Cache is a component that will magically store data so that future requests of that same data will not be to the Remote Server, and hence it will improve the performance of our application significantly faster
We were working on a website which was to integrate with an existing application through the use of APIs and for purposes of closer integration we had decided to store the data in form of XML as artifacts in this tool as tracker items – no RDBMS. It was like running two applications joint at the hip.
I had gathered enormous experience working with SourceForge platform APIs as I had integrated them with Ms-Excel and now we were going to build an entire application on ALM space using the same APIs. Our biggest challenge was going to be performance because of the use of APIs against a remote server sitting in a different geography. And Cache was going to be instrumental in helping us solve that problem.
We had just decided to implement Write-through cache that helped us build a system which was significantly faster that anyone could have thought about. And since then this is one pattern that I have come to use (if possible) whenever I am working with diversified systems. Surprisingly, the percentage of people who have used cache have never heard of this pattern of cache implementation when the underlying issues with the systems can be solved using this pattern (I am still mystified as to why not?).
Before we dig deep, I want to run through some definitions that we are going to use during the course of this article:
- Cache hit refers to a request to the data and finding it in the cache
- Cache miss refers to a request to the data and not finding it in the cache
- Dirty refers to a cached data if it has not the same as the original data
- Lazy refers to an action if it not performed real time, but only when it is required
In its simplest form, a cache implementation is going to something similar to the image below.
As you can already see that this is just one part of the cache implementation and implementing this workflow alone would mean that once I have a data in the cache it would only always fetch the data from the local cache location and go back to the original data source only if the cache data is Dirty. And there are several ways we have to mark the data as dirty – it can be an action we configure in our system like – “If we are update records in the data source, we try to find the key and mark it dirty”. Another way is to decide a time after which the the cache should be expired automatically.
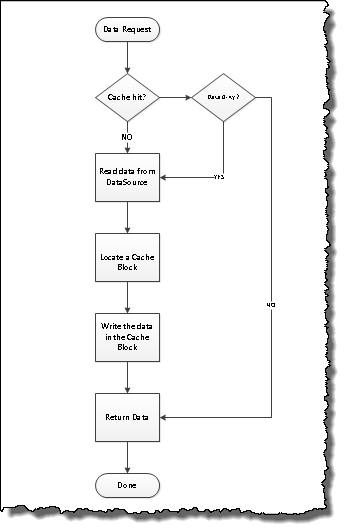 |
| Cache – Workflow |
While, this approach is simple enough, this does presents a unique “problem” (and it may not be a problem for everyone). Lets revisit the reason for which we decided to implement cache.
Cache is a component that will magically store data so that future requests of that same data will not be to the Remote Server, and hence it will improve the performance of our application significantly faster.
This implies that “Caching is a mechanism that is faster when compared to our data source when it comes to data loading”. I have observed cache implementations against RDBMS sitting next to a Application Server, which means that loading data from the RDBMS is still faster and hence there is really no need to improvise on the cache flow as defined earlier.
In our case, we were dealing with an external system from where we fetched XML over HTTPS and then converted the XML to an object. This entire process was time consuming – 3 seconds for one object and there was nothing we could do about reducing the transportation time. It also meant that the classic workflow for us would not work either, especially if a user would update a specific record, and if the cache would be marked dirty, the next request would mean a significant delay time.
We improvised and it was then we used the write-through cache logic that allowed us to manage the data in the cache in real-time with the data-source. The workflow was changed to the one below:
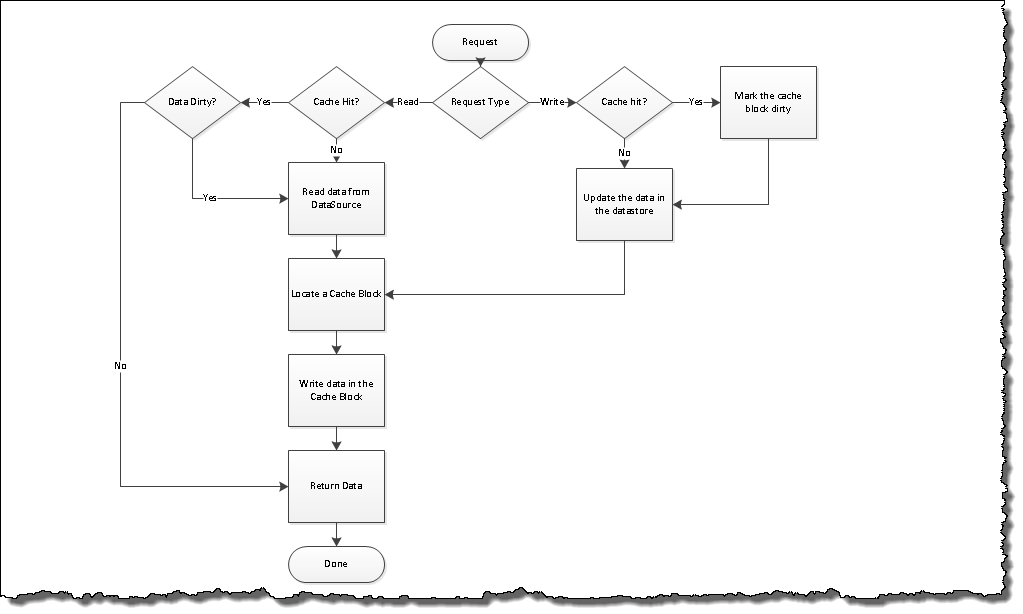
As simple as it may look it was not so. Lets see first what we did. We added a hook to the code which was required to save the data in the DataSource to do two things:
- Find the cache entry and mark it dirty if it was a hit and;
- Update the cache after a successful update to the data store
This allowed us to keep the cache in sync with the DataSource and hence not requiring to spend additional time to load the data back again.
But, as I feel that every solution will bring its challenges, this one had as well especially when we decided to scale and move over to a cluster of application server. This meant that a local cache would simply not work because it was meant that an update to the DataSource meant that the cache on other application servers was out dated and users would not get the most latest data making it impossible to work. We did use version to records to manage the concurrency checks, and not keeping the cache in sync meant that other users will see their updates fail because of that very fail-safe. Eventually, we had to find a cache that can be scaled in a cluster which only made things more complicated.
A pattern that I learn in my development adolescence, this had proved to be a powerful technique to build solutions that would work fine in a given scenario.
Reference: Write Through Cache from our JCG partner Kapil Viren Ahuja at the Scratch Pad blog.
