Idempotency Keys Are Harder Than They Look: The 5 Failure Modes Nobody Talks About
Every payment guide, every microservices tutorial, and every distributed-systems primer tells you the same thing: make your endpoints idempotent. Add an idempotency key. Store it. Check it before you act. What almost none of them explain is what happens when the storage layer has a race, the key expires during a live request, your second datacenter hasn’t seen the first write yet, or the upstream operation committed before the crash that wiped your key. This article is the treatment those guides skip.
The deceptively simple mental model
The standard idempotency key pattern looks trivially straightforward on the surface: the client generates a unique key, sends it with the request, and the server checks whether it has seen that key before. If yes, return the cached response. If no, process the operation and store the result. Job done.
The problem, however, is that this mental model compresses several distributed-systems problems into a single sentence. In practice, “check whether it has seen that key” involves a read against a storage layer that has its own consistency model. “Process the operation” can span multiple steps, any of which might fail after the key write succeeds. And “store the result” happens at a specific moment in a request lifecycle that, as it turns out, is rarely the safe moment teams assume.
A 2024 survey of over 400 backend teams found that 73% had shipped idempotency logic that failed in production under real mobile network conditions. The failures were not caused by missing documentation. They were caused by teams implementing idempotency keys “the way they’d implement any other feature: store a hash, check it, done.” That phrase captures exactly the problem. The naive pattern is not wrong in theory — it is brittle in the specific failure scenarios that production reliably produces.

Which failure modes hit production most often
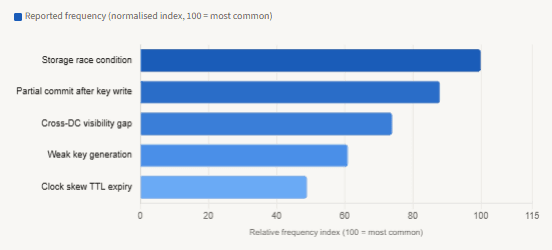
Clock skew causing key expiry mid-request
Most idempotency key implementations set a TTL on the stored key. That TTL defines the window during which retries are safe. A Stripe idempotency key, for example, is valid for 24 hours. Internal implementations in microservices commonly use shorter windows — 30 seconds, 5 minutes, 1 hour — depending on the expected client retry behaviour.
The problem emerges when the clocks on your servers diverge. NTP clock synchronisation keeps servers within a few milliseconds of each other under ideal conditions, but real production environments — especially containerised workloads on VMs — routinely see skews of tens to hundreds of milliseconds. In extreme cases involving VM live-migration or overloaded NTP servers, skews can reach several seconds.
Now consider what happens when a client sends a request near the edge of the TTL window. The application server that receives the request measures the TTL remaining using its own clock, while the storage layer (typically Redis) measures expiry against its own clock. If the storage clock is running ahead of the application server by even a few hundred milliseconds, a key that the application server judges to be valid may already be expired from Redis’s perspective. The check returns “not found” and the operation re-executes — which is exactly the duplicate you were trying to prevent.
Where this bites hardestPayment processing at peak load. During a thundering-herd retry storm — a mobile client retrying aggressively after a network drop — a large number of requests arrive close to the TTL boundary simultaneously. Clock-skew expiry during this window can produce duplicate charges at scale rather than isolated incidents.
The fix: safer TTL strategies in Java with Redis
The straightforward mitigation is to build a clock-skew buffer into your TTL logic — always subtract an estimated maximum skew from the TTL before returning a “key is valid” response. Additionally, rather than evaluating TTL validity in application code, delegate the expiry check entirely to Redis via SET NX EX atomics, which removes the application-layer clock from the equation entirely.
Java — TTL check with skew buffer using Jedis
// Build with: maven dependency jedis 5.x or lettuce 6.x
import redis.clients.jedis.Jedis;
public class IdempotencyStore {
private static final long CLOCK_SKEW_BUFFER_MS = 500L; // conservative 500ms buffer
private final Jedis jedis;
public IdempotencyStore(Jedis jedis) { this.jedis = jedis; }
/**
* Returns true if the key was newly registered (first time we have seen it).
* Returns false if the key already existed (duplicate request — skip processing).
* The SET NX EX is atomic: no separate check-then-write race possible.
*/
public boolean tryReserve(String key, long ttlSeconds) {
// Reduce effective TTL by skew buffer expressed in seconds
long safeTtl = ttlSeconds - (CLOCK_SKEW_BUFFER_MS / 1000);
if (safeTtl <= 0) throw new IllegalArgumentException("TTL too short after skew buffer");
// SET key "processing" NX EX ttl — atomic: only succeeds on first call
String result = jedis.set(key, "processing", new SetParams().nx().ex(safeTtl));
return "OK".equals(result); // "OK" = inserted (new key); null = already existed
}
}
The SET NX EX command combines the check and the write into a single atomic Redis operation. Crucially, the TTL is set by Redis itself at the moment of write, not evaluated later by application code. This eliminates the dual-clock problem almost entirely. The skew buffer then guards the edge case where a request arrives very close to a TTL boundary.
