Within an enterprise, there are services (systems really) which are widely popular, offer just what you need and are easy to use. There are also systems, which for years the organization tries to decommission but they have so many applications depending on them, so many strings attached, it seems impossible. Often, it’s the same system, at different points in time.
Recently while exploring a legacy application in order to design its Cloud native replacement, we identified a connection to such a system. We will refer to this system as the SAK (aka Swiss Army Knife). We wanted to do our part and remove one more string. The SAK’s service we consume acts in essence as a proxy for a database. After investigation, we found out that our application is the only one using the specific data (and thus the service). For the data, imagine a contact list (is not really an a contact list), which facilitates the main business offering of the application. I know I am vague, but I have to. The data in question make the main functionality easier but their lack does not make it impossible. You could still make calls without your contact list, but it would be a pain. Some clients use the application daily and some might not use it for months.
I want to bring our focus back on the essence of what we try to do: Introduce our users to a new version of our application. The new app has a quite different UI, runs on a different environment and has altered behavior in its interaction with the users. The services which the old application consumes, are replaced in the new one.
What are the requirements we extracted from business?
- Controlled and granular migration of users to the new version of the application
- Maintain the availability as described in our SLA during migration
- Data for the customer (those stored currently by SAK) must not be lost or corrupted. Lost updates by users during migration must be minimized, as it can affect the outcome of the main business function performed by users
- Easy to assign and manage clients in migration slices
- Handle possible new clients during migration
- Clear exit strategy when migration is completed
It’s a simple use case really, but a good opportunity to keep up with my writing chops. So let’s go!
We decided to view and reason about this problem as two migrations. User migration, where users will be introduced to the new application in slices and user data migration, moving their data to a database maintained by the new application. These are two very coupled migrations of course, but it helps our analysis and planning if we break it into two migrations.
User migration
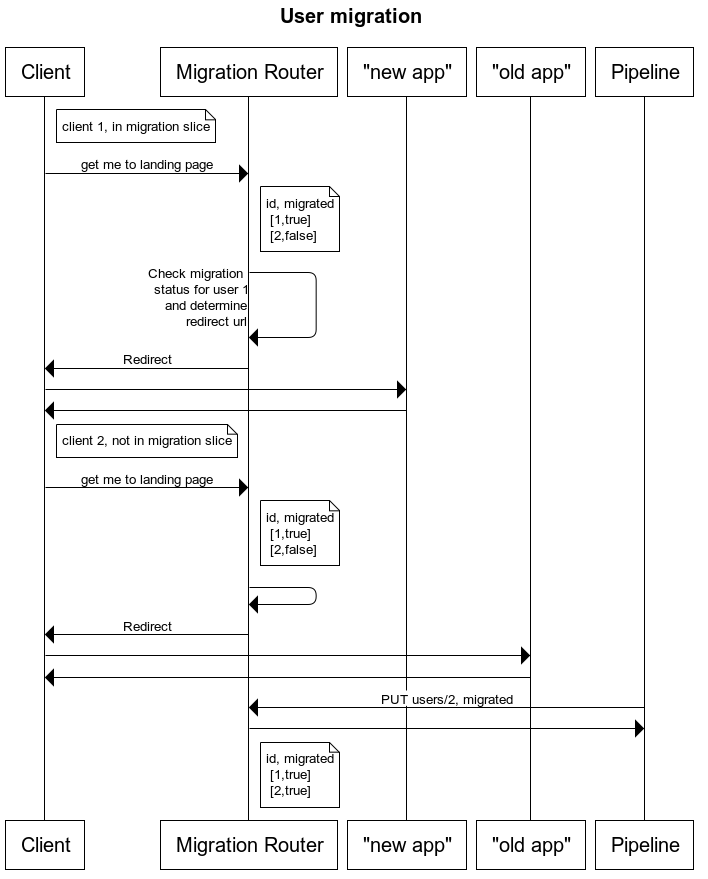
For the user migration we decided to develop a small app, called here “Migration Router”. The idea is simple. A routing app stands in front of our applications (old and new) and redirects to the landing page of either one of them based on the user.
To make the redirect decision, we would need state of the user migration status. The Migration Router, will use a database for that.
Slices of users to be migrated can be defined based on business rules. Queries on user attributes would result sets of users. In simple terms, business factors easily define user slices.
The Migration Router database is loaded with existing clients at a given time. Any new client from that point, will not be present in the database and Migration Router will direct these users to the new version of the app. Rest (known to db) clients are directed based on their migration status, here represented as a boolean. The initial status for all clients in the database is “not migrated”.
