Creating good distributed applications is not an easy task: such systems often follow the 12-factor app and microservices principles. They have to be stateless, scalable, configurable, independently released, containerized, automatable, and sometimes event-driven and serverless. Once created, they should be easy to upgrade and affordable to maintain in the long term. Finding a good balance among these competing requirements with today’s technology is still a difficult endeavor.
In this article, I will explore how distributed platforms are evolving to enable such a balance, and more importantly, what else needs to happen in the evolution of distributed systems to ease the creation of maintainable distributed architectures. If you prefer to see my talk on this very same topic, checkout my QConLondon recording at InfoQ.
Distributed application needs
For this discussion, I will group the needs of modern distributed applications into four categories — lifecycle, networking, state, binding — and analyze briefly how they are evolving in recent years.
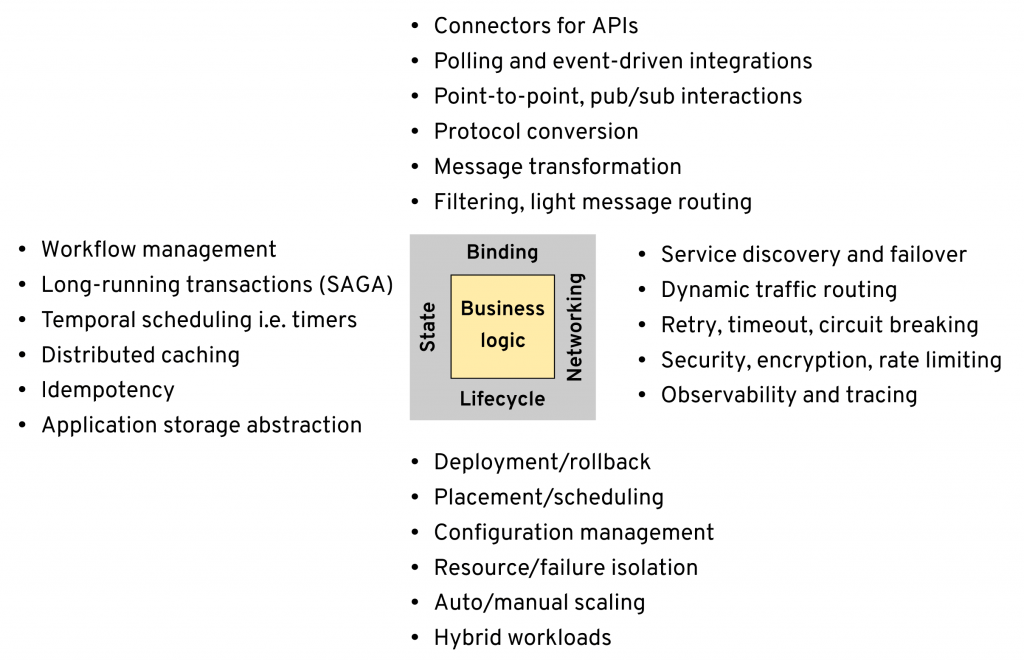
Lifecycle
Let’s start with the foundation. When we write a piece of functionality, the programming language dictates the available libraries in the ecosystem, the packaging format, and the runtime. For example, Java uses the .jar format, all the Maven dependencies as an ecosystem, and the JVM as the runtime. Nowadays, with faster release cycles, what’s more important with lifecycle is the ability to deploy, recover from errors, and scale services in an automated way. This group of capabilities represents broadly our application lifecycle needs.
Networking
Almost every application today is a distributed application in some sense and therefore needs networking. But modern distributed systems need to master networking from a wider perspective. Starting with service discovery and error recovery, to enabling modern software release techniques and all kinds of tracing and telemetry too. For our purpose, we will even include in this category the different message exchange patterns, point-to-point and pub/sub methods, and smart routing mechanisms.
State
When we talk about state, typically it is about the service state and why it is preferable to be stateless. But the platform itself that manages our services needs state. That is required for doing reliable service orchestration and workflows, distributed singleton, temporal scheduling (cron jobs), idempotency, stateful error recovery, caching, etc. All of the capabilities listed here rely on having state under the hood. While the actual state management is not the scope of this post, the distributed primitives and their abstractions that depend on state are of interest.
Binding
The components of distributed systems not only have to talk to each other but also integrate with modern or legacy external systems. That requires connectors that can convert various protocols, support different message exchange patterns, such as polling, event-driven, request/reply, transform message formats, and even be able to perform custom error recovery procedures and security mechanisms.
