1. Introduction
This series of articles shows how one can process real time stream data using a number of technologies. The input data stream is flight data arriving real-time from a sensor (either one you can buy from Amazon or more advanced ones like civilian or military radars). To avoid the hassle of buying a sensor or connecting to one (which might also be illegal or risky), we use historical flight data in JSON format instead, downloaded from here.
Table Of Contents
When the first article of this series was published, these data were publicly available and could be downloaded for free. Unfortunately, this is not the case anymore. “The historical search at flight-data.adsbexchange is currently down until further notice.” After contacting ADS-B exchange, they authorise redistribution of the 2016 history flight data JSON files which you can download as part of the download bundle of this article.
In the third part of this series of articles about real-time stream processing, we learned how to import the .json flight data files to ElasticSearch using its bulk API as well as its low-level and high-level REST APIs. In the fourth part we used Logstash to do the job. However, to allow for scalability but also for powerful stream processing, other technologies can be of help. In this article we will learn how to let Apache Storm process the incoming flights and store them to ElasticSearch. The architecture we want to achieve is shown below:

But why do we want to add yet another layer into our architecture? Isn’t ElasticSearch (and LogStash or the Java clients we saw in the previous articles) just enough, some may argue? Unfortunately, neither the Java programs we wrote in part 3 nor LogStash that we saw in part 4 can cope with real time stream data that come in very short delays. Flight data may arrive every 250ms or less, and our system needs to be able to cope with that. Additionally, the technologies we used in the previous articles don’t support clustering or redundancy. Of course, you can adapt the Java program of part 3 to make it scalable and performant as Apache Storm, but compare the effort with what Apache Storm offers. We will reuse part of the code from part 3 for this article.
The workflow is shown in Figure 2. We would like to read flight data (coming as stream data in real life, but in batch in our example), process them, and store them to ElasticSearch. And in this article, we will use Apache Storm to do that. But what is Apache Storm?

2. What is Apache Storm
Apache Storm is a distributed, real-time computational framework donated to Apache by Twitter. It can process a very large amount of data in real time in a highly scalable manner. Apache Storm can be fast, fault tolerant, recoverable, horizontally scalable, programming language agnostic and easy to operate. It can do stream processing, continuous parallelized computation, and real-time analytics. It works for real-time data just as Hadoop works for batch processing of data. If it crashes, it will restart and pick up work from the point of crash. It can be integrated with your existing queuing and persistence technologies, consuming streams of data and processing/transforming these streams easy.
Execution is performed in a Storm cluster (it is superficially similar to a Hadoop cluster). Whereas on Hadoop you run “MapReduce jobs”, on Storm you run “topologies”. “Jobs” and “topologies” themselves are very different. A MapReduce job eventually finishes, whereas a topology processes messages forever (or until you kill it).
Apache Storm has its applications designed in the form of directed acyclic graphs (DAGs). It is known for processing over one million tuples per second per node, which is highly scalable and provides processing job guarantees. Storm provides strong guarantees that each message passed on to it will be processed at least once.
Apache Storm does not have any state-managing capabilities and relies heavily on Apache ZooKeeper (a centralised service for managing the configurations in Big Data applications) to manage its cluster state.
Storm is written in Clojure which is a Lisp-like functional programming language. It is multilingual, i.e. it supports multitude of languages, making it more developer friendly. At the heart of Apache Storm is a “Thrift Definition” for defining and submitting the logic graph (also known as topologies). Storm topologies are implemented by Thrift interfaces which makes it easy to submit topologies in any language. Storm supports Ruby, Python and many other languages.
2.1 Apache Storm’s architecture
A Storm cluster follows a master-slave model where the master and slave (worker) processes are coordinated through ZooKeeper (see Figure 3).
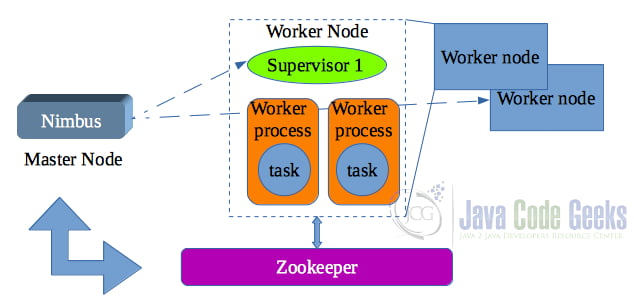
The master node is called Nimbus and there is a single Nimbus node in a Storm cluster. Nimbus is stateless and stores all of its data in ZooKeeper. It is responsible for distributing the application code across various worker nodes, assigning tasks to different machines, monitoring tasks for any failures, and restarting them as and when required. It is designed to be fail-fast, so when Nimbus dies, it can be restarted without having any effects on the already running tasks on the worker nodes.
Worker nodes are responsible for performing the tasks. Worker nodes in a Storm cluster run a service called Supervisor; they are also called Supervisory nodes. The Supervisor is responsible for receiving the work assigned to a machine by the Nimbus service. Supervisor supervises the worker processes and helps them complete the assigned tasks. Each supervisor node runs a supervisor daemon that is responsible for creating, starting, and stopping worker processes to execute the tasks assigned to that node. Each of these worker processes executes a subset of the complete topology. Like Nimbus, a supervisor daemon is also fail-fast and stores all of its state in ZooKeeper so that it can be restarted without any state loss. A single supervisor daemon normally handles multiple worker processes running on that machine. Apache Storm uses an internal distributed messaging system for the communication between nimbus and supervisors.
ZooKeeper is being used by a Storm cluster to allow various processes to coordinate with each other and allow them to share some configuration information. Nimbus and supervisor nodes do not communicate directly with each other but through ZooKeeper. The Nimbus daemon finds available Supervisors via ZooKeeper, to which the Supervisor daemons register themselves. As all data are stored in ZooKeeper, both Nimbus and the supervisor daemons can be killed abruptly without adversely affecting the cluster. A Storm cluster can run more than one Zookeeper instance.
Zookeeper is designed to “fail fast”, i.e. it will shut down if an error occurs that it can’t recover from. However, this isn’t desirable within a Storm cluster because Zookeeper coordinates communication between Nimbus and the Supervisors. So, also for Zookeeper a supervisory process is required that will handle restarting any failed individual Zookeeper server, allowing the Zookeeper cluster to be self-healing, too. E.g. you may use Supervisord (not to be confused with Apache Storm’s Supervisor).
The data exchange between nodes is done via tuples. Each tuple consists of a predefined list of fields. A tuple is dynamically typed, i.e. you just need to define the names of the fields in a tuple and not their data type. The value of each field can be byte, char, integer, long, float, double, boolean, or byte array. Each of the fields in a tuple can be accessed by its name getValueByField(String) or by its index getValue(int) in the tuple. There are also convenient data type methods like getIntegerByField(String).