The storage layer race between key check and key write
This is arguably the most common failure mode in production idempotency implementations, and it is also the one most frequently introduced by teams who understand the intent but miss the subtlety. The naive pattern reads like this in pseudocode: check if the key exists; if it does not, process the operation and write the key. The problem is the gap between those two steps.
Under concurrent load, two requests carrying the same idempotency key can both execute the existence check at the same instant. Both find “key not found.” Both proceed to process the operation. Both write the key — but by then the duplicate transaction has already fired. In a payment system, this means two charges. In an event processor, it means two downstream events. In an inventory system, it means two decrements of stock.
“The naive check-then-act pattern has a race condition. Two concurrent requests with the same key can both pass the existence check. Every production idempotency implementation should eliminate this.”
The solution is to flip the order entirely and use a database-level INSERT with a UNIQUE constraint, or Redis SET NX, as the first operation rather than a read-then-write sequence. As Sameer Ahmed explains in detail: “When a request for key-xyz arrives, the server doesn’t SELECT anything. It immediately tries to INSERT. The database’s own internal consensus and transaction logic takes over. Only one of them can succeed.” The loser gets a unique-constraint violation, which is the signal to return the cached response rather than re-execute.
Why a database UNIQUE constraint beats application-layer lockingApplication-level locks (synchronized blocks, in-process mutexes) do not span multiple JVM instances. In a horizontally-scaled service with three pods, each pod has its own lock scope. A database unique constraint, by contrast, is enforced by the storage engine itself and is visible to all application instances simultaneously — which is exactly what you need.
Atomic reservation with a PostgreSQL unique constraint
SQL schema — idempotency_keys table
-- Run once to create the table. The UNIQUE constraint does the work.
CREATE TABLE idempotency_keys (
key VARCHAR(255) PRIMARY KEY,
status VARCHAR(32) NOT NULL DEFAULT 'processing',
response TEXT,
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
expires_at TIMESTAMPTZ NOT NULL
);
-- Index for TTL-based cleanup job
CREATE INDEX idx_idempotency_expires ON idempotency_keys (expires_at);
Java — insert-first pattern using Spring JDBC
// Throws DataIntegrityViolationException if the key already exists —
// that exception IS the signal that this is a duplicate request.
public boolean claimKey(String idempotencyKey, Duration ttl) {
try {
jdbcTemplate.update(
"INSERT INTO idempotency_keys (key, status, expires_at) VALUES (?, 'processing', ?)",
idempotencyKey,
Timestamp.from(Instant.now().plus(ttl))
);
return true; // first caller — proceed with processing
} catch (DataIntegrityViolationException e) {
return false; // duplicate key — return cached response instead
}
}
Partial failure after the key is committed
This failure mode is arguably the most damaging because it converts a temporary infrastructure failure into a permanent one. Here is the sequence: the server receives a request, writes the idempotency key with a status of “processing,” then calls the downstream payment gateway. The gateway call takes three seconds. At second two, the server crashes — JVM OOM, pod eviction, deployment rollout, whatever. The key is now in Redis or your database with status “processing,” but no result was ever committed.
When the client retries, a different server handles the request. It checks for the key, finds it with status “processing,” and — following the rules — returns a 409 Conflict to tell the client to back off and retry later. The client backs off and retries. So does the next retry. And the next. As this deep-dive describes, “you have made it permanently impossible for this specific payment to ever be processed. You have created a self-inflicted, targeted outage.”
The exact production scenario to guard againstA Kubernetes rolling deployment evicts a pod mid-request. The idempotency key was written with status “processing” 50ms before the eviction. The replacement pod never knows the original request existed. Every subsequent retry from the mobile client finds “processing” and backs off. The payment permanently fails with no error surface to the user — just silence.
Two-phase status: processing → completed (or failed)
The solution is to treat the “processing” status as a temporary lease, not a permanent marker. In the same way a distributed lock uses a TTL to handle crashes, your idempotency key should have a processing-phase TTL that is short enough to expire before the client’s retry window closes. If the key is in “processing” status and its lease has expired, the next retry should be allowed to re-claim and re-execute. Furthermore, use a two-phase status transition: write “processing” with a short TTL, then atomically update to “completed” with the stored response once the downstream call succeeds.
