In the realm of data management and analytics, two acronyms that often appear perplexingly similar at first glance are ETL and ELT. Standing for Extract, Transform, Load, and Extract, Load, Transform, respectively, these terms represent two distinct approaches to the movement and processing of data within an organization’s data ecosystem. While their names may suggest a mere rearrangement of steps, delving deeper reveals that they fundamentally alter the way data is handled and analyzed. In this exploration, we will unravel the intricacies of ETL and ELT, highlighting their differences, applications, and the advantages each offers. By understanding these approaches, organizations can make informed decisions to optimize their data workflows, thereby enhancing their ability to harness data for insights, decision-making, and strategic growth.
1. ETL: The Traditional Method
ETL, which stands for Extract, Transform, Load, represents the traditional and original method for moving and processing data within the realm of data warehousing and analytics. This approach has been the standard practice for several decades and is characterized by a sequential workflow of three distinct phases: Extraction, Transformation, and Loading.
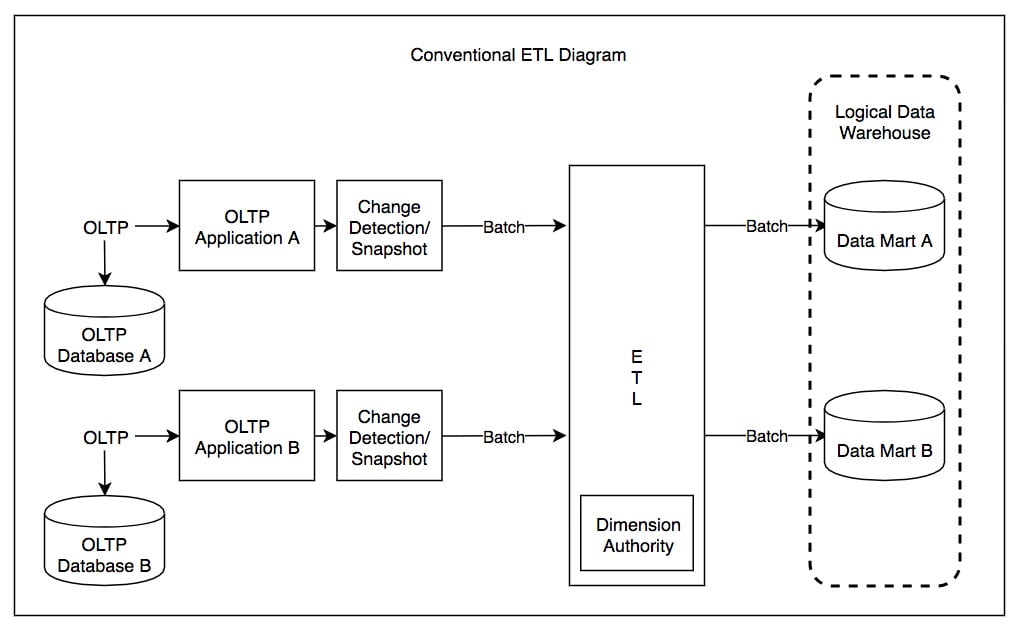
Here’s a detailed look at each phase of the ETL process:
1. Extraction (E):
- The extraction phase involves retrieving data from various source systems, which can include databases, files, external applications, APIs, and more. This data is often stored in heterogeneous formats and structures. During extraction, ETL tools or processes collect the data from these sources and transport it to a staging area.
2. Transformation (T):
- Transformation is a critical phase where the extracted data undergoes cleansing, structuring, and enrichment. This step ensures that the data is consistent, conforms to a standardized format, and meets the requirements of the target data warehouse or database. Transformations can include data validation, cleaning, aggregation, normalization, and the application of business rules and calculations. This phase is pivotal in preparing the data for meaningful analysis.
3. Loading (L):
- The final phase, loading, involves transferring the transformed data into the target data repository or data warehouse. This repository is typically designed for efficient querying and reporting. Loading can be done using various methods, such as batch processing, bulk loading, or real-time streaming, depending on the organization’s requirements and the ETL tools in use.
Advantages of ETL:
- Data Quality and Consistency: ETL processes enable data cleansing and standardization, ensuring that the data stored in the data warehouse is accurate and consistent.
- Historical Data: ETL allows organizations to capture historical data, making it available for historical analysis and reporting.
- Complex Data Transformation: ETL provides a structured approach to perform complex data transformations and calculations before loading data into the warehouse.