The graph of a computation is called a topology in Apache Storm. You create a Storm topology and deploy it on a Storm cluster to process the data. A topology can be represented by a directed acyclic graph (DAG), where each node does some kind of processing and forwards it to the next node(s) in the flow. An example topology is shown in the following figure:
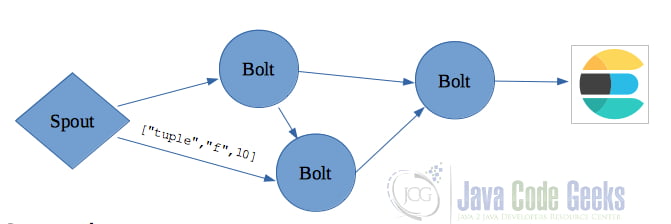
As shown in the above figure, a Storm topology consists of:
- Spouts: Spouts are producers of tuples in a Storm topology. A spout is responsible for reading or listening to data from an external source. A spout can emit multiple streams, each of different schemas. Whenever a spout emits a tuple, Storm tracks all the tuples generated while processing this tuple, and when the execution of all the tuples in the graph of this source tuple is complete (all these tuples must have the same message Id), it will send back an acknowledgement to the spout. It is important to note that none of the methods of a spout should be blocking, as Storm calls all the methods in the same thread. A tuple-processing timeout can also be defined for a topology.
- Bolts: A bolt is the processing unit responsible for transforming a stream. Ideally, each bolt in the topology should be doing a simple transformation of the tuples, and many such bolts can coordinate with each other to exhibit a complex transformation. A bolt can subscribe to multiple streams of other components, either spouts or other bolts, and similarly can emit output to multiple streams.
- Streams: A Stream is an unbounded sequence of tuples that can be processed in parallel by Storm. Each stream can be processed by a single or multiple types of bolts. Each stream in a Storm application is given an Id and the bolts can produce and consume tuples from these streams based on their Id. Each stream also has an associated schema for the tuples that will flow through it. Streams are represented by the edges (arrows) in Figure 4.
Here we summarize all the terms required to understand Apache Storm. A visual representation of them is shown in Figure 5. Feel free to revisit these definitions when in doubt:
- Cluster: as its name denotes Storm can run in a cluster of nodes (or machines). A Storm cluster consists of two types of nodes: the master node and the worker nodes. A master node runs a daemon called Nimbus, and the worker nodes each run a daemon called a Supervisor. Storm supports only a single master node. Storm relies on Apache Zookeeper for coordinating communication between Nimbus and the Supervisors. E.g. if Nimbus or a Supervisor is recovered after a failure, it restores its state from Zookeeper.
- Node: A node represents a physical or virtual machine running any operating system.
- Nimbus: a daemon process that distributes code around the cluster, assigns tasks to worker nodes, monitors for failures, and runs the Storm Ul.
- Supervisor: a daemon process that listens for work assigned to its worker node by Nimbus and starts/stops worker processes. If a Supervisor notices that one of the worker processes is down, it will immediately restart it.
- Worker: This is the machine (node) where the Supervisor and the worker processes are executed. Each worker can run one or more worker processes.
- Worker process: is a JVM that runs one or more executors.
- Executor: is a thread of execution in a worker process (JVM) which runs one or more tasks (i.e. instances of spouts or bolts). (In reality, an executor is more than one thread, but let’s keep it simple here for convenience).
- Task: an instance of a spout/bolt running within an executor. Each executor (thread) is executing one or more tasks (instances of a spout/bolt).
- Topology: A topology is a graph of nodes and edges, where nodes represent computations and edges represent the results of the computations. Figure 6 represents a topology, where “Read flight data”, “Process flight data” and “Store flight data” represent nodes while the arrows connecting them are the edges of the graph. The edges represent data flows or streams. Storm uses a data structure called tuple to propagate data. Nodes represent either spouts or bolts. Edges represent streams of tuples between these spouts and bolts.
- Spout: A spout is the source of a stream in the topology. Spouts normally read data from an external data source and emit tuples into the topology. In our example, the spout parses the history flight data from the .json files (in a real-time system it would receive them as a data stream from some sensor). Spouts don’t perform any processing; they simply act as a source of streams, reading from a data source and emitting tuples to the next type of node in a topology: the bolt.
- Bolt: a bolt accepts a tuple from its input stream, performs some computation or transformation, e.g. filtering, aggregation, join, on that tuple, and then optionally emits a new tuple (or tuples) to its output stream(s). Our bolts do various conversions on the data, like format the dates, create map points etc. and finally store the results to ElasticSearch.
- Tuple: A tuple is an ordered list of values, where each value is assigned a name. It represents the data passed between two nodes. Here is a representation of a tuple:
[name1="value1", name2="value2",...]. We will see how tuples are actually defined in Storm. - Stream: an unbounded sequence of tuples between two nodes in the topology. A topology can contain any number of streams. A node can create more than one output stream.
- Stream grouping: A stream grouping defines how the tuples are sent between instances of those spouts and bolts. Storm comes with several stream groupings out of the box:
- Shuffle grouping: tuples are emitted to instances of bolts at random. It guarantees that each bolt instance should receive a relatively equal number of tuples, thus spreading the load across all bolt instances.
- Fields grouping: ensures that tuples with the same value for a particular field name are always emitted to the same instance of a bolt.
- All grouping: replicates the tuples to all bolts
- Global grouping: sends the complete stream to the bolt’s task with the smallest ID; used when you want to combine results (reduce).
- Direct grouping: the emitter decides where each tuple will go for processing
- Local or shuffle grouping: If the tuple source and target bolt tasks are running in the same worker, using this grouping will act as a shuffle grouping only between the target tasks running on the same worker, thus minimizing any network hops resulting in increased performance. In case there are no target bolt tasks running on the source worker process, this grouping will act similar to the shuffle grouping mentioned earlier.
- Custom grouping: If none of the preceding groupings fits your use case, you can define your own custom grouping.
In a running topology, there are normally numerous instances of each type of spout/bolt performing computations in parallel. Each spout and bolt will have one or many individual instances that perform all of this processing in parallel.
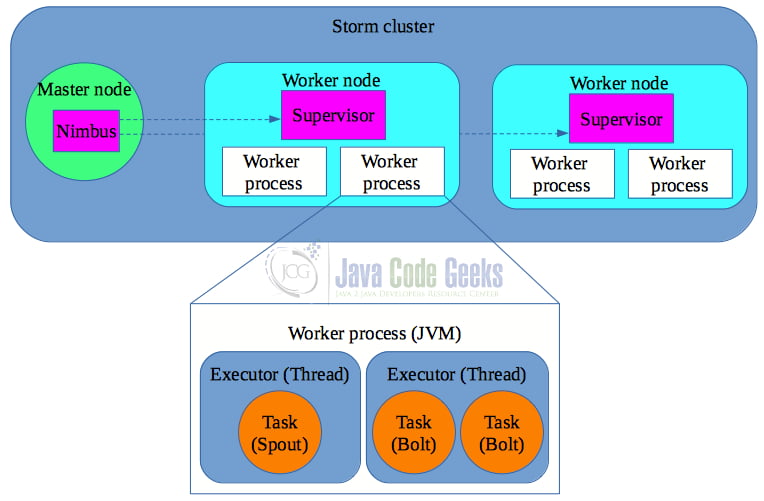
As you see in Figure 5, a Storm cluster has a single master node which runs Nimbus. It also runs a number of worker nodes that can run in the same or different (physical or virtual) machines. Each worker node runs the Supervisor daemon. Each worker node can run a number of worker processes (or JVMs). Each worker process can run a number of executors (or threads). Each executor runs a number of tasks (spout or bolt instances).
If you are overwhelmed by all this information, it is OK, you should be. Feel free to consult each of these terms while you continue reading this article and in the future.
