While experimenting with some time series collections I needed a large data set to check that our aggregation queries don’t become a bottleneck in case of increasing data loads. We settled for 50 million documents, since beyond this number we would consider sharding anyway.
Each time event looks like this:
{
"_id" : ObjectId("5298a5a03b3f4220588fe57c"),
"created_on" : ISODate("2012-04-22T01:09:53Z"),
"value" : 0.1647851116706831
}As we wanted to get random values, we thought of generating them using JavaScript or Python (we could have tried in in Java, but we wanted to write it as fast as possible). We didn’t know which one will be faster so we decided to test them.
Our first try was with a JavaScript file run through the MongoDB shell.
Here is how it looks like:
var minDate = new Date(2012, 0, 1, 0, 0, 0, 0);
var maxDate = new Date(2013, 0, 1, 0, 0, 0, 0);
var delta = maxDate.getTime() - minDate.getTime();
var job_id = arg2;
var documentNumber = arg1;
var batchNumber = 5 * 1000;
var job_name = 'Job#' + job_id
var start = new Date();
var batchDocuments = new Array();
var index = 0;
while(index < documentNumber) {
var date = new Date(minDate.getTime() + Math.random() * delta);
var value = Math.random();
var document = {
created_on : date,
value : value
};
batchDocuments[index % batchNumber] = document;
if((index + 1) % batchNumber == 0) {
db.randomData.insert(batchDocuments);
}
index++;
if(index % 100000 == 0) {
print(job_name + ' inserted ' + index + ' documents.');
}
}
print(job_name + ' inserted ' + documentNumber + ' in ' + (new Date() - start)/1000.0 + 's');This is how we run it and what we got:
mongo random --eval "var arg1=50000000;arg2=1" create_random.js Job#1 inserted 100000 documents. Job#1 inserted 200000 documents. Job#1 inserted 300000 documents. ... Job#1 inserted 49900000 documents. Job#1 inserted 50000000 in 566.294s
Well, this is beyond my wild expectations already (88293 inserts/second).
Now it’s Python’s turn. You will need to install pymongo to properly run it.
import sys
import os
import pymongo
import time
import random
from datetime import datetime
min_date = datetime(2012, 1, 1)
max_date = datetime(2013, 1, 1)
delta = (max_date - min_date).total_seconds()
job_id = '1'
if len(sys.argv) < 2:
sys.exit("You must supply the item_number argument")
elif len(sys.argv) > 2:
job_id = sys.argv[2]
documents_number = int(sys.argv[1])
batch_number = 5 * 1000;
job_name = 'Job#' + job_id
start = datetime.now();
# obtain a mongo connection
connection = pymongo.Connection("mongodb://localhost", safe=True)
# obtain a handle to the random database
db = connection.random
collection = db.randomData
batch_documents = [i for i in range(batch_number)];
for index in range(documents_number):
try:
date = datetime.fromtimestamp(time.mktime(min_date.timetuple()) + int(round(random.random() * delta)))
value = random.random()
document = {
'created_on' : date,
'value' : value,
}
batch_documents[index % batch_number] = document
if (index + 1) % batch_number == 0:
collection.insert(batch_documents)
index += 1;
if index % 100000 == 0:
print job_name, ' inserted ', index, ' documents.'
except:
print 'Unexpected error:', sys.exc_info()[0], ', for index ', index
raise
print job_name, ' inserted ', documents_number, ' in ', (datetime.now() - start).total_seconds(), 's'We run it and this is what we got this time:
python create_random.py 50000000 Job#1 inserted 100000 documents. Job#1 inserted 200000 documents. Job#1 inserted 300000 documents. ... Job#1 inserted 49900000 documents. Job#1 inserted 50000000 in 1713.501 s
This is slower compared to the JavaScript version (29180 inserts/second), but lets not get discouraged. Python is a full-featured programming language, so how about taking advantage of all our CPU cores (e.g. 4 cores) and start one script per core, each one inserting a fraction of the total documents number (e.g. 12500000).
import sys
import pymongo
import time
import subprocess
import multiprocessing
from datetime import datetime
cpu_count = multiprocessing.cpu_count()
# obtain a mongo connection
connection = pymongo.Connection('mongodb://localhost', safe=True)
# obtain a handle to the random database
db = connection.random
collection = db.randomData
total_documents_count = 50 * 1000 * 1000;
inserted_documents_count = 0
sleep_seconds = 1
sleep_count = 0
for i in range(cpu_count):
documents_number = str(total_documents_count/cpu_count)
print documents_number
subprocess.Popen(['python', '../create_random.py', documents_number, str(i)])
start = datetime.now();
while (inserted_documents_count < total_documents_count) is True:
inserted_documents_count = collection.count()
if (sleep_count > 0 and sleep_count % 60 == 0):
print 'Inserted ', inserted_documents_count, ' documents.'