- Performance Optimization: By transforming data before loading, ETL can optimize the data structure for efficient querying and reporting.
Challenges of ETL:
- Latency: ETL processes are typically batch-oriented, which can introduce latency between data extraction and availability for analysis.
- Resource-Intensive: ETL processes can be resource-intensive, especially for large volumes of data, potentially leading to longer processing times.
- Complexity: Developing and maintaining ETL pipelines can be complex and may require specialized skills and tools.
Despite its long-standing presence, ETL remains a robust and reliable method for data integration and preparation, particularly for organizations that require stringent data quality and historical analysis capabilities. However, as the data landscape evolves, ELT (Extract, Load, Transform) approaches are gaining prominence, offering different advantages and addressing some of the limitations associated with traditional ETL processes.
2. ELT: The Modern Paradigm of Data Transformation
ELT, which stands for Extract, Load, Transform, represents a modern and evolving approach to data integration and processing, in contrast to the traditional ETL (Extract, Transform, Load) method. ELT reverses the sequence of the transformation phase, emphasizing the importance of loading raw data into a data warehouse or data lake first, and then performing transformations and data processing as needed.
As a modernized data processing approach, ELT strategically reverses the sequence of operations, prioritizing the direct loading of data into the data warehouse before undergoing transformation. The surge in data volume, largely attributed to the proliferation of digital sources, such as social media, mobile devices, websites, videos, images, and the Internet of Things (IoT), has necessitated this shift. It’s worth noting that the data landscape today, estimated at a staggering 328.77 million terabytes of data created daily, vastly surpasses the environment in which ETL gained prominence over three decades ago.
A notable distinction between ETL and ELT lies in the preservation of data within its original environment. ELT dispenses with the intermediate step of employing an external resource for data processing. Consequently, data remains in its native format, eliminating the need for unloading and facilitating a more robust solution capable of accommodating ever-increasing data volumes. Native communication within the ELT framework optimizes existing technologies, leading to enhanced performance, accelerated deployment, and heightened scalability.
In the ELT paradigm, the data warehouse takes on a more proactive role in data processing. This affords ELT the advantages of adaptability and cost-effectiveness. However, it’s essential to acknowledge that since data processing occurs within the same environment, processing capabilities may encounter constraints. Balancing the trade-offs between these advantages and potential limitations is a crucial consideration for organizations choosing between ETL and ELT in their data processing workflows.
Here’s an in-depth exploration of each phase of the ELT process:
1. Extraction (E):
- Similar to ETL, the extraction phase in ELT involves retrieving data from various source systems, such as databases, applications, APIs, or files. The crucial distinction is that data is extracted in its raw, unaltered form and loaded directly into a target data repository, such as a data warehouse or data lake. This approach leverages the storage and processing capabilities of these repositories to manage and analyze diverse data sources.
2. Loading (L):
- In the loading phase, raw data is ingested into the target data warehouse or data lake. This process may involve batch loading, real-time streaming, or other data ingestion methods, depending on the organization’s needs and infrastructure. The data is stored in its native format, preserving its original structure and fidelity.
3. Transformation (T):
- Unlike traditional ETL, where data transformations occur before loading, ELT emphasizes performing transformations and data processing within the data repository itself. Modern data warehouses and data lakes offer powerful processing capabilities, including SQL-based querying, data transformations, and advanced analytics. This allows organizations to work with raw data directly and apply transformations as needed to support various analytics, reporting, and business intelligence requirements.
Advantages of ELT:
- Scalability: ELT leverages the scalability of modern data repositories, enabling organizations to handle massive volumes of data efficiently.
- Flexibility: ELT allows for more flexibility in data processing, as raw data is available for a wide range of analytics and reporting tasks.
- Real-Time Insights: By loading data in near real-time, ELT enables organizations to access up-to-the-minute insights, crucial for data-driven decision-making.
- Cost-Efficiency: ELT eliminates the need for an intermediate staging area, potentially reducing storage costs and streamlining data processing pipelines.
Challenges of ELT:
- Data Complexity: Working with raw data can be more complex, as it requires careful management of data structures and schema-on-read approaches.
- Query Performance: Querying raw data without proper indexing or optimization can impact query performance, necessitating thoughtful data modeling and indexing strategies.
- Data Governance: Organizations must implement robust data governance practices to ensure data quality, security, and compliance when working with raw data.