3. Installations
As you may have understood by now, one needs to install both Apache Zookeeper and Storm.
3.1 Install Apache Zookeeper
As we mentioned above, Nimbus and supervisor nodes do not communicate directly with each other but through ZooKeeper. This section describes how you can set up a ZooKeeper cluster. We are deploying ZooKeeper in standalone mode. In production it is recommended to deploy it in distributed cluster mode, in an ensemble of at least three nodes to support fail-over and high availability.
Perform the following steps to set up ZooKeeper on your machine:
- Download Zookeeper and unzip it to a directory. We will refer to this directory as
$ZK_HOME. - Before you execute it you need to provide a configuration file.
$ cd $ZK_HOME $ cp conf/zoo_sample.conf conf/zoo.conf $ more conf/zoo.conf # The number of milliseconds of each tick tickTime=2000 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5 # the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. dataDir=$ZK_HOME/data # the port at which the clients will connect clientPort=2181 ...
tickTime is used to send heartbeats and the minimum session timeout will be twice the tickTime value. dataDir is an empty directory to store the in-memory database snapshots and transactional log. clientPort is the port used to listen for client connections.
Keep in mind that Zookeepers’ transactional logs can get quite large, therefore, it’s critical to set up some sort of process to compact (and even archive) these logs.
To start Zookeeper:
$ bin/zkServer.sh start & ZooKeeper JMX enabled by default Using config: $ZK_HOME/bin/../conf/zoo.cfg Starting zookeeper ... STARTED
3.2 Install Apache Storm
Apache Storm can operate in two modes: local or remote. We will start by using Storm locally to our machine and later we will describe how to create a distributed Storm cluster.
- Download Apache Storm and unzip it to a directory. We will refer to this directory as
$STORM_HOME. - Edit
conf/storm.yamllike so:
storm.zookeeper.servers:
- "127.0.0.1"
storm.zookeeper.port: 2181
nimbus.host: "127.0.0.1"
storm.local.dir: "/tmp/storm-data"
#java.library.path: "/usr/local/lib"
supervisor.slots.ports:
- 6700
- 6701
# - 6702
# - 6703
java.library.path is used to load the Java native libraries that Storm uses (ZeroMQ and JZMQ). The default location of these native libraries is /usr/local/lib:/opt/local/lib:/usr/lib. The native dependencies are only needed on actual Storm clusters. When running Storm in local mode, Storm uses a pure Java messaging system so that you don’t need to install native dependencies on your development machine. For every worker machine, we can configure how many workers run on that machine with the property supervisor.slots.ports. Each worker binds to a single port and uses that port to receive incoming messages. In the above configuration, there are four worker processes bound to ports 6700 to 6703, but we have commented out the last two.
Start nimbus and a supervisor:
$ bin/storm nimbus & $ bin/storm supervisor &
If you try to execute Storm in an old MacOSX version (<10.15) then you may encounter the error described here. Please vote for it to be fixed.
4. Our topology
Before we start coding, let’s see what are the tasks that we have to perform:
- Read the
.jsonflight history data files. As you should know by now, this will be done with a spout. - Process the JSON flight data; e.g. convert the dates to a human readable format and add a location field
- Store the flight data to ElasticSearch; this will be done by a bolt.
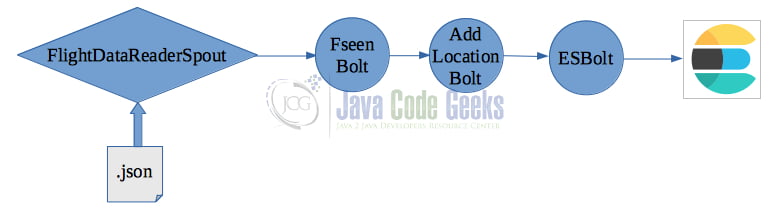
First we need to read the .json flight history data files (in a real system these flight data should arrive real-time by some kind of sensor). As you have learned by now, this is the job of a spout. The FlightDataReaderSpout will read the flight data and then stream the data (in the form of tuples) to a number of bolts for further processing. The final bolt will store the processed data to ElasticSearch. The following figure visualizes what we just described, in other words, our topology.

4.1 Implementing our topology
Let’s create a new maven project with the following dependencies:
<dependencies>
<!-- Storm Dependency -->
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>2.2.0</version>
</dependency>
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.8.6</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>7.11.0</version>
</dependency>
</dependencies>
Our code consists of three kinds of classes:
- a spout to read the
.jsonflight data files - a bolt to store them to ElasticSearch
- a topology to coordinate the above
Our spout reads flight data from a .json file and emits the tuple ["id", "index", "type", "source"].
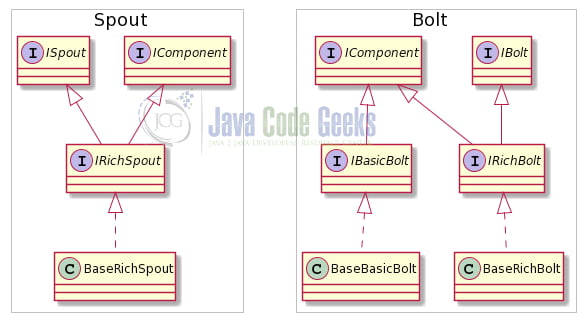
Figure 7 shows the class hierarchies of Spout and Bolt. IComponent is the common interface for all topology components (both spouts and bolts) and defines a component’s configuration and output. Our spout extends BaseRichSpout while our bolt extends BaseBasicBolt. IBasicBolt only supports a subset of the features of IRichBolt. BaseBasicBolt provides a simpler and more concise implementation of BaseRichBolt. BaseBasicBolt isn’t suitable for every use case though. It’s mainly used in use cases where a single tuple enters the bolt and a single corresponding tuple is emitted from that bolt immediately. For more complex uses cases, one should use the BaseRichBolt.
4.2 Spout
Our FlightDataReaderSpout extends BaseRichSpout
public class FlightDataReaderSpout extends BaseRichSpout {
which implements the following interface:
public interface ISpout extends Serializable {
void open(Map config, TopologyContext context, SpoutOutputCollector outputCollector);
void close();
void nextTuple();
void ack(Object messageId);
void fail(Object messageId);
}
We need to override the following methods:
open(Map conf, TopologyContext context, SpoutOutputCollector collector): which is called only once, when the spout is initialized. Provides the spout with an environment to execute. The executors will run this method to initialize the spout. We override it to read the history data files, and then keep fetching the data from this external source in thenextTuple()method to emit it further. It takes three parameters:conf: provides storm configuration for this spout.FlightDataReaderSpoutreads the flight data filename from the configuration that has passed to it via the topology.context: provides complete information about the spout within the topology, its task id, input and output information.collector: is the tuple to be emitted by the spout in order to be processed by the bolts.
Below is the implementation of the open() method.
private SpoutOutputCollector outputCollector;
private Reader jsonReader;
private boolean completed = false;
// Called when a task for this component is initialized within a worker on the cluster.
