AI coding tools promise to ship features faster than ever before. And in many ways, they deliver — until something breaks in production at 2 a.m. on a Friday. This is a grounded look at the most common failure patterns we are seeing right now: hallucinated dependencies, insecure defaults, and race conditions that only appear under real load. Not doom and gloom, but a clear-eyed post-mortem.

The promise versus the reality
A few years ago, “vibe coding” was a Twitter joke. Today it is a genuine engineering strategy at companies of every size. Developers describe a workflow where you explain what you want to an AI assistant, review the output, and ship — sometimes without reading every line. That workflow is fast. It is also, as the production data is increasingly showing, fragile.
The problem is not that AI writes bad code most of the time. It is that AI writes subtly bad code some of the time, and that subtlety is what escapes code review. A logic error that crashes instantly is easy to catch. A race condition that only surfaces under concurrent load, or a dependency that installs fine today but was registered by a threat actor last week — those are the failures that make it to production.
The numbers back this up. According to a 2026 Lightrun survey, 43% of AI-generated code changes required additional debugging after deployment. Google’s own 2025 DORA report found that AI adoption correlates with roughly a 10% increase in code instability. Meanwhile, CloudBees reported that 81% of enterprises are seeing production failures rise in step with their AI code adoption.
AI vs. human code — defect rates by category
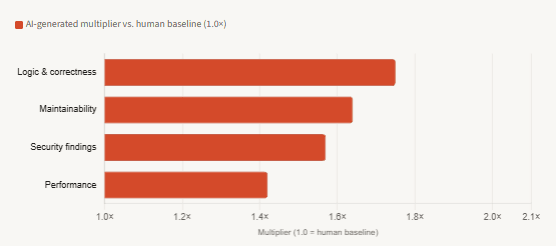
These are not minor rounding differences. A 1.75× rate on logic and correctness errors means your AI-assisted pull requests carry nearly twice the defect load on the metric that matters most: does the code do what it is supposed to do? That finding, from CodeRabbit’s analysis of 470 open-source PRs, is one of the clearest data points we have on the quality gap.
Failure pattern #1: Hallucinated dependencies (slopsquatting)
Of all the failure modes researchers are documenting right now, hallucinated package names are perhaps the most counterintuitive. The idea is straightforward: an LLM suggests an import or a dependency that does not actually exist. The name sounds completely plausible — something like aws-helper-sdk or fastapi-middleware — but no such package exists in npm or PyPI.
On its own, that is merely an annoying bug. The installation step fails, you get an error, and you move on. What makes it a security issue is what happens next. A threat actor can register that non-existent package name with a malicious payload. Because the AI keeps hallucinating the same name consistently — research from USENIX Security 2025 found that 43% of hallucinated package names are repeated across 10 separate queries — the attack surface is both predictable and persistent. This class of attack now has a name: slopsquatting.
Real incidentIn early 2024, researcher Bar Lanyado of Lasso Security observed that multiple AI models were repeatedly hallucinating a Python package called huggingface-cli. The legitimate package uses a different name entirely. Any attacker who registered that name would have had an immediate, AI-recommended install path directly into developer environments.
The scale of the underlying hallucination problem is striking. According to research presented at USENIX Security 2025, academics generated 2.23 million code samples across 16 popular models and found that open-source models hallucinated package names at an average rate of 21.7%, while commercial models averaged 5.2%. Even at the low end, that is a meaningful, persistent risk when you are running hundreds of AI-assisted sessions per week. Approximately 20% of all AI-suggested packages are hallucinated, according to Snyk’s analysis.
What the hallucinations actually look like
| Hallucination type | Share of hallucinations | Example | Detection difficulty |
|---|---|---|---|
| Pure fabrication (plausible but invented) | 51% | express-rate-guard | High |
| Conflation of two real package names | 38% | react-codeshift (jscodeshift + react-codemod) | High |
| Typo variant of a real package | 13% | lodahs instead of lodash | Medium |
Conflation hallucinations are especially dangerous precisely because they are semantically convincing. A developer reviewing AI-generated code who is unfamiliar with a specific package has no obvious signal that react-codeshift is not a widely-used, legitimate tool. That plausibility is what makes slopsquatting viable where a random typosquatting attempt might raise suspicion.