if (inserted_documents_count < total_documents_count):
sleep_count += 1
time.sleep(sleep_seconds)
print 'Inserting ', total_documents_count, ' took ', (datetime.now() - start).total_seconds(), 's'Running the parallel execution Python script goes like this:
python create_random_parallel.py Job#3 inserted 100000 documents. Job#2 inserted 100000 documents. Job#0 inserted 100000 documents. Job#1 inserted 100000 documents. Job#3 inserted 200000 documents. ... Job#2 inserted 12500000 in 571.819 s Job#0 inserted 12400000 documents. Job#3 inserted 10800000 documents. Job#1 inserted 12400000 documents. Job#0 inserted 12500000 documents. Job#0 inserted 12500000 in 577.061 s Job#3 inserted 10900000 documents. Job#1 inserted 12500000 documents. Job#1 inserted 12500000 in 578.427 s Job#3 inserted 11000000 documents. ... Job#3 inserted 12500000 in 623.999 s Inserting 50000000 took 624.655 s
This is very good indeed (80044 inserts/seconds) even if still slower than the first JavaScript import. So lets adapt this last Python script to run the JavaScript through multiple MongoDB shells.
Since I couldn’t supply the required arguments to the mongo command, to the sub-process started by the main python script, I came up with the following alternative:
for i in range(cpu_count):
documents_number = str(total_documents_count/cpu_count)
script_name = 'create_random_' + str(i + 1) + '.bat'
script_file = open(script_name, 'w')
script_file.write('mongo random --eval "var arg1=' + documents_number +';arg2=' + str(i + 1) +'" ../create_random.js');
script_file.close()
subprocess.Popen(script_name)We generate shell scripts dynamically and let python run them for us.
Job#1 inserted 100000 documents. Job#4 inserted 100000 documents. Job#3 inserted 100000 documents. Job#2 inserted 100000 documents. Job#1 inserted 200000 documents. ... Job#4 inserted 12500000 in 566.438s Job#3 inserted 12300000 documents. Job#2 inserted 10800000 documents. Job#1 inserted 11600000 documents. Job#3 inserted 12400000 documents. Job#1 inserted 11700000 documents. Job#2 inserted 10900000 documents. Job#1 inserted 11800000 documents. Job#3 inserted 12500000 documents. Job#3 inserted 12500000 in 574.782s Job#2 inserted 11000000 documents. Job#1 inserted 11900000 documents. Job#2 inserted 11100000 documents. Job#1 inserted 12000000 documents. Job#2 inserted 11200000 documents. Job#1 inserted 12100000 documents. Job#2 inserted 11300000 documents. Job#1 inserted 12200000 documents. Job#2 inserted 11400000 documents. Job#1 inserted 12300000 documents. Job#2 inserted 11500000 documents. Job#1 inserted 12400000 documents. Job#2 inserted 11600000 documents. Job#1 inserted 12500000 documents. Job#1 inserted 12500000 in 591.073s Job#2 inserted 11700000 documents. ... Job#2 inserted 12500000 in 599.005s Inserting 50000000 took 599.253 s
This is fast too (83437 inserts/second) but still can’t beat our first attempt.
Conclusion
My PC configuration is nothing out of the ordinary, and the only optimization is that I have a SSD drive on which MongoDB runs.
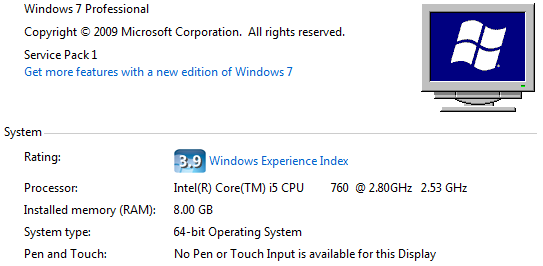
The first attempt yielded the best results, and monitoring CPU resources I realized MongoDB leverages all of them even for a single shell console. The Python script running on all cores was also fast enough and it has the advantage of allowing us to turn this script into a fully operational application, if we want to.
- Code available on GitHub.

Does not surprise me one bit. You can also optimize your schema a little bit by using shorter column names – it will save you memory when you have millions of records. I would use
{
“_id” : ObjectId(“5298a5a03b3f4220588fe57c”),
“c” : ISODate(“2012-04-22T01:09:53Z”),
“v” : 0.1647851116706831
}
It wont make much difference to inserts but will help with querying, indexes etc
Hi Dharshan,
Thanks for the tip, I remember I saw a presentation held by someone from Foursquare saying that they’re also using very short column names and a custom-made open-source Scala framework for always querying on an index.
Vlad