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.outputCollector = collector;
final String flightData = conf.get("flightData").toString();
try {
this.jsonReader = Files.newBufferedReader(Paths.get(flightDataFile));
} catch (FileNotFoundException e) {
throw new RuntimeException("Error reading file [" + flightData + "]");
}
}
declareOutputFields(): this is where we define the output schema of the tuple, i.e. the field names for all the tuples emitted by this spout. The order of the names in theFieldsconstructor must match the order of the values emitted in the tuple via theValuesclass. We generate tuples of this format:[id=id, index="flight", type="_doc", source=flightDataAsJsonString]:
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("id", "index", "type", "source"));
}
@Override
public void nextTuple() {
...
Values values = new Values(id, "flight", "_doc", flightDataAsJsonString);
collector.emit(values, id);
...
}
The mapping is shown below:
| Fields: | id |
index |
type |
source |
| Values: | "4800770" |
"flight" |
"_doc" |
{"Rcvr" : 1, "HasSig" : false, "Icao" : "494102", ...} |
but you are free to choose any other mapping. We will explain later why we chose this mapping.
nextTuple()reads and processes the input data and produces the output tuple, an instance of SpoutOutputCollector, that is emitted to the bolts. The schema for streams can be declared by using thedeclareStream()method of OutputFieldsDeclarer. If a spout wants to emit data to more than one streams, it can declare multiple streams using thedeclareStream()method and specify a stream ID while emitting the tuple. If there are no more tuples to emit at the moment, this method should not be blocked. It must release control of the thread when there is no work to do, so that the other methods have a chance to be called. So the first line ofnextTuple()checks to see if processing has finished, and if this is the case, it should sleep for at least one millisecond to reduce load on the processor before returning.
@Override
public void nextTuple() {
if (completed) {
Utils.sleep(5000);
return;
}
//parse the JSON flight data
JsonArray acListArray = map.get("acList").getAsJsonArray();
int count = 0;
for (JsonElement flight : acListArray) {
// ...
JsonObject flightAsJsonObject = flight.getAsJsonObject();
String id = flightAsJsonObject.get("Id").getAsString();
String flightAsJsonString = flightAsJsonObject.toString();
// The index under which data will be stored in ES
Values values = new Values(id, "flight", "_doc", flightAsJsonString);
outputCollector.emit(values, id);
}
completed = true;
}
Inside this method we read the .json flight data file, we retrieve the acList where the actual flight data are, and for each element in the acList array we set the flight’s Id and emit the tuple as described previously.
ack(Object msgId): is invoked by Storm when the tuple with the given message ID is completely processed by the topology. At this point, the user should mark the message as processed and do the required cleaning up such as removing the message from the message queue so that it does not get processed again.
// Called when Storm detects a tuple emitted successfully
@Override
public void ack(Object msgId) {
LOG.debug("SUCCESS: " + msgId);
}
fail(Object msgId): is invoked by Storm when it identifies that the tuple with the given message ID has not been processed successfully or has timed out of the configured interval. Here we do the required processing so that the messages can be emitted again by thenextTuple()method. A common way to do this is to put the message back in the incoming message queue. In our case, we do nothing.
// Called when a tuple fails to be emitted
@Override
public void fail(Object msgId) {
LOG.debug("ERROR: " + msgId);
}
close(): the opposite ofopen(), closes any external resources.
@Override
public void close() {
if (jsonReader != null)
try {
jsonReader.close();
} catch (IOException e) {
LOG.error(e.getLocalizedMessage());
}
}
If we want to treat the source as an unreliable data source, the spout doesn’t need to keep track of which tuples failed and which ones succeeded in order to provide fault tolerance (as is our case). E.g. we don’t care if we miss or not process some of the source data (updated flight data events will arrive in a few milliseconds from the sensor anyway). Not only does that simplify the spout implementation, it also removes quite a bit of bookkeeping that Storm needs to do internally and speeds things up. When fault tolerance isn’t necessary and we can define a service-level agreement (SLA) that allows us to discard data at will, an unreliable data source can be beneficial; it’s easier to maintain and provides fewer points of failure. In our case, we do, however, demonstrate the fault tolerant scenario by:
- providing an id to each emitted tuple (
outputCollector.emit(values, id);) - implementing the
ack()andfail()methods
If we don’t care about failed tuples, like in our case, we should use outputCollector.emit(values) and there is not need to implement the ack() and fail() methods.
4.3 Bolt
Our ElasticSearchBolt stores the tuples received from FlightDataReaderSpout to ElasticSearch. It extends BaseBasicBolt which implements the IBasicBolt interface.
/**
* A bolt that sends data to ElasticSearch via REST.
*/
public class ElasticSearchBolt extends BaseBasicBolt {
private RestClient restClient;
Our bolt overrides the following methods:
prepare(Map conf, TopologyContext context, OutputCollector collector): A bolt can be executed by multiple workers in a Storm topology. The instance of a bolt is created on the client machine and then serialized and submitted to Nimbus. When Nimbus creates the worker instances for the topology, it sends this serialized bolt to the workers. The worker deserializes the bolt and calls the prepare() method. It provides the bolt with an environment to execute. The executors will run this method to initialize the bolt. In this method, you should make sure the bolt is properly configured to execute tuples. Any state that you want to maintain can be stored as instance variables for the bolt that can be serialized/deserialized later. Ourprepare()method initializes the ElasticSearch RestClient. The parameters are the same as of the spout. Since our bolt will not emit any tuples, we use the overriden method without theOutputCollector.
@Override
public void prepare(Map<String, Object> conf, TopologyContext context) {
restClient = RestClient.builder(
new HttpHost("localhost", 9200, "http")).build();
}
execute(Tuple input, BasicOutputCollector outputCollector): This method is executed for each tuple at a time that comes through the subscribed input streams. In this method, you can do whatever processing is required for the tuple and then produce the output either in the form of emitting more tuples to the declared output streams or other things such as persisting the results in a database. You are not required to process the tuple as soon as this method is called, and the tuples can be held until required. For example, while joining two streams, when a tuple arrives, you can hold it until its counterpart also comes, and then you can emit the joined tuple. The metadata associated with the tuple can be retrieved by the various methods defined in the Tuple interface. If a message ID is associated with a tuple, theexecute()method must publish anackorfailevent usingOutputCollectorfor the bolt or else Storm will not know whether the tuple was processed successfully or not. TheIBasicBoltinterface is very convenient because it sends an acknowledgement automatically after the completion of theexecute()method. In the case that a fail event is to be sent, this method should throw aFailedException. Ourexecute()method extracts the field values from the received tuple, creates a REST endpoint to our ElasticSearch instance and sends the request to ElasticSearch.
@Override
public void execute(Tuple tuple, BasicOutputCollector basicOutputCollector) {
String id = tuple.getStringByField("id");
String index = tuple.getStringByField("index");
String type = tuple.getStringByField("type");
String source = tuple.getStringByField("source");
String endPoint = "/" + index + "/" + type + "/" + id;
Request request = new Request("POST", endPoint);
request.setJsonEntity(source);
try {
restClient.performRequest(request);
} catch (IOException e) {
LOG.error("Error during rest call", e);
}
}
execute() is thread safe, i.e. it is processing only one tuple at a time. Within a given bolt instance, there will never be multiple threads running through it. However, when you emit a data structure, it is recommended to make it immutable or emit a copy of it to avoid the case where it is serialized to another thread while at the same time you are updating it.
declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer): since this is a final bolt, it emits no tuples for further processing, so no need to declare the schema of the output tuples.
