Our code has been broken for weeks. Compiler errors, failing tests, incorrect behavior plagued our team. Why? Because we have been struck by a Blind Frog Leap. By doing multiple concurrent changes to a key component in the hope of improving it, we have leaped far away from its ugly but stable and working state into the marshes of brokenness. Our best intentions have brought havoc upon us, something expected to be a few man-days work has paralized us for over a month until the changes were finally reverted (for the time being).
Lessons learned: Avoid Frog Leaps. Follow instead Kent Beck’s strategy of Sprinting Centipede – proceed in small, safe steps, that don’t break the code. Deploy it to production often, preferably daily, to force yourself to really small and really safe changes. Do not change multiple unrelated things at the same time. Don’t assume that you know how the code works. Don’t assume that your intended change is a simple one. Test thoroughly (and don’t trust your test suite overly). Let the computer give you feedback and hard facts about your changes – by running tests, by executing the code, by running the code in production.
What happened? We have batch jobs whose configuration properties may be set via (1) command-line arguments or (2) job-specific or (3) shared entries in a file. The jobs used to access it via the static call Configuration.get('my.property'). Since a global, automatically loaded configuration makes it impossible to unit-test the jobs with different configurations, we wanted to replace the singleton with instances of configuration passed around. I will describe briefly our failed refactoring, propose a better way to do it, and discuss how to evolve and refactor software without such failures.
The path to marshes
We have tried to produce this:
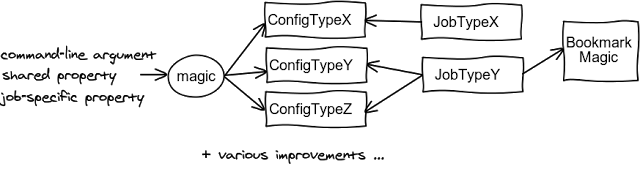
We have started by replacing the static Configuration with three instantiable classes, each having only a single responsability (SRP). Then we have modified each job to accept/create the one it needed. We have also renamed some command-line arguments and properties to something more understandable and made various small improvements. Finally, we have replaced the (mis)use of the configuration system for storing information about where the jobs have finished their work the last time (“bookmarks”) with something better. As a side-effect, there were also some other changes, for example the default configuration was no more loaded from a location on the classpath but from a relative file system path and the command-line arguments were processed little differently. All but one tests were passing and all looked well. It has been more complicated (a change required other changes, the original design was too simplistic, etc.) and thus took longer than expected but we have finally managed it.
However when we have tried to run the application, it didn’t work. It couldn’t find its configuration file (for it hasn’t been looked up on the classpath anymore), some properties that used to respect job-specific values didn’t do so anymore and we have unknowingly introduced some inconsistencies and defects. It has proven to be too difficult to find out how the individual configuration properties interacted and ensuring that all the sources of configuration – command-line arguments, shared and job-specific properties – were respected in the right order and at all places where necessary. Our attempts at fixing it took long and were futile. (Fixing broken legacy codebase which you haven’t understood in the first place is never easy.)
Even if we managed to fix all the problems, another one would have remained. The changes weren’t backwards compatible. To be able to deploy them to the production, we would need to stop everything, update (correctly) all the configuration and our cron jobs. A potential for many mistakes.
A better way?
Does it mean that improving software is too risky to pay off? No if we are more careful, proceed in small, safe, verified steps and minimize or avoid disruptive changes. Let’s see how we could have proceeded if we followed these principles.

As the first step (see Fig. 2), we could have left nearly everything as it was, only introduce a temporary ConfigurationInstance1 class with the same API (to make drop-in replacement easier) as Configuration but non-static and modify Configuration to forward all calls to its own (singleton) instance2 of ConfigurationInstance. A small, easy, safe change. We could then modify our jobs, one by one, to use a ConfigurationInstance obtained via Configuration.getInstance() by default and also alternatively accept an instance of it upon creation. (Notice that anytime during this process we could – and should – deploy to production.)
The code would look like this:
class Configuration {
private static ConfigurationInstance instance = new ConfigurationInstance();
public static ConfigurationInstance getInstance() { return instance; }
public static void setTestInstance(ConfigurationInstance config) { instance = config; } // for tests only
public static String get(String property) { instance.get(property); }
}
class ConfigurationInstance {
...
public String get(String property) { /** some code ... */ }
}
class MyUpdatedJob {
private ConfigurationInstance config;
/** The new constructor */
MyUpdatedJob(ConfigurationInstance config) { this.config = config; }
/** @deprecated The old constructor kept for now for backwards-compatibility */
MyUpdatedJob() { this.config = Configuration.getInstance(); }
doTheJob() { ... config.get('my.property.xy') ... }
}
class OldNotUpdatedJob {
doTheJob() { ... Configuration.get('my.property.xy') /* not updated yet, not testable */ ... }
}Once this is finished for all jobs, we could change the instantiation of jobs to pass in the ConfigurationInstance. Next we could remove all the remaining references to Configuration, delete it, and perhaps rename ConfigurationInstance to Configuration. We could regularly deploy to our test/staging environment and eventually to production to make sure that everything still works (which it should for the changes are minimal).
Next, as a separate and independent change, we could factor out and change the storage of “bookmarks.” Other improvements – such as renaming configuration properties – should also be done later and independently. (Not surprisingly the more changes you do, the higher risk of something being wrong.)