ELT represents a modern approach to data integration and analytics that leverages the capabilities of modern data storage and processing technologies. It is particularly well-suited for organizations that prioritize scalability, real-time analytics, and cost-efficiency in their data strategies. However, the choice between ETL and ELT should align with the specific needs, infrastructure, and data ecosystem of each organization.
3. What is the Best Approach for You
Determining whether ETL or ELT is the best approach for a specific organization or project hinges on several factors, and there is no one-size-fits-all answer. The choice depends on the unique requirements, goals, and constraints of the data processing task at hand. Here are some considerations to help you decide which approach is most suitable:
Here’s a table summarizing the considerations for choosing between ETL and ELT approaches for data processing:
| Consideration | ETL (Extract, Transform, Load) | ELT (Extract, Load, Transform) |
|---|---|---|
| Data Volume and Complexity | ETL is suitable for structured data and complex data transformations. Data is cleansed and normalized before loading into the data warehouse. | ELT excels with massive volumes of raw or semi-structured data, allowing complex transformations and analytics within the data warehouse. |
| Real-Time Requirements | ETL processes are typically batch-oriented, introducing latency. | ELT can provide real-time or near-real-time analytics by loading data immediately and processing it within the data warehouse. |
| Data Warehouse Capabilities | ETL may be preferred when the data warehouse has limited processing capabilities or when data needs significant preprocessing. | ELT leverages modern data warehouses’ processing power, making it suitable when the data repository can handle complex transformations. |
| Data Governance and Security | ETL allows data cleansing and transformation before storage, ensuring data quality and consistency. | ELT processes raw data, requiring robust data governance practices to maintain quality, security, and compliance within the data warehouse. |
| Skill Set and Resources | ETL may require specialized ETL tools and expertise in data transformation processes. Organizations need to invest in these resources. | ELT relies more on the capabilities of the data warehouse, potentially requiring expertise in using those features and less specialized ETL expertise. |
| Cost Considerations | ETL may involve additional costs for ETL tools and potentially longer development timelines due to transformations. | ELT can be cost-effective, leveraging the data warehouse’s capabilities, potentially reducing the need for external ETL tools and intermediate storage. |
| Hybrid Approach Considerations | A hybrid approach can combine elements of both ETL and ELT, allowing organizations to balance advantages and address specific project requirements. | Hybrid approaches can provide flexibility, allowing organizations to choose the most suitable approach for different aspects of their data processing needs. |
The choice between ETL and ELT should be based on the specific project’s requirements, data characteristics, real-time needs, available resources, and cost considerations. Evaluating these factors carefully will help organizations make an informed decision and optimize their data processing workflows.
4. Wrapping Up
In the realm of data processing, where ETL (Extract, Transform, Load) represents the traditional approach and ELT (Extract, Load, Transform) stands as the modern alternative, the choice between them hinges on several critical factors. These factors include data volume, complexity, performance requirements, and the capabilities of the data warehouse platform in use.
ETL, born in an era when on-premise systems were the norm, exhibits certain drawbacks in today’s fast-paced data landscape. Its manual loading process is inherently slower, demanding more resources and creating bottlenecks that hinder data flow, ultimately leading to increased costs. ETL adds an additional layer of complexity and necessitates the management of multiple tools, a challenge exacerbated as organizations increasingly rely on big data.
In contrast, the emergence of the cloud and cutting-edge technologies has catapulted ELT into the limelight as the preferred order of operations. ELT is exceptionally well-equipped to handle complex data in substantial volumes across diverse platforms with remarkable efficiency. This shift, particularly embraced by enterprises, is achieved through automation and the utilization of existing information systems. ELT empowers organizations to transform data directly within the data warehouse, sidestepping the inefficiencies associated with ETL.
In essence, the sequential differences between these data processing methods are responsive to the evolving needs of the moment. As cloud adoption and multi-cloud architectures, exemplified by industry giants like Amazon and Google, continue to gain prominence, ELT’s ability to bypass the intermediate step of extracting data from its native environment for processing has made it a highly practical and efficient solution for a myriad of use cases.
The bottom line is that the choice between ETL and ELT is not a one-size-fits-all decision. Instead, it should align with the specific requirements and goals of each data processing project. While ETL holds its place in scenarios where data quality and transformation are paramount, ELT shines as a robust, versatile, and cost-effective approach well-suited for the dynamic data landscape of today and tomorrow. Organizations that adapt to this changing data processing paradigm are poised to harness the full potential of their data resources for strategic growth and innovation.