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
// nothing to declare
}
4.4 Topology
Finally, we glue everything together with a Topology. We need to build up the topology, defining the streams and stream groupings between the spout and bolts. Our FlightPlanIndexingTopology is created from the following:
TopologyBuilderis used to glue spouts and bolts together, also defining the streams and stream groupings between them.Configis used for defining topology-level configuration. TheConfigclass is used to set configuration options before submitting the topology. These configuration options will be merged with the cluster configuration at run time and sent to all tasks (spout and bolt) with theprepare()method. We use it to send the file path of the.jsonflight data file to our spout.StormTopologyis produced byTopologyBuilderand is submitted to the cluster for execution.LocalClustersimulates a Storm cluster in-process on our local machine for testing purposes. For production, use a distributed Zookeeper cluster and replaceLocalClusterbyStormSubmitter. It is advised to run an odd number of ZooKeeper nodes, as the ZooKeeper cluster keeps working as long as the majority of the nodes are running.
Our FlightPlanIndexingTopologyBuilder builds a StormTopology that contains our bolt and spout. The stream between them uses shuffleGrouping in order to distribute the tuples randomly for processing to the bolts.
public class FlightPlanIndexingTopologyBuilder {
private FlightPlanIndexingTopologyBuilder() {}
public static StormTopology build() {
TopologyBuilder builder = new TopologyBuilder();
ElasticSearchBolt indexBolt = new ElasticSearchBolt();
builder.setSpout("spout", new FlightDataSpout());
builder.setBolt("indexBolt", indexBolt).shuffleGrouping("spout");
return builder.createTopology();
}
}
/**
* A topology that reads flight data from json files using
* Spout {@link FlightDataReaderSpout} and stores them to ElasticSearch using {@link ElasticSearchBolt}.
*/
public class FlightPlanIndexingTopology extends ConfigurableTopology {
private static final int FIVE_MINUTES = 300000;
private static final String JSON_FILE_PATH
= new File("src/main/resources/flightdata/2016-07-01-1300Z.json").getAbsolutePath();
private static final String TOPOLOGY_NAME = "es-index-flights";
public static void main(String[] args) {
ConfigurableTopology.start(new FlightPlanIndexingTopology(), args);
}
@Override
protected int run(String[] args) {
// Create configuration
conf.setDebug(true);
conf.put("flightData", JSON_FILE_PATH);
conf.setNumWorkers(2); // number of worker processes or JVMs
// Build the topology
final StormTopology topology = FlightPlanIndexingTopologyBuilder.build();
// Run topology
try {
LocalCluster localCluster = new LocalCluster();
localCluster.submitTopology(TOPOLOGY_NAME, conf, topology);
Utils.sleep(FIVE_MINUTES);
localCluster.killTopology(TOPOLOGY_NAME);
localCluster.shutdown();
} catch (Exception e) {
e.printStackTrace();
}
return 0;
}
}
4.5 Processing flight data
As we have also done in the previous articles of this series, we need to do some processing on the flight data, like:
- remove the
“Id”field since this will become the index of the JSON record - remove
“/Date(...)\/”fromFSeenfield - add a new
Locationfield withlat,lonattributes
We could create a separate bolt for each of these tasks or do them in FlightDataReaderSpout. Since they are not complex tasks, we chose to implement them in FlightDataReaderSpout for reasons that we explain later in Design Strategies chapter.
private void processFSeen(JsonObject jsonObject) {
String fSeenAsString = jsonObject.get("FSeen").getAsString().replaceAll("\\D+", "");
// implementation can also be done using java.time.LocalDateTime classes
Calendar fSeen = Calendar.getInstance();
fSeen.setTimeInMillis(Long.parseLong(fSeenAsString));
String fSeenTimeAsString = DATE_FORMAT.format(fSeen.getTime());
jsonObject.addProperty("FSeen", fSeen.getTimeInMillis());
jsonObject.addProperty("FSeenDateTime", fSeenTimeAsString);
}
private void addLocationAsGeoPoint(JsonObject jsonObject) {
if (jsonObject.get("Lat") != null && jsonObject.get("Long") != null) {
JsonObject locationElement = new JsonObject();
locationElement.addProperty("lat", jsonObject.get("Lat").getAsFloat());
locationElement.addProperty("lon", jsonObject.get("Long").getAsFloat());
jsonObject.add("location", locationElement);
}
}
4.6 Execute our topology
It is recommended to create an all-inclusive jar that contains all dependencies. You can easily do that by adding the following plugin inside build section of your pom.xml:
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass>com.javacodegeeks.topology.FlightPlanIndexingTopology</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
and issue: mvn package.
One can then execute the project by issuing the maven command:
mvn compile exec:java -Dexec.classpathScope=compile
-Dexec.mainClass=com.javacodegeeks.topology.FlightPlanIndexingTopology
either from the command line or from your IDE.
We can deploy the topology to the Storm cluster using the following Storm client command:
cd drs-storm $STORM_HOME/bin/storm jar target/drs-1.0-SNAPSHOT-jar-with-dependencies.jar com.javacodegeeks.topology.FlightPlanIndexingTopology
The main function of FlightPlanIndexingTopology is to define the topology and submit it to the Nimbus machine. The storm jar part takes care of connecting to the Nimbus machine and uploading the JAR part.
However, when you execute the above command you will receive the following error message:
Exception in thread "main" java.lang.RuntimeException: Found multiple defaults.yaml resources. You're probably bundling the Storm jars with your topology jar.
Indeed, drs-1.0-SNAPSHOT-jar-with-dependencies.jar contains defaults.yaml, too, and Storm runtime is confused as which one to use. This Stackoverflow reply provides a solution, which I couldn’t succeed in applying it, though. You may also create an assembly as described in this solution. And of course, you may simply delete defaults.yaml from the jar manually, after it has been created. Another solution is instead of creating a jar with all the dependencies, to use the jar that contains your topology classes only and simply pass the dependencies with the --jar option as described here, omitting storm-core (or any of the other two solutions described in the same article). Separate the various jars with comma (,):
$STORM_HOME/bin/storm jar --jar ~/.m2/repository/com/google/code/gson/gson/2.8.6/gson-2.8.6.jar,~/.m2/repository/org/elasticsearch/client/elasticsearch-rest-client/7.6.1/elasticsearch-rest-client-7.6.1.jar target/drs-1.0-SNAPSHOT.jar com.javacodegeeks.topology.FlightPlanIndexingTopology
4.7 EsIndexBolt
The Storm API provides a ready-made bolt to index JSON data to ElasticSearch. The Storm-ElasticSearch integration is described briefly here. Here is the new FlightPlanIndexingTopologyBuilder.build() method implementation:
public static StormTopology build() {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout", new FlightDataReaderSpout());
EsConfig esConfig = new EsConfig("http://localhost:9200");
EsTupleMapper tupleMapper = new DefaultEsTupleMapper();
EsIndexBolt indexBolt = new EsIndexBolt(esConfig, tupleMapper);
builder.setBolt("indexBolt", indexBolt).shuffleGrouping("spout");
return builder.createTopology();
}
EsIndexBolt streams tuples directly into ElasticSearch. Tuples are indexed in specified index & type combination. Users should make sure that EsTupleMapper can extract source, index, type, and id from the input tuple. index and type are used for identifying target index and type; in our case index="flight" and type="_doc". source is a document in JSON format string that will be indexed in ElasticSearch. Now you understand why we used the same schema for the tuples emitted by our FlightDataReaderSpout.