Java — two-phase key state machine (Spring JDBC)
// Phase 1: claim the key with a short processing TTL (e.g. 30 seconds)
// Phase 2: atomically mark complete once the downstream call succeeds
public void markCompleted(String key, String serialisedResponse) {
int rows = jdbcTemplate.update(
"UPDATE idempotency_keys SET status = 'completed', response = ? " +
"WHERE key = ? AND status = 'processing'",
serialisedResponse, key
);
if (rows == 0) {
// Either the key expired (TTL cleanup ran) or a concurrent thread already
// completed it. Log a warning — this is worth alerting on in production.
log.warn("Idempotency key not found or already completed: {}", key);
}
}
// Cleanup query: periodically re-open expired processing keys for retry
// Run as a scheduled task every 10 seconds
public void expireStaleProcessingKeys() {
jdbcTemplate.update(
"DELETE FROM idempotency_keys WHERE status = 'processing' AND expires_at < NOW()"
);
}
The cleanup query deletes stale “processing” keys, which allows their next retry to claim the key fresh and re-execute the operation. This is deliberately aggressive — when in doubt, allow re-execution rather than silently blocking. For non-idempotent downstream calls (such as payment captures), pair this with a reconciliation query to the payment gateway before re-executing, to confirm the original request did not partially succeed.
Cross-datacenter key visibility gaps
In a single-region, single-datacenter deployment, idempotency key storage is straightforward. In an active-active multi-region deployment — the architecture that most high-availability payment systems eventually graduate to — it becomes a genuinely hard distributed-systems problem.
The core issue is replication lag. When a request hits your EU datacenter and a key is written to the EU Redis cluster, that key propagates to the US cluster asynchronously. Cross-datacenter Redis replication typically operates with a lag of tens to hundreds of milliseconds under normal conditions, and can grow to seconds under network congestion or during failover events. If a client retry lands on your US cluster before replication completes — which is a near-certainty during a retry storm following a regional network event — the US cluster sees no key, judges the request as new, and executes the operation again.
| Storage topology | Cross-DC key visibility | Write latency | Suitable for payments? |
|---|---|---|---|
| Single region Redis | Immediate | <1ms intra-DC | Yes — single region only |
| Async Redis replication (active-passive) | Eventually consistent | 10–200ms cross-DC | Risky during failover |
| Active-active Redis (CRDT mode) | Eventually consistent | 10–200ms cross-DC | No — conflict-free ≠ idempotent |
| PostgreSQL with synchronous replication | Synchronous | 30–100ms cross-DC | Yes — with latency tradeoff |
| CockroachDB / Spanner (global) | Linearizable | ~100ms global | Yes — purpose-built for this |
The practical solution for most teams is not to replicate the idempotency store at all. Instead, use sticky routing at the load balancer layer: bind a given idempotency key to a specific region or shard using a consistent-hash routing policy, and ensure that all retries for that key are routed to the same region. This converts a distributed-consistency problem into a routing problem, which is substantially easier to solve reliably. The fallback — when the sticky region is unavailable — is to allow a retry window of at least twice the maximum expected replication lag before allowing cross-region re-execution.
Stripe’s approach, worth understandingStripe’s public documentation on idempotency keys acknowledges the 24-hour validity window. That window is long enough to survive most replication lag scenarios while being short enough to free up storage. More importantly, Stripe uses synchronous replication for idempotency key storage at their consistency boundary — not eventual-consistency Redis. The 24 hours is a client convenience window; the durability guarantee is enforced via synchronous writes.
Key collisions from poor generation strategies
The last failure mode is the one that looks most like a beginner mistake but shows up repeatedly in mature codebases. The quality of the idempotency key depends entirely on the quality of the generation strategy, and several common approaches have subtle failure modes that are not obvious until production.
Sequential or timestamp-based IDs
Using a counter, a Unix timestamp in milliseconds, or a combination of the two as an idempotency key seems reasonable — until you have more than one application instance. Two pods that independently increment a counter will independently produce the same sequence of integers. Two pods calling System.currentTimeMillis() at the same instant will produce the same key. The result is that genuinely different requests from different users get treated as duplicates, which is the opposite problem from the one you were solving.
Hashed payloads
Hashing the request payload to produce the idempotency key sounds clever — the key is a pure function of the request, so the client does not need to maintain any state. In practice, however, this approach has three problems. First, it stores hashed PII in your idempotency key table, creating a data-governance problem. Second, any legitimate change in the payload between retries — a corrected amount, an updated currency code — produces a new hash and a new key, bypassing idempotency entirely. Third, as Sameer Ahmed notes, two different operations that happen to produce the same hash (however unlikely) will incorrectly be treated as the same operation.