The Migration Router application exposes an endpoint to programmatically update migration status of users.
What we like about this approach: it can easily be shared and re-used by other applications. Written once, the application can be deployed in multiple spaces with no code change. All you need to change is the environment properties (urls for new and old application) and the database it connects to (with the user Ids and migration status).
Let’s see a sequence diagram to make the above more clear.
Users’ data migration
Now to migration of user data. The dataset consists of around 80K records, about 500 bytes per record. Maximum records belonging to a single customer is about 5K and the median is around 100 records. We (our team) cannot get access to the SAK’s database, neither receive a snapshot from them, for …reasons. We can either get an export with the data or access the data by calling their service.
We evaluated options for migrating data on-the-fly vs planned data migration and the level of dependency we want to have with the team that maintains SAK. We decided that our new application will not have a connection to SAK (even temporarily), we will avoid dependency from the SAK team (i.e., will call their service for migrating data) and finally, when a migrated user interacts with the application, their data will be already migrated to the database of the new application.
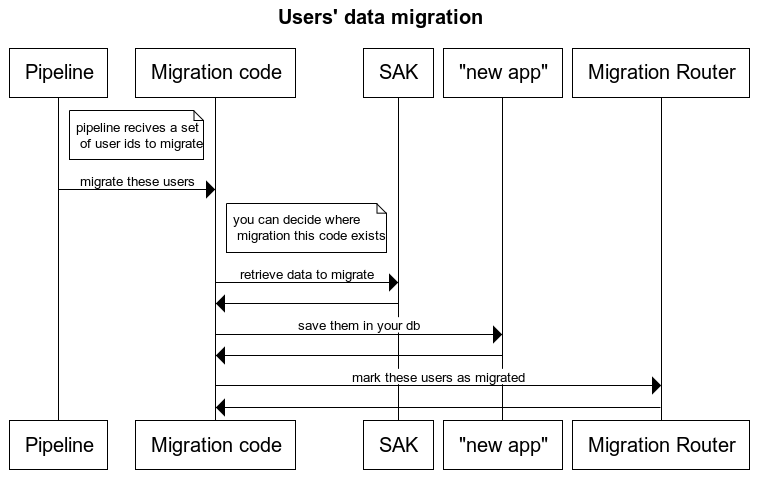
This will be done in the following steps:
- Migrate data from SAK to our new app’s database, by calling SAK’s service
- When data successfully copied to the new app database, migration router app called to update user migration status
- Initiating the migration of user data per slice, done from a pipeline, planned on out of business hours (e.g., late at night)
- Next time the user tries to access the old app, migration router will navigate them to the new app and all their user data are in its database already
Depicted in the sequence diagram below:
What about lost updates?
We are lucky in our case. Our users access the application exclusively during business hours and the dataset we have to migrate is relatively small. So our approach does not entail a considerable risk of lost updates. But let’s do a brief thought exercise. What if there was a real possibility of users altering their data while we are migrating them? How would we solve it?
We would need our database to catch up with the changes in SAK’s persistence. As we said before we cannot solve this on middleware level, we have to solve it on application level. So, after we migrated the data and the user, how do we catch up? We need to capture data changes. Again, we find ourselves dependent on SAK’s implementation. Some kind of log of changes could help so we could apply them in our database but is not available. However, there is a ‘lastUpdated’ field, so in principle we could retrieve the data again from SAK, compare with data on our side and identify inconsistencies. Of course, if our data were heavy on writes 24/7, after the user is migrated, the data in the new application (and its db) would change before catching up and issues would arise. The problem would be much more difficult to solve. Thankfully, it isn’t.
We actually did such an exercise within the context of our use case before deciding that the risk is low and we do not want to implement such controls against it. In agreement with business, we accept the risk and in the highly unlikely scenario that a lost update happens, it is still known in SAK and we could intervene to resolve conflicts in data.
Exit strategy
When all users in the Migration Router database are marked as migrated, the data migration code can be removed, the Migration Router will be removed and the calling apps will point to the new application directly. After some time and being confident about the migration, data from SAK can be removed and we will notify them that we do not use the service.
Nice and simple. Do you have better alternatives or other suggestions? Would love to hear!
Published on Java Code Geeks with permission by Tasos Martidis, partner at our JCG program. See the original article here: A tale of two migrations Opinions expressed by Java Code Geeks contributors are their own. |

Thanks for taking the time to read it!