You need to do some modifications to your pom.xml and settings.xml to be able to download the new dependencies. In your pom.xml add the following dependencies:
<!-- https://mvnrepository.com/artifact/org.apache.storm/storm-elasticsearch -->
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-elasticsearch</artifactId>
<version>2.2.0</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch-storm</artifactId>
<version>7.9.0</version>
</dependency>
making sure you use the same version for elasticsearch-storm as the ElasticSearch instance that you use. You need to add the https://mvnrepository.com/artifact/ repository too:
<repositories>
<!-- Repository where we can found the storm dependencies -->
<repository>
<id>central</id>
<url>https://mvnrepository.com/artifact</url>
</repository>
</repositories>
or alternatively in your settings.xml:
<mirrors>
<mirror>
<id>other-mirror</id>
<name>Other Mirror Repository</name>
<url>https://mvnrepository.com/artifact</url>
<mirrorOf>central</mirrorOf>
</mirror>
</mirrors>
Don’t forget to delete ElasticSearchBolt as it is now replaced by EsIndexBolt.
If you execute your topology, you will receive an error like the following:
org.elasticsearch.client.ResponseException: PUT http://localhost:9200/flight/_doc/3420420 HTTP/1.1 406 Not Acceptable{"error":"Content-Type header is not supported","status":406}
You will not find an answer for this error on the Internet. However, taking a closer look at the error, you realise that the problem lies with the header. If you recall from part 2, ElasticSearch expects Content-Type: application/json, not text/plain. Reading EsConfig’s API we will realise that we can do something like the following:
EsConfig esConfig = new EsConfig("http://localhost:9200");
Header[] headers = new Header[1];
headers[0]= new BasicHeader(HttpHeaders.CONTENT_TYPE, "application/json");
esConfig.withDefaultHeaders(headers);
EsTupleMapper tupleMapper = new DefaultEsTupleMapper();
...
You also need to add one more dependency to your pom.xml in order to find org.apache.http.Header.
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.13</version>
</dependency>
This time you should be able to see the 5900 flights being added to your ElasticSearch flight index, if you run the topology again. No need to write your own bolt to store data to ElasticSearch.
4.8 Parallelism
The above topology operates in a serial fashion, processing one flight at a time. We need to process multiple flights at a time, so we’ll introduce parallelism into our topology.
builder.setSpout("spout", new FlightDataSpout(), 1);
The additional parameter we provide to setSpout() is the parallelism hint; it tells Storm how many executors (threads) to create. We can do the same for the bolts:
builder.setBolt("indexBolt", indexBolt, 4).shuffleGrouping("spout");
It tells Storm to create 1 executor for the spout and 4 executors for the supervisor and run 1 task (instance) of the spout and 4 tasks of the bolt. If we use more than one executors for our spout, our bolts will receive the same tuple more than once (unless the spouts process different data).
By default, the parallelism hint is setting both the number of executors and tasks to the same value. We can override the number of tasks like so:
builder.setBolt("indexBolt", indexBolt, 4).setNumTasks(16).shuffleGrouping("spout");
Setting the number of tasks (instances) to a value high enough allows us to keep up with increasing load without the need to stop and restart our topology. This means that we can have up to 16 instances of this bolt that can process tuples in parallel (in 4 threads).
5. Monitoring the Storm cluster
Storm provides a web UI to monitor the cluster. In the nimbus machine issue the command inside $STORM_HOME directory:
bin/storm ui
By default, the Storm UI starts on the 8080 port of the machine where it is started, but you can change this port by adding the following setting in conf/storm.yaml:
ui.port: 8082
Give the URL http://localhost:8080 or the IP:port of the nimbus machine and the monitoring page will appear:
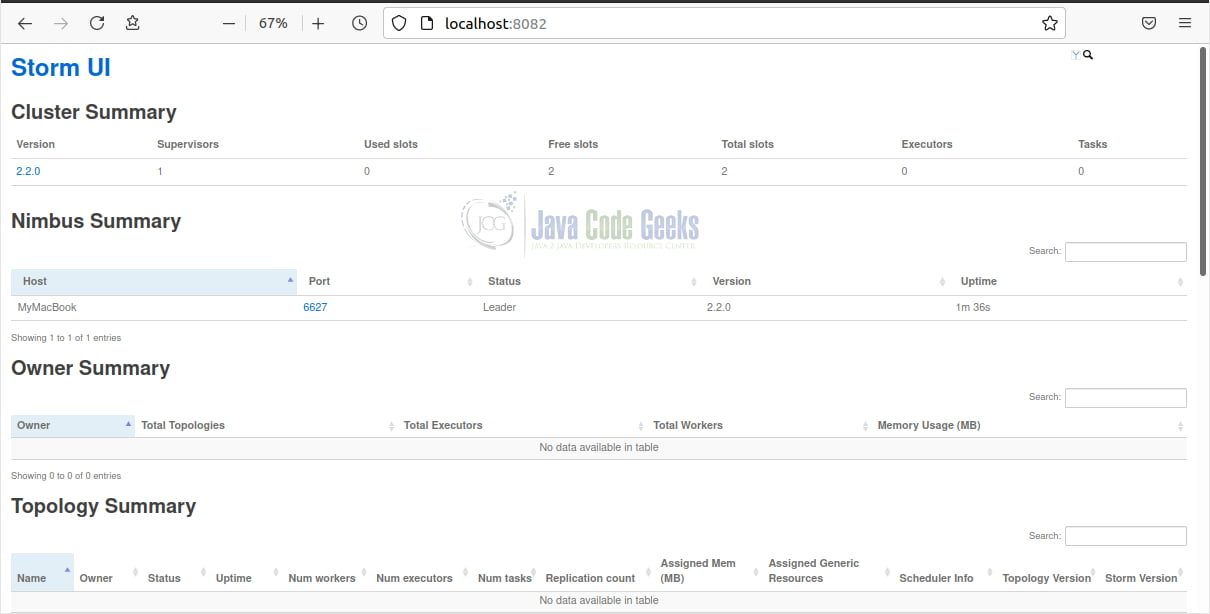
Monitoring is used to track the health of various components that are running in a storm cluster and can be used to spot an error or bottleneck in a cluster. In the homepage you can find a summary of the cluster, of nimbus configuration as well as of the topology and supervisors. A slot corresponds to a worker process, so a cluster with two used slots means there are two worker processes running on that cluster. When submitting a topology to the cluster, the user first needs to make sure that the value of the Free slots column should not be zero, otherwise, the topology will wait in the queue till a worker becomes free. In Figure 8 both slots (workers) are available as we haven’t submitted our topology yet.