Without going into one-off use cases, the above represent a good collection of common primitives required for creating good distributed systems. Today, many platforms offer such features, but what we are looking for in this article is how the way we used these features changed in the last decade and how it will look in the next one. For comparison, let’s look at the past decade and see how Java-based middleware addressed these needs.
Traditional middleware limitations
One of the well-known traditional solutions satisfying an older generation of the above-listed needs is the Enterprise Service Bus (ESB) and its variants, such as Message Oriented Middleware, lighter integration frameworks, and others. An ESB is a middleware that enables interoperability among heterogeneous environments using a service-oriented architecture (i.e. classical SOA).
While an ESB would offer you a good feature set, the main challenge with ESBs was the monolithic architecture and tight technological coupling between business logic and platform, which led to technological and organizational centralization. When a service was developed and deployed into such a system, it was deeply coupled with the distributed system framework, which in turn limited the evolution of the service. This often only became apparent later in the life of the software.
Here are a few of the issues and limitations of each category of needs that makes ESBs not useful in the modern era.
Lifecycle
In traditional middleware, there is usually a single supported language runtime, (such as Java), which dictates how the software is packaged, what libraries are available, how often they have to be patched, etc. The business service has to use these libraries that tightly couple it with the platform which is written in the same language. In practice, that leads to coordinated services and platform upgrades which prevents independent and regular service and platform releases.
Networking
While a traditional piece of middleware has an advanced feature set focused around interaction with other internal and external services, it has a few major drawbacks. The networking capabilities are centered around one primary language and its related technologies. For Java language, that is JMS, JDBC, JTA, etc. More importantly, the networking concerns and semantics are deeply engraved into the business service as well. There are libraries with abstractions to cope with the networking concerns (such as the once-popular Hystrix project), but the library’s abstractions “leak” into the service its programming model, exchange patterns and error handling semantics, and the library itself. While it is handy to code and read the whole business logic mixed with networking aspect in a single location, this tightly couples both concerns into a single implementation and, ultimately, a joint evolutionary path.
State
To do reliable service orchestration, business process management, and implement patterns, such as the Saga Pattern and other slow-running processes, platforms require persistent state behind the scenes. Similarly, temporal actions, such as firing timers and cron jobs, are built on top of state and require a database to be clustered and resilient in a distributed environment. The main constraint here is the fact that the libraries and interfaces interacting with state are not completely abstracted and decoupled from the service runtime. Typically these libraries have to be configured with database details, and they live within the service leaking the semantics and dependency concerns into the application domain.
Binding
One of the main drivers for using integration middleware is the ability to connect to various other systems using different protocols, data formats, and message exchange patterns. And yet, the fact that these connectors have to live together with the application, means the dependencies have to be updated and patched together with the business logic. It means the data type and data format have to be converted back and forth within the service. It means the code has to be structured and the flow designed according to the message exchange patterns. These are a few examples of how even the abstracted endpoints influence the service implementation in the traditional middleware.
Cloud-native tendencies
Traditional middleware is powerful. It has all the necessary technical features, but it lacks the ability to change and scale rapidly, which is demanded by modern digital business needs. This is what the microservices architecture and its guiding principles for designing modern distributed applications are addressing.
The ideas behind the microservices and their technical requirements contributed to the popularization and widespread use of containers and Kubernetes. That started a new way of innovation that is going to influence the way we approach distributed applications for years to come. Let’s see how Kubernetes and the related technologies affect each group of requirements.
Lifecycle
Containers and Kubernetes evolved the way we package, distribute, and deploy applications into a language-independent format. There is a lot written about the Kubernetes Patterns and the Kubernetes Effect on developers and I will keep it short here. Notice though, for Kubernetes, the smallest primitive to manage is the container and it is focused on delivering distributed primitives at the container level and the process model. That means it does a great job on managing the lifecycle aspects of the applications, health-check, recovery, deployment, and scaling, but it doesn’t do such a good job improving on the other aspects of distributed applications which live inside the container, such as flexible networking, state management, and bindings.
You may point out that Kubernetes has stateful workloads, service discovery, cron jobs, and other capabilities. That is true, but all of these primitives are at the container level, and inside the container, a developer still has to use a language-specific library to access the more granular capabilities we listed at the beginning of this article. That is what drives projects like Envoy, Linkerd, Consul, Knative, Dapr, Camel-K, and others.