The practical fix here is straightforward: always verify every package name against the actual registry before installing, and pin your dependencies with a lockfile. Tools like Socket and Snyk can also scan your dependency tree for packages with suspicious provenance or recent ownership changes.
Verify a package exists before installing (npm)
npm info express-rate-guard 2>&1 | head -5 # If the package does not exist, npm outputs: npm error 404 Not Found
Verify a Python package (PyPI)
pip index versions huggingface-cli 2>&1 | head -5 # Output will show versions if the package exists, or an error if it does not
Failure pattern #2: Insecure defaults baked right in
Security vulnerabilities in AI-generated code are not random. They follow clear, predictable patterns rooted in what the models learned from. Training data drawn from the open internet is, frankly, full of insecure code — and without an explicit secure-coding fine-tune or security review, models reproduce what they saw.
The CodeRabbit data already showed that AI code is 1.57× more likely to introduce security findings overall. But the specific numbers by vulnerability type are even more striking. According to The Register’s coverage of the 2025 CodeRabbit benchmark, AI-generated code is 2.74× more likely to introduce XSS vulnerabilities and 1.88× more likely to implement improper password handling than human developers.
AI code security vulnerability rates by language
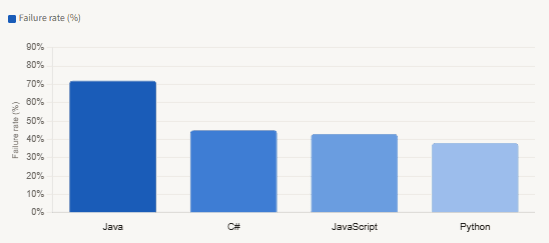
Cross-Site Scripting prevention is the single worst category in the benchmark, with an 86% failure rate across AI-generated samples. That number has not improved materially even as the underlying models have grown significantly more capable — the Spring 2026 update to the benchmark found the overall pass rate still sitting around 55%, flat since 2023.
The most common concrete patterns, according to Ranger’s 2026 analysis, include SQL injection via string concatenation instead of parameterized statements, OS command injection where user input is passed directly to system calls, and error handlers that leak stack traces and internal implementation details into HTTP responses. That last one is easy to miss in code review because the code works — it just tells an attacker more than it should when something goes wrong.
Why this happensAI models optimize for producing code that looks correct and runs. Security properties — what the code should not do — are much harder to evaluate from training examples alone. Unless you prompt explicitly for secure patterns, you will often get the fastest-looking solution, which is frequently the least hardened one.
| Vulnerability class | AI vs. human rate | Why AI generates it |
|---|---|---|
| XSS (CWE-79) | 2.74× more likely | Training data full of inline HTML rendering without sanitisation |
| Improper password handling | 1.88× more likely | Simple hash examples dominate online tutorials |
| Insecure object references | 1.91× more likely | ID-based lookups without authorisation checks are common patterns |
| Insecure deserialisation | 1.82× more likely | Convenience-first deserialization patterns are widely documented |
Failure pattern #3: Race conditions and async bugs
Race conditions are the bugs that AI tools are least equipped to handle, and for a straightforward reason: they are not visible in a single-threaded review. They require thinking about time, ordering, and concurrent access simultaneously — which is exactly the kind of multi-dimensional reasoning that degrades as context length increases. AI-generated code frequently has race conditions that only appear under production load.
A typical example involves caching. When you ask an AI to add a simple cache-aside pattern, it will usually produce textbook-looking code: check the cache, fetch from the database if missing, store the result. What it often misses is the “thundering herd” — the scenario where 200 simultaneous requests all find an empty cache at the same instant, all fire database queries, all write results, and your database falls over. The cache logic looks correct in isolation. It is only wrong under concurrent pressure.
Similarly, counter updates and toggle operations without row-level locking produce data corruption that is notoriously hard to reproduce in a local dev environment. According to a 2026 DEV Community post-mortem synthesising hundreds of production incidents, cache stampedes, connection pool exhaustion, and race conditions in like/toggle endpoints are among the most consistent failure patterns observed in AI-assisted development workflows.