To be able to see our topology in the UI, you need to replace LocalCluster with StormSubmitter like in the following code (and comment out any references to localCluster) — more information here:
StormSubmitter.submitTopology(TOPOLOGY_NAME, conf, topology);
After building drs-storm maven project:
$ $STORM_HOME/bin/storm jar --jar /home/john/.m2/repository/com/google/code/gson/gson/2.8.6/gson-2.8.6.jar,/home/john/.m2/repository/org/elasticsearch/client/elasticsearch-rest-client/7.6.1/elasticsearch-rest-client-7.6.1.jar target/drs-1.0-SNAPSHOT.jar com.javacodegeeks.topology.FlightPlanIndexingTopology
Running: /usr/lib/jvm/java-11-openjdk-amd64/bin/java -client -Ddaemon.name= -Dstorm.options= -Dstorm.home=/home/john/Apps/Search/apache/storm/2.2.0 -Dstorm.log.dir=/home/john/Apps/Search/apache/storm/2.2.0/logs -Djava.library.path=/usr/local/lib -Dstorm.conf.file= -cp /home/john/Apps/Search/apache/storm/2.2.0/*:/home/john/Apps/Search/apache/storm/2.2.0/lib-worker/*:/home/john/Apps/Search/apache/storm/2.2.0/extlib/*:target/drs-1.0-SNAPSHOT.jar:/home/john/Apps/Search/apache/storm/2.2.0/conf:/home/john/Apps/Search/apache/storm/2.2.0/bin:/home/john/.m2/repository/com/google/code/gson/gson/2.8.6/gson-2.8.6.jar:/home/john/.m2/repository/org/elasticsearch/client/elasticsearch-rest-client/7.6.1/elasticsearch-rest-client-7.6.1.jar -Dstorm.jar=target/drs-1.0-SNAPSHOT.jar -Dstorm.dependency.jars=/home/john/.m2/repository/com/google/code/gson/gson/2.8.6/gson-2.8.6.jar,/home/john/.m2/repository/org/elasticsearch/client/elasticsearch-rest-client/7.6.1/elasticsearch-rest-client-7.6.1.jar -Dstorm.dependency.artifacts={} com.javacodegeeks.topology.FlightPlanIndexingTopology
...
18:21:02.120 [main] INFO o.a.s.StormSubmitter - Uploading topology jar target/drs-1.0-SNAPSHOT.jar to assigned location: /tmp/storm-data/nimbus/inbox/stormjar-b13f69ff-d6cf-4fc3-a8a2-78826fff52e0.jar
18:21:02.823 [main] INFO o.a.s.StormSubmitter - Successfully uploaded topology jar to assigned location: /tmp/storm-data/nimbus/inbox/stormjar-b13f69ff-d6cf-4fc3-a8a2-78826fff52e0.jar
18:21:02.824 [main] INFO o.a.s.StormSubmitter - Submitting topology es-index-flights in distributed mode with conf {"flightData":"\/home\/john\/Projects\/drs-storm\/src\/main\/resources\/flightdata\/2016-07-01-1300Z.json","storm.zookeeper.topology.auth.scheme":"digest","storm.zookeeper.topology.auth.payload":"-5802937452142575860:-6341735294181236699","topology.workers":2,"topology.debug":true}
18:21:03.524 [main] INFO o.a.s.StormSubmitter - Finished submitting topology: es-index-flights
$ jps
4504 Supervisor
4553 UIServer
4475 Nimbus
After submitting the FlightPlanIndexingTopology to the cluster, you see it under the Topology Summary section (see Figure 9). Notice that there are now 2 used and no available slots under Supervisor Summary.
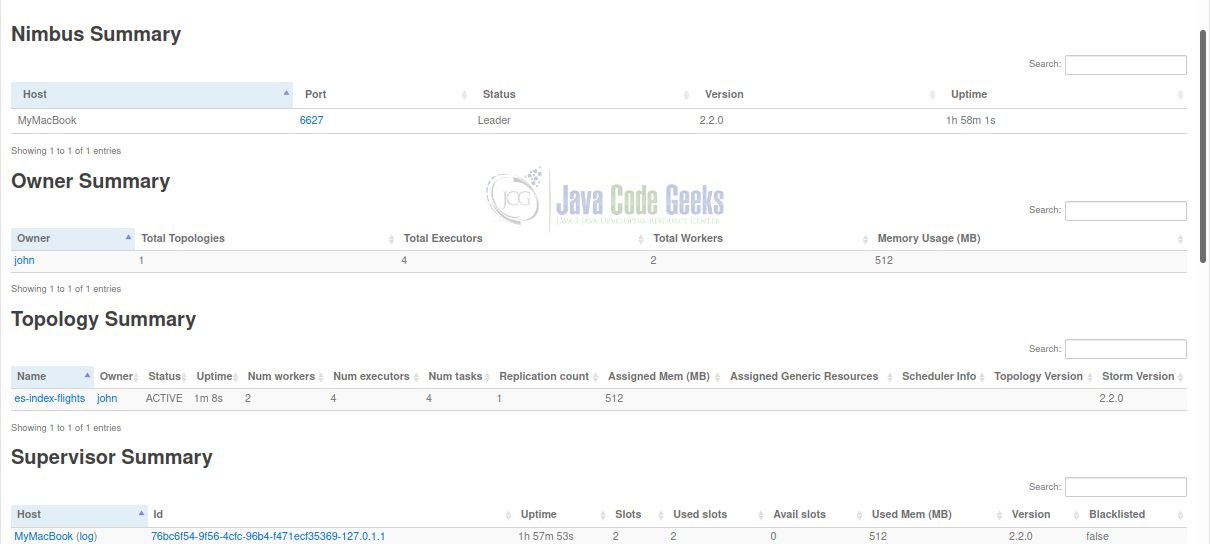
Clicking on the es-index-flights hyperlink takes you to a page where you can see more detailed statistics for the topology itself, as well as of its spouts and bolts. You can also deactivate, rebalance and even kill the topology by clicking on the respective buttons.

The sections about the spouts and bolts provide useful information about the number of executors and how many tasks are assigned to them, as well as the latency (in ms). More details appear when you click on the respective hyperlinks.
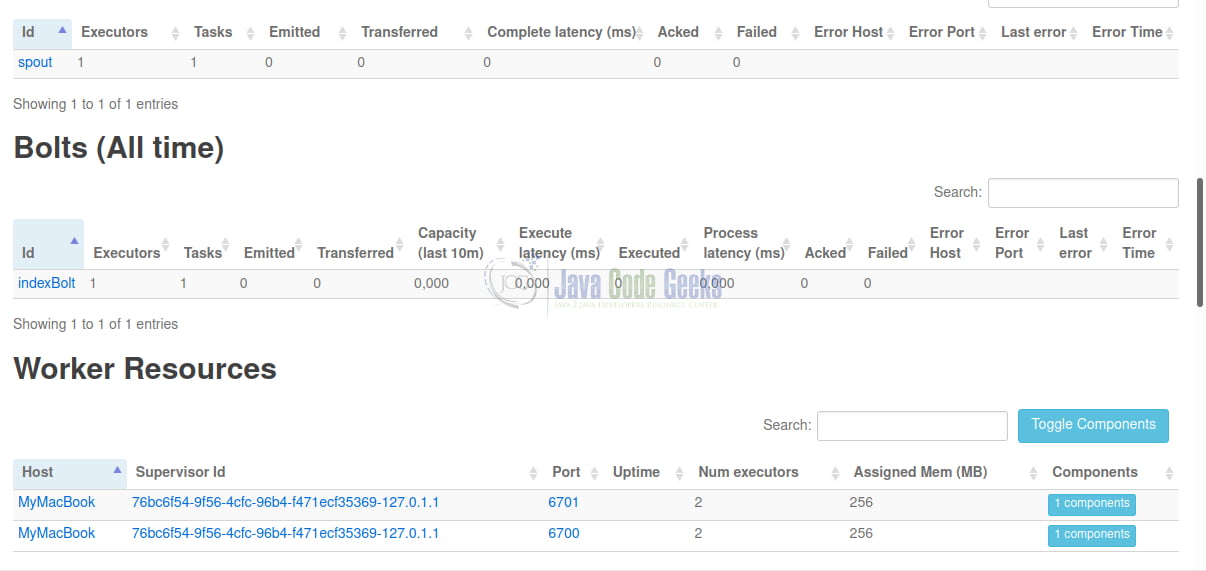
You may find more information about the various pages and sections of the UI here.