Networking
It turns out, the basic networking functionality around service discovery provided by Kubernetes is a good foundation, but not enough for modern applications. With the increasing number of microservices and the faster pace of deployments, the needs for more advanced release strategies, managing security, metrics, tracing, recovery from errors, simulating errors, etc. without touching the service, have become increasingly more appealing and created a new category of software on its own, called service mesh.
What is more exciting here is the tendency of moving the networking-related concerns from the service containing the business logic, outside and into a separate runtime, whether that is sidecar or a node level-agent. Today, service meshes can do advanced routing, help to test, handle certain aspects of security, and even speak application-specific protocols (for example Envoy supports Kafka, MongoDB, Redis, MySQL, etc.). While service mesh, as a solution, might not have a wide adoption yet, it touched a real pain point in distributed systems, and I’m convinced it will find its shape and form of existence.
In addition to the typical service mech, there are also other projects, such as Skupper, that confirm the tendency of putting networking capabilities into an external runtime agent. Skupper solves multi-cluster communication challenges through a layer 7 virtual network and offers advanced routing and connectivity capabilities. But rather than embedding Skupper into the business service runtime, it runs an instance per Kubernetes namespace which acts as a shared sidecar.
To sum up, container and Kubernetes made a major step forward in the lifecycle management of the applications. Service mesh and related technologies hit a real pain point and set the foundation for moving more responsibilities outside of the application into proxies. Let’s see what’s next.
State
We listed earlier the main integration primitives that rely on state. Managing state is hard and should be delegated to specialized storage software and managed services. That is not the topic here, but using state, in language-neutral abstractions to aid integration use cases is. Today, many efforts try to offer stateful primitives behind language-neutral abstractions. Stateful workflow management is a mandatory capability in cloud-based services, with examples, such as AWS Step Functions, Azure Durable Functions, etc. In the container-based deployments, CloudState and Dapr, both rely on the sidecar model to offer better decoupling of the stateful abstractions in distributed applications.
What I look forward to is also abstracting away all of the stateful features listed above into a separate runtime. That would mean workflow management, singletons, idempotency, transaction management, cron job triggers, and stateful error handling all happening reliably in a sidecar, (or a host-level agent), rather than living within the service. The business logic doesn’t need to include such dependencies and semantics in the application, and it can declaratively request such behavior from the binding environment. For example, a sidecar can act as a cron job trigger, idempotent consumer, and workflow manager, and the custom business logic can be invoked as a callback or plugged in on certain stages of the workflow, error handling, temporal invocations, or unique idempotent requests, etc.
Another stateful use case is caching. Whether that is request caching performed by the service mesh layer, or data caching with something like Infinispan, Redis, Hazelcast, etc., there are examples of pushing the caching capabilities out of the application’s runtime.
Binding
While we are on the topic of decoupling all distributed needs from the application runtime, the tendency continues with bindings too. Connectors, protocol conversions, message transformations, error handling, and security mediation could all move out of the service runtime. We are not there yet, but there are attempts in this direction with projects such as Knative and Dapr. Moving all of these responsibilities out of the application runtime will lead to a much smaller, business-logic-focused code. Such a code would live in a runtime independent from distributed system needs that can be consumed as prepackaged capabilities.
Another interesting approach is taken by the Apache Camel-K project. Rather than using an agent runtime to accompany the main application, this project relies on an intelligent Kubernetes Operator that builds application runtimes with additional platform capabilities from Kubernetes and Knative. Here, the single agent is the operator that is responsible for including the distributed system primitives required by the application. The difference is that some of the distributed primitives are added to the application runtime and some enabled in the platform (which could include a sidecar as well).
Future architecture trends
Looking broadly, we can conclude that the commoditization of distributed applications, by moving features to the platform level, reaches new frontiers. In addition to the lifecycle, now we can observe networking, state abstraction, declarative eventing, and endpoint bindings also available off-the-shelf, and EIPs are next on this list. Interestingly enough, the commoditization is using the out-of-process model (sidecars) for feature extension rather than runtime libraries or pure platform features (such as new Kubernetes features).
We are now approaching full circle by moving all of the traditional middleware features (a.k.a ESBs) into other runtimes, and soon, all we have to do in our service will be to write the business logic.
