Given a couple of sentences, write a program that counts the number of words.

Now, the traditional thinking when solving this problem is read a word, check whether the word is one of the stop words, if not , add the word in a HashMap with key as the word and set the value to number of occurrences. If the word is not found in HashMap, then add the word and set the value to 1. If the word is found, then increment the value and word the same in HashMap.
Now, in this scenario, the program is processing the sentence in a serial fashion. Now, imagine if instead of a sentence, we need to count the number of words in encylopedia. Serial processing of this amount of data is time consuming. So, question is is there another algorithm we can use to speed up the processing.
Lets take the same problem and divide the same into 2 steps. In the first step, we take each sentence each and map the number of words in that sentence.

Once, the words have been mapped, lets move to the next step. In this step, we combine (reduce) the maps from two sentences into a single map.
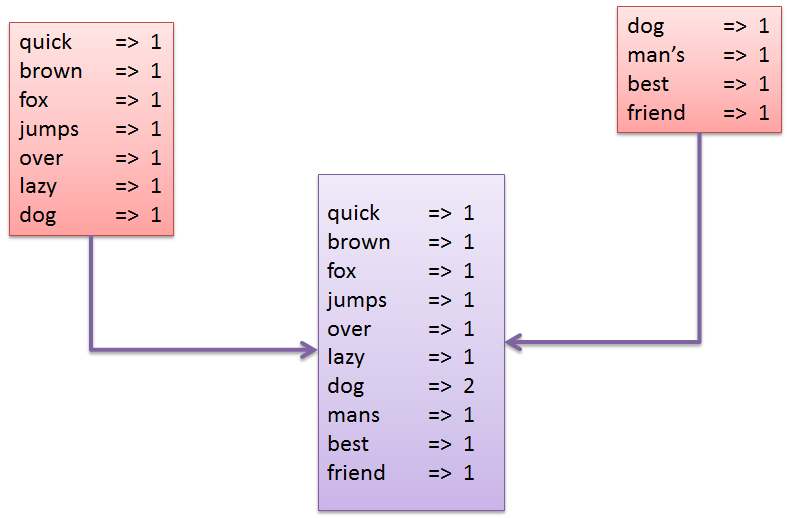
That’s it, we have just seen how, individual sentences can be mapped individually and then once mapped, can be reduced to a single resulting map.Advantage of the MapReduce approach is
- The whole process got distributed in small tasks that will help in faster completion of the job
- Both the steps can be broken down into tasks. In the first, instance, run multiple map tasks, once the mapping is done, run multiple reduce tasks to combine the results and finally aggregate the results

Now, imagine this MapReduce paradigm working on the HDFS. HDFS has data nodes that splits and store the files in blocks. Now, if map the tasks on each of the data nodes, then we can easily leverage the compute power of those data node machines.
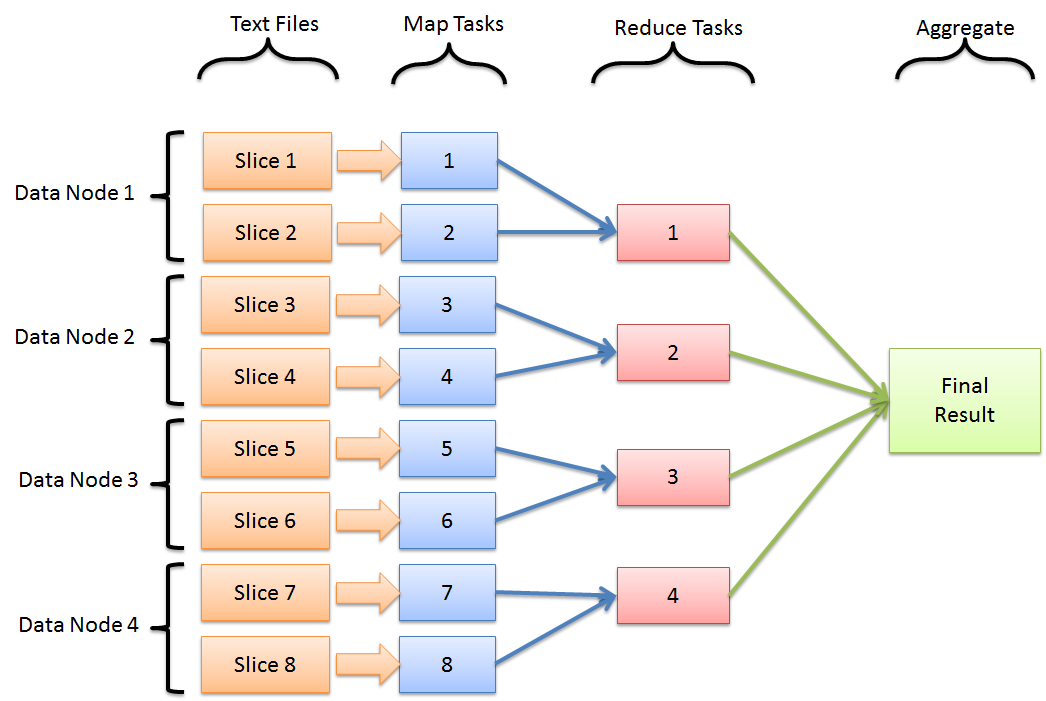
So, each of the data nodes, can run tasks (map or reduce) which are the essence of the MapReduce. As each data nodes stores data for multiple files, multiple tasks might be running at the same time for different data blocks.
To control the MapReduce tasks, there are 2 processes that need to be understood
- JobTracker – The JobTracker is the service within Hadoop that farms out MapReduce tasks to specific nodes in the cluster, ideally the nodes that have the data, or at least are in the same rack.
- TaskTracker – TaskTracker is a process that starts and tracks MapReduce Tasks in a cluster. It contacts the JobTracker for Task assignments and reporting results.
These Trackers are part of the Hadoop itself and can be tracked easily via
- http://<host-name>:50030/ – web UI for MapReduce job tracker(s)
- http://<host-name>:50060/ – web UI for task tracker(s)
Reference: MapReduce for dummies from our JCG partner Munish K Gupta at the Tech Spot blog.

Brilliant illustration of Map-Reduce algorithm.
Thank you.