UUID v4 from a badly-seeded PRNG
UUID v4 itself is not the problem — the mathematics of 122 random bits make collisions effectively impossible in any system that could realistically be built. The problem is the random number generator underneath it. As documented in production incident reports, early versions of certain hypervisors and container runtimes seeded the VM’s PRNG with the same value at startup, especially when cloning a VM image. Two cloned VMs would then generate identical sequences of “random” UUIDs. A Kubernetes deployment that scales from 1 pod to 10 pods by cloning the same image can hit this if the container runtime’s entropy pool is not properly re-seeded at start.
UUID generation strategies — tradeoff comparison
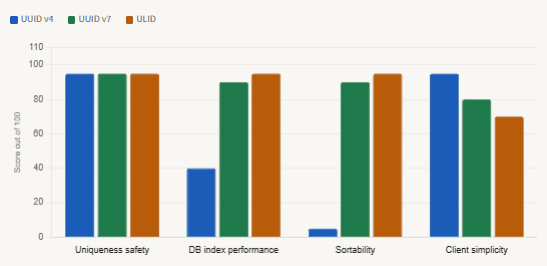
The practical recommendation, as widely agreed upon by practitioners, is to use UUID v7 where your libraries support it, falling back to UUID v4 with a verified entropy source. UUID v7 combines a millisecond-precision timestamp with random bits, making it time-ordered (which dramatically improves B-tree index performance under write load) while retaining the 122-bit randomness needed for collision safety. In Java, UUID v7 support is available from java.util.UUID in Java 24+, or through the uuid-creator library for earlier JVM versions.
Java — UUID v7 generation using uuid-creator (Maven dependency)
// Maven: com.github.f4b6a3:uuid-creator:5.x // Produces time-ordered UUID v7 — safe for B-tree indexes + collision-resistant import com.github.f4b6a3.uuid.UuidCreator; String idempotencyKey = UuidCreator.getTimeOrderedEpoch().toString(); // Example: 018f4e92-3b1a-7c4e-8f2d-1234567890ab // First 48 bits = millisecond timestamp → sequential index writes // Remaining 74 bits = random → collision-safe across distributed nodes
A production-grade checklist
Taken together, the five failure modes above are not independent — they interact. A key written into an eventually-consistent store (failure mode 4) may expire before cross-DC replication completes (failure mode 1). A system that uses SET NX EX to solve the storage race (failure mode 2) still needs two-phase status to handle partial commits (failure mode 3). None of the individual fixes is sufficient in isolation. The table below maps each failure mode to the specific defence, and notes the Java mechanisms involved.
| Failure mode | Root cause | Primary defence | Java mechanism |
|---|---|---|---|
| Clock skew TTL expiry | NTP drift between app and storage clocks | Add skew buffer; delegate TTL to storage via SET NX EX | Jedis / Lettuce atomic SET |
| Check-then-act race | Non-atomic read-then-write | Insert-first with UNIQUE constraint; catch constraint violation | Spring JDBC + DataIntegrityViolationException |
| Partial commit after key write | Process crash between key write and downstream call | Short processing TTL + two-phase status transition; cleanup job | Scheduled @Scheduled cleanup + JDBC UPDATE |
| Cross-DC visibility gap | Async replication lag in active-active stores | Sticky routing by key hash; or synchronous replication store | Load balancer consistent-hash routing; CockroachDB / Spanner |
| Weak key generation | Sequential IDs, hashed payloads, cloned-VM PRNG | UUID v7 from verified entropy; never generate server-side for client ops | uuid-creator library; Java 24+ java.util.UUID |

What we learned
Idempotency keys are not a feature you add to an endpoint — they are a system-level invariant that must hold across TTL boundaries, crash-recovery scenarios, concurrent execution, and every storage-layer consistency model your infrastructure uses. The naive check-then-act pattern fails under concurrent retries. A stored key with status “processing” becomes a zombie lock after a crash. Clock skew between your application servers and your Redis cluster can silently expire valid keys mid-request. In an active-active multi-region deployment, replication lag means a retry arriving on the wrong datacenter sees no key at all. And even the key generation itself is a trap when teams reach for sequential IDs, hashed payloads, or UUID v4 from a container runtime with a poorly-seeded PRNG.
None of these failures is exotic — they are the predictable intersection of retries, distributed clocks, and concurrent write patterns. The practical path forward is atomic reservation (insert-first, not check-then-insert), two-phase status transitions with short processing TTLs, synchronous or sticky-routed key storage for multi-region deployments, and UUID v7 as the default generation strategy in Java. Apply these together and idempotency keys become the reliable contract they were always supposed to be.