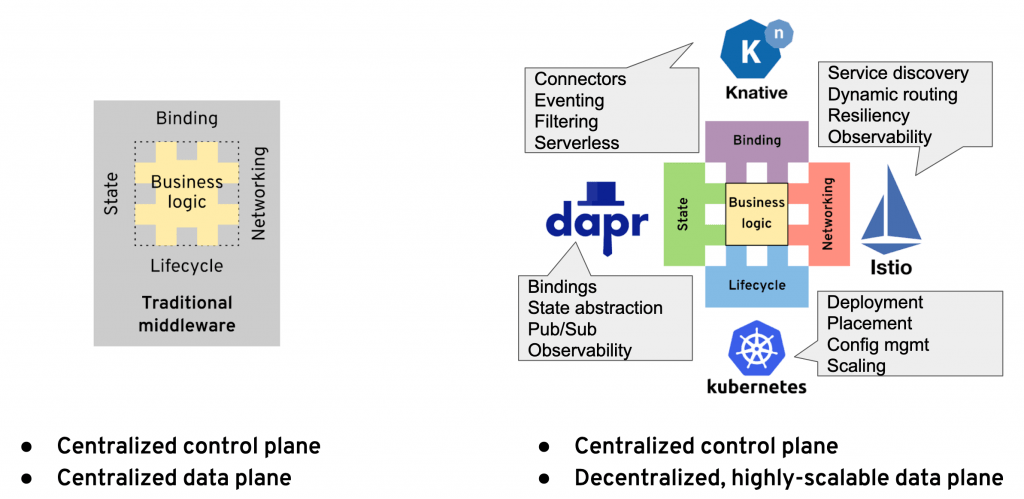
Compared to the traditional ESB era, this architecture decouples the business logic from the platform better, but not yet fully. Many distributed primitives, such as the classic enterprise integration patterns (EIPs): splitter, aggregator, filter, content-based router; and streaming processing patterns: map, filter, fold, join, merge, sliding windows; still have to be included in the business logic runtime, and many others depend on multiple distinct and overlapping platform add-ons.
If we stack up the various cloud-native projects innovating at the different domains, we end up with a picture such as the following:
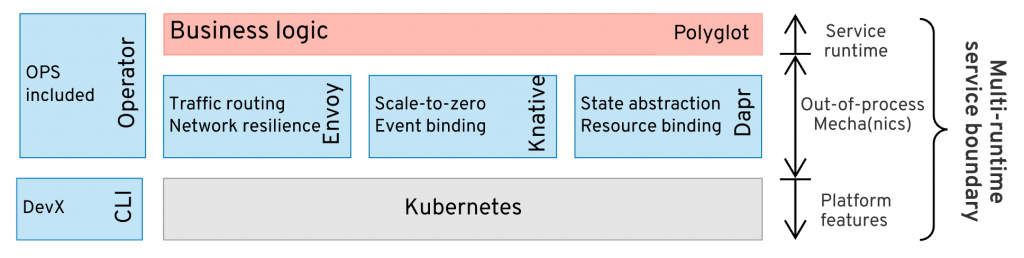
The diagram here is for illustration purposes only, it purposefully picks representative projects and maps them to a category of distributed primitives. In practice, you will not use all of these projects at the same time as some of them are overlapping and not compatible workload models. How to interpret this diagram?
- Kubernetes and containers made a huge leap in the lifecycle management of polyglot applications and set the foundation for future innovations.
- Service mesh technologies improved on Kubernetes with advanced networking capabilities and started tapping into the application concerns.
- While Knative is primarily focused on serverless workloads through rapid scaling, it also addresses service orchestration and event-driven binding needs.
- Dapr builds on the ideas of Kubernetes, Knative, and Service Mesh and dives into the application runtimes to tackle stateful workloads, binding, and integration needs, acting as a modern distributed middleware.
This diagram is to help you visualize that, most likely in the future, we will end up using multiple runtimes to implement the distributed systems. Multiple runtimes, not because of multiple microservices, but because every microservice will be composed of multiple runtimes, most likely two — the custom business logic runtime and the distributed primitives runtime.
Introducing multi-runtime microservices
Here is a brief description of the multi-runtime microservices architecture that is beginning to form.
