TEST4', COUNT(*) FROM employees WHERE grade = 1
This approach is more or less equivalent to the nested selects approach, except for the column / row transposition (“unpivoting”). And the plan is also very similar:
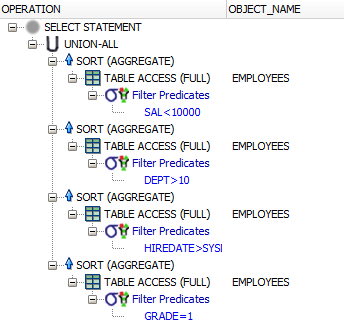
Transposition = (un)pivoting
Notice how I used the term “transpose”. That’s what we did, and it has a name: (un)pivoting. Not only does it have a name, but this feature is also supported out of the box in Oracle and SQL Server via the PIVOT and UNPIVOT keywords that can be placed after table references.
PIVOTtransposes rows into columnsUNPIVOTtransposes columns back into rows
So, we’ll take the original, optimal solution, and transpose that with UNPIVOT
SELECT *
FROM (
SELECT
COUNT(CASE WHEN sal < 10000 THEN 1 END)
AS test1,
COUNT(CASE WHEN dept > 10 THEN 1 END)
AS test2,
COUNT(CASE WHEN hiredate > (SYSDATE-60) THEN 1 END)
AS test3,
COUNT(CASE WHEN grade = 1 THEN 1 END)
AS test4
FROM employees
) t
UNPIVOT (
count FOR description IN (
"TEST1", "TEST2", "TEST3", "TEST4"
)
)All we need to do is wrap the original query in a derived table t (i.e. an inline SELECT in the FROM clause), and then “UNPIVOT” that table t, generating the count and description columns. The result is, again:
Description COUNT ------------------- TEST1 2 TEST2 2 TEST3 3 TEST4 3
The execution plan is still optimal. All the action is happening in memory.
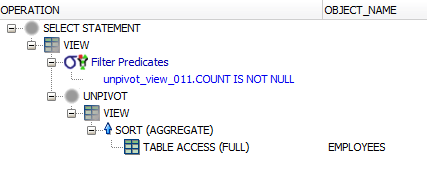
Conclusion
PIVOT and UNPIVOT are very useful tools for reporting and reorganising data. There are many use-cases like the above, where you want to re-organise some aggregations. Other use-cases include settings or properties tables that implement an entity attribute value model, and you want to transform attributes from rows to columns (PIVOT), or from columns to rows (UNPIVOT)
Intrigued? Read on about PIVOT here:
- Are You Using SQL PIVOT Yet? You Should!
- How to use SQL PIVOT to Compare Two Tables in Your Database
- The Awesome PostgreSQL 9.4 / SQL:2003 FILTER Clause for Aggregate Functions
| Reference: | Impress Your Coworkers by Using SQL UNPIVOT! from our JCG partner Lukas Eder at the JAVA, SQL, AND JOOQ blog. |