Also, avoid modifying storm.yaml while Storm is running otherwise you may receive the following Exception when running the UI:
org.apache.storm.utils.NimbusLeaderNotFoundException: Could not find leader nimbus from seed hosts
If you encounter the above error, then shutdown storm and try the following:
$ZK_HOME/bin/zkCli.sh -server localhost:2181 [zk: :2181(CONNECTED) 0]ls / [storm, zookeeper] [zk: :2181(CONNECTED) 1]deleteall /storm [zk: :2181(CONNECTED) 2]quit
If you are not satisfied by the Storm UI, you may write your own using Apache Thrift API, which is an IDL (Interface Definition Language) and binary communication protocol used for defining and creating services for numerous programming languages developed by Facebook for “scalable cross-language services development”. Storm exposes all its functionality via Thrift. More information on how to do this can be found in the references.
Storm can also be integrated with JMX and Ganglia to monitor the cluster.
6. Reliability
How is reliability achieved in Storm? You have already seen some of the techniques. We will summarize them here. Our flight data do not need to be processed reliably; if we miss a flight point, the next one will arrive from the sensor in a few ms or seconds. No big deal. For other kind of businesses, though (e.g. twits or e-commerce data) each event is important and cannot be lost.
Actually, there are three degrees of reliability processing:
- At-most-once (no single tuple ever gets processed more than once, i.e. no replaying or no reliability if processing of the tuple fails)
- At-least-once (guarantee that every single tuple must be processed successfully at least once; it is OK if it is processed more than once; you need a reliable spout with a reliable data source and an anchored stream with acknowledged or failed tuples)
- Exactly-once (guarantees that every tuple is processed successfully but once a tuple is processed, it can’t be processed ever again; you need the same as the previous category but you also need logic in your bolt(s) to guarantee tuples are processed only once.)
There can be many things go wrong. E.g. the spout cannot process the events fast enough, or the spout fails, or nimbus fails, or the bolts can’t process the input tuples fast enough, or the bolt fails or the supervisor fails, or ElasticSearch fails, or …
A tuple is considered “fully processed” when every tuple in its tree has been processed, and every tuple has to be explicitly acknowledged by the bolts. Storm maintains a link between the original tuple and its child tuples with what is called anchoring. This is achieved:
- in the spout by
- providing an id to each emitted tuple (
outputCollector.emit(values, id);) and - by implementing the
ack()andfail()methods.
- providing an id to each emitted tuple (
- In the bolt by sending a success or failure when processing the tuple. The
IBasicBoltinterface is very convenient because it sends an acknowledgement automatically after the completion of theexecute()method.
For example, if a flight is not processed successfully, then we need to re-process it again. If it is stored in a file, like in our example, then we need to re-read it from the file, or better from the memory storage that we have stored the flight data in. If we receive them real-time, then we need to store them to a buffer or queue and only remove them from the queue when it is processed successfully. In our example we don’t implement any of these, and they are left as an exercise to the interested reader. In the next part we will see how we can achieve this with the help of a messaging queue like Apache Kafka.
7. Design Strategies
How do you decompose your problem into components a.k.a. spouts and bolts? There are two ways:
- Design by breakdown into functional components. Decompose the topology according to the principle of single responsibility, i.e. into separate bolts by giving each bolt a specific responsibility. It makes it easy to scale a single bolt without interference from the rest of the topology because parallelism is tuned at the bolt level. However, creating too many bolts has also drawbacks. Remember that tuples will be sent from one bolt to another across the network which is an expensive operation. E.g. following this design proposal our topology should be like in the following figure:
- Design by breakdown into components at points of repartition. In this strategy we decompose the topology in terms of separation points (or join points) between the different components. In other words, we think of the points of connection between the different bolts, a.k.a the stream groupings (as the groupings define how the outgoing tuples from one bolt are distributed to the next). At these points, the stream of tuples flowing through the topology gets repartitioned. With this pattern of topology design, we strive to minimize the number of partitions within a topology. If we can have functionality that can be performed by one bolt without affecting performance, then we could merge 2 or more bolts to one. E.g. we chose to merge the functionality of adding a
Locationfield as well as processing the date fields in the spout, contrary to the previous design paradigm which proposes to use separate bolts for these processing tasks. However, if we had a functionality that requires high processing or requires fetching data from a remote source, e.g. call a REST service to calculate theLocation, then it would be better to leave this functionality in its own bolt. High latency tasks should be done in separate bolts.
8. Summary
In this article we learned how to use Apache Storm in order to process and import the .json flight data batch files to ElasticSearch.
Storm is stateless. For stateful stream processing one can use Trident. Trident is a high-level abstraction built on top of Storm. It allows us to express a topology in terms of the “what” as opposed to the “how”. It has operations, instead of bolts, that are applied to streams of batches of tuples. The main advantage of using Trident is that it will guarantee that every message that enters the topology is processed only once. Trident processes the input stream as small batches to achieve processing it exactly once. Trident is not recommended for high-performance use cases, because it adds complexity on Storm and manages the state.
In the next article we will see how we can integrate Apache Storm with Apache Kafka to process our flight data. Why yet introduce another layer to our architecture you will complain? Isn’t it complex enough?
As you may know by now, Storm provides guaranteed event/message processing, which means every event/message that enters the Storm topology will be processed at least once (and if you use Trident, only once). However, data loss is possible at the spout. This happens if the processing capacity of the spout is less than the producing capacity of the data publisher. E.g. the spout may not be able to keep up with processing the flight data events arriving to it from the sensors. To avoid data loss at the spout, we generally publish the data into a messaging queue, and the spout will use that messaging queue as the data source. This is why we need Apache Kafka (or another messaging system).
9. Acknowledgments
I would like to acknowledge the contribution of Serkan Toprak and Katelijne Vandenbusshe for the initial idea as well as the initial code samples, for this series of articles, whom I sincerely thank.
10. References
- Apache Storm tutorial.
- Apache Storm tutorial, Tutorialpoint.
- Zookeeper Getting Started Guide.
- Allen S. T. et al. (2015), Storm Applied, Manning.
- Ashraf U. (2018), “Apache Storm is awesome. This is why (and how) you should be using it.”, freecodecamp.
- Jain A. (2017), Mastering Apache Storm, Packt.
- Jain A. & Nalya A. (2014), Learning Storm, Packt.
- Sek S. (2015), Processing Real-time event Stream with Apache Storm.
11. Download the source code
You can download the full source code here: Processing real-time data with Storm, Kafka and ElasticSearch – Part 5

Hello, did you finally post something about the integration of Apache Storm with Apache Kafka as you mention above?
Thank you very much.