Do you remember the movie Avatar and the Amplified Mobility Platform (AMP) “mech suits” developed by scientists to go out into the wilderness to explore Pandora? This multi-runtime architecture is similar to these Mecha-suits that give superpowers to their humanoid drivers. In the movie you have humans putting on suits to gain strength and access destructive weapons. In this software architecture, you have your business logic (referred to as micrologic) forming the core of the application and the sidecar mecha component that offers powerful out-of-the-box distributed primitives. The micrologic combined with the mecha capabilities form a multi-runtime microservice which is using out-of-process features for its distributed system needs. And the best part is, Avatar 2 is coming out soon to help promote this architecture. We can finally replace vintage sidecar motorcycles with awesome mecha pictures at all software conferences ;-). Let’s look at the details of this software architecture next.
This is a two-component model similar to a client-server architecture, where every component is separate runtime. It differs from a pure client-server architecture in that, here, both components are located on the same host with reliable networking among them that is not a concern. Both components are equal in importance, and they can initiate actions in either direction and act as the client or the server. One of the components is called Micrologic, and it holds the very minimal business logic stripped out of almost all of the distributed system concerns. The other accompanying component is the Mecha, and it provides all of the distributed system features we have been talking about through the article (except lifecycle which is a platform feature).
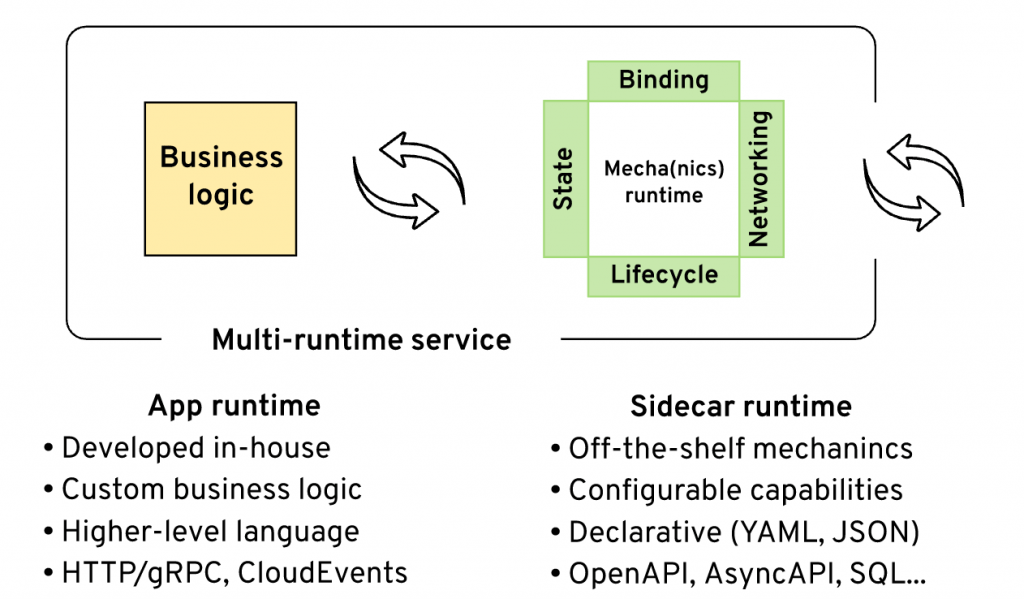
There might be a one-to-one deployment of the Micrologic and the Mecha (known as the sidecar model), or it can be one shared Mecha with a few Micrologic runtimes. The first model is most appropriate on environments, such as Kubernetes, and the latter on the edge deployments.
Micrologic runtime characteristics
Let’s briefly explore some of the characteristics of the Micrologic runtime:
- The Micrologic component is not a microservice on its own. It contains the business logic that a microservice would have, but that logic can only work in combination with the Mecha component. On the other hand, microservices are self-contained and do not have pieces of the overall functionality or part of the processing flow spread into other runtimes. The combination of a Micrologic and its Mecha counterpart form a Microservice.
- This is not a function or serverless architecture either. Serverless is mostly known for its managed rapid scaling up and scale-to-zero capabilities. In the serverless architecture, a function implements a single operation as that is the unit of scalability. In that regard, a function is different from a Micrologic which implements multiple operations, but the implementation is not end-to-end. Most importantly, the implementation of the operations is spread over the Mecha and the Micrologic runtimes.
- This is a specialized form of client-server architecture, optimized for the consumption of well-known distributed primitives without coding. Also, if we assume that the Mecha plays the server role, then each instance has to be specifically configured to work with the individual client(s). It is not a generic server instance aiming to support multiple clients at the same time as a typical client-server architecture.