“If I run this code 10,000 times, is there a thread or race condition the AI missed?” — A forced question that should precede every AI-generated async review.
The fix, in practice, is not to distrust AI for async code altogether. It is to treat concurrency as a checklist item in every AI code review. Specifically: does this function touch shared state? Does it assume ordering between async operations? Does it handle the case where it is called twice in rapid succession with the same arguments?
Check for basic thread-safety in a Python counter (verifiable)
python3 -c "
import threading
class UnsafeCounter:
def __init__(self): self.count = 0
def increment(self): self.count += 1
counter = UnsafeCounter()
threads = [threading.Thread(target=lambda: [counter.increment() for _ in range(1000)]) for _ in range(10)]
[t.start() for t in threads]
[t.join() for t in threads]
print('Expected 10000, got:', counter.count)
# Result is often less than 10000 due to lost updates
"
The velocity trap: why the risks compound
Each of the three failure patterns above is manageable in isolation. The harder problem is that vibe coding workflows tend to reduce the friction that would normally catch them. Code review cycles shrink because there is more code to review. Tests get generated by the same AI that wrote the code, so they often test only the happy path the AI modelled. And because the code looks right — well-formatted, well-named, with inline comments — reviewers tend to trust it at face value.
The numbers reflect this. A 2026 arXiv study of over 1.1 million AI-assisted public GitHub repositories found that developers consistently over-accept AI suggestions without thorough review. GitClear’s analysis of 153 million lines of code found that AI-assisted coding has led to a 4× increase in code cloning, and that — for the first time in software history — developers are now pasting code more frequently than they are refactoring or reusing it. That trend has a long tail: cloned code clones the bugs, too.
Furthermore, the Lightrun report found that every surveyed organisation requires multiple deployment cycles to validate a single AI-suggested fix. Given that a single redeploy cycle takes a day to a week on average, per Google’s DORA data, this compounds quickly. Three validation cycles on a single AI fix can push resolution from a day to several weeks — a bottleneck that wipes out a significant portion of the productivity gain that prompted the AI adoption in the first place.
What actually worksThe teams seeing the best outcomes with AI-assisted development share a common pattern: they use AI for generation and have humans review for the specific failure modes AI is bad at — security, concurrency, and dependency hygiene. They also lock dependencies, run automated SAST on every PR, and write concurrency tests before shipping async code. None of this is exotic; it is standard engineering discipline applied deliberately to AI output.
The accountability gap nobody talks about
There is one more dimension worth naming. When AI-generated code fails in production, the CloudBees survey found that only 12% of organisations have a dedicated AI governance function. Accountability defaults to CTOs and VPs of engineering 46% of the time — meaning the people farthest from the specific commit are being held responsible for failures in code they never reviewed. That is not a technical problem; it is a process one, and it is quietly adding to the stress load on engineering leadership at organisations that have moved fast with AI adoption.
The developer who shipped the PR is held accountable only 7% of the time. That distribution suggests that most organisations have not yet built the review and ownership structures that match their AI-specific failure modes. As Lightrun’s CEO put it, “Our validation processes were built for the scale of human engineering, but today, engineers have become auditors for massive volumes of unfamiliar code.” That observation is precise. And it points toward the real solution: not abandoning AI tools, but redesigning the auditing process around them.
What we learned
AI-generated code is not uniformly bad — but its failure modes are highly predictable, and most organisations are not yet structured to catch them. Hallucinated package names (slopsquatting) turn a simple import error into a live supply-chain attack vector, especially in vibe-coding environments where lockfiles are skipped and reviews are thin. Insecure defaults are systematic rather than random: the same vulnerability classes — XSS, improper authentication, insecure deserialisation — appear at elevated rates across models and languages because training data reflects the insecure patterns that dominate the open internet.
Race conditions and async bugs consistently escape AI review because they require reasoning about time and concurrency that degrades with context length. Taken together, the data tells a consistent story: AI tools increase code volume and reduce the time per line that developers spend scrutinising it, while simultaneously increasing the defect rate per line. The productivity gain is real, but so is the tax. Teams that thrive are the ones treating AI as a fast first draft that requires deliberate, structured human auditing — not a green-light shortcut.