We could/should also introduce code for automatic migration from the old configuration to the new one – for example to read bookmarks in the old format if the new doesn’t exist and store them in the new one. For properties we could add code that checks for both the old and the new name (and warns if the old one is still used). Thus deploying the changes would not require us to synchronize with configuration and execution changes.
——
1) Notice that Java doesn’t allow us to have both static and non-static method of the same name so we would need either to create instance methods in Configuration with different names or, as we did, create another class. We want to keep the same names to make migration from the static to the instance configuration a matter of a simple and safe search and replace (“Configuration.” with “configuration.” after having added the field configuration to the target class.) “ConfigurationInstance” is admittedly an ugly name but easy and safe to change later.
2) A variation of the Introduce Instance Delegator refactoring described in Michael Feathers’ seminal book Working Effectively with Legacy Code
Principles of safe software evolution
Changing legacy – poorly structured, poorly tested – code is risky but necessary for the prevention of its further deteroriation and for making it better and thus decreasing its maintenance cost. It is well possible to minimize the risk – if we are cautious and proceed in small, safe steps while verifying the changes regularly (by testing and deploying to staging/production).
What is a small and a safe change?
It depends. But a good rule of thumb might be that it is such a change that (1) everybody else can daily merge in and that (2) can be then deployed to staging (and, f.ex. a day later, to production). If it should be possible to merge it in every day then it must be relatively small and non-destructive. If it should be deployed daily then it must be safe and backwards-compatible (or automatically migrating old data). If your change is larger or riskier than that, then it is too large/risky.
Cost & benefits of safety
It isn’t easy or “cheap” to change software in a safe way. It requires us to think hard, to ocassionally make it uglier for a while, to spend resources on maintaining (temporary) backwards-compatibility. It seems to be much more efficient to change the code without catering for such safety – but only until you hit unexpected problems and spend days trying to fix stuff, knee deep in the shit (i.e. broken codebase being constantly changed by your teammates). It is similar to TDD – it is slower but pays off thanks to the time you do not waste debugging and troubleshooting production issues. (Showing the time you *do not* loose to your team or management is unfortunately challenging.)
Sprinting Centipede – series of tiny changes
To make a change in small and safe steps, we often need to break it down and continually evolve the code towards the target design through a series of small changes, each one in a limited area of the codebase and along a single axis, changing a single thing only. The smaller and safer the changes, the faster we can perform and verify them and thus change quite a lot over time – this is what Kent Beck calls the Sprinting Centipede strategy.
Parallel Design: Sometimes a change cannot be really broken down, such as replacing a data storage with another one. In such a case we can apply for example the Parallel Design technique, i.e. evolving the new code, while still keeping the old code around. We can, for instance, first write only the code to store data in the new database; then start also reading from it while also reading from the old database, verifying the results are same and returning the old one; then we can start returning the new results (still keeping the old code around to be able to switch back); finally we can phase out the old code and storage.
Prerequisities
It is of course possible to follow the Sprinting Centipede strategy only if you can build, test, and deploy and get warned about possible problems quickly. The longer the test and deployment (and thus feedback) cycle the longer steps you must make otherwise you will spend most of the time waiting.
FAQ
How can I deploy to production a change I am not completely sure is correct?
Code, especially legacy code, can rarely be tested really thoroughly and thus we have never complete certainity of its correctness. But we cannot give up improving the code for otherwise it will be only getting worse. Fear and stagnation isn’t a solution – improvement of the codebase and the process is. We must carefuly consider the risk and test accordingly. The smaller the change and the better your monitoring and ability to roll back or fix quickly, the less impact will a possible defect have. (And if there is a chance for a defect, there will be one, earlier or later.)
Conclusion
It might seem slow to follow the Sprinting Cantipede strategy of software evolution, i.e. proceeding in small, safe, largely non-disruptive, incremental steps while merging regularly with the main development branch and verifying the changes often by running tests and deploying to the production environment. But our experience has shown that a Blind Frog Leap – a hope-driven large change or batch of changes – may actually be much slower and ocassionally infeasible due to unexpected but always present complications and defects and consequential delays, diverging branches etc. And I believe that this happens quite often. Therefore do change only one thing at a time, preferably so that the change can be deployed without requiring other (configuration etc.) changes, collect feedback, make sure that you can stop the refactoring at any time while gaining as much value as possible from it (instead of investing a lot of effort into a large change and risking that it will be abandoned completely). What is your experience?
It is noteworthy that a similar problem happens too often on the level of projects. People try to produce too much at once instead of doing something minimal, deploying, and continuing the development based on feedback rather than believes.
Resources
- The Limited Red Society (a good summary here) – Joshua Kerievsky discusses the need to reduce “red” periods of time while developing software (also introduces Parallel Change, which I refer to as Parallel Design above)
- A summary of Kent Beck’s talk about Best Practices for Software Design with Low Feature Latency and High Throughput
- The Mikado Method book (online) has a nice description of a typical failed refactoring in the section “The mikado method – a product of failure” (1.2 in the current version)
Acknowledgement
I’d like to thank to my colleagues Anders, Morten, and Jeanine for their help and feedback. Sorry Anders, I couldn’t make it shorter. You know, every word is a child of mine .
Reference: The Sprinting Centipede Strategy: How to Improve Software Without Breaking It from our JCG partner Jakub Holy at the The Holy Java blog.