- The user code in the Micrologic does not interact directly with other systems and does not implement any distributed system primitives. It interacts with the Mecha over de facto standards, such as HTTP/gRPC, CloudEvents spec, and the Mecha communicates with other systems using enriched capabilities and guided by the configured steps and mechanisms.
- While the Micrologic is responsible only for implementing the business logic stripped out of distributed system concerns, it still has to implement a few APIs at a minimum. It has to allow the Mecha and the platform to interact with it over predefined APIs and protocols (for example, by following the cloud-native design principles for Kubernetes deployments).
Mecha runtime characteristics
Here are some of the Mecha runtime characteristics:
- The Mecha is a generic, highly configurable, reusable component offering distributed primitives as off-the-shelf capabilities.
- Each instance of the Mecha has to be configured to work with one Micrologic component (the sidecar model) or configured to be shared with a few components.
- The Mecha does not make any assumption about the Micrologic runtime. It works with polyglot microservices or even monolithic systems using open protocols and formats, such as HTTP/gRPC, JSON, Protobuf, CloudEvents.
- The Mecha is configured declaratively with simple text formats, such as YAML, JSON, which dictates what features to be enabled and how to bind them to the Micrologic endpoints. For specialized API interactions, the Mechan can be additionally supplied with specs, such as OpenAPI, AsyncAPI, ANSI-SQL, etc. For stateful workflows, composed of multiple processing steps, a spec, such as Amazon State Language, can be used. For stateless integrations, Enterprise Integration Patterns (EIPs) can be used with an approach similar to the Camel-K YAML DSL. The key point here is that all of these are simple, text-based, declarative, polyglot definitions that the Mecha can fulfill without coding. Notice that these are futuristic predictions, currently, there are no Mechas for stateful orchestration or EIPs, but I expect existing Mechas (Envoy, Dapr, Cloudstate, etc) to start adding such capabilities soon. The Mecha is an application-level distributed primitives abstraction layer.
- Rather than depending on multiple agents for different purposes, such as network proxy, cache proxy, binding proxy, there might be a single Mecha providing all of these capabilities. The implementation of some capabilities, such as storage, message persistence, caching, etc., would be plugged in and backed by other cloud or on-premise services.
- Some distributed system concerns around lifecycle management make sense to be provided by the managing platform, such as Kubernetes or other cloud services, rather than the Mecha runtime using generic open specifications such as the Open App Model.
What are the main benefits of this architecture?
The benefits are loose coupling between the business logic and the increasing list of distributed systems concerns. These two elements of software systems have completely different dynamics. The business logic is always unique, custom code, written in-house. It changes frequently, depending on your organizational priorities and ability to execute. On the other hand, the distributed primitives are the ones addressing the concerns listed in this post, and they are well known. These are developed by software vendors and consumed as libraries, containers or services. This code changes depending on vendor priorities, release cycles, security patches, open-source governing rules, etc. Both groups have little visibility and control over each other.
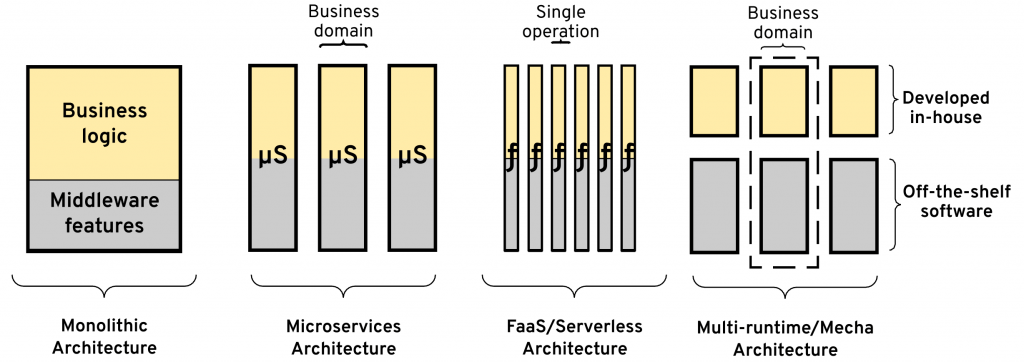
Microservices principles help decouple the different business domains by bounded contexts where every microservice can evolve independently. But microservices architecture does not address the difficulties coming from coupling the business logic with middleware concerns. For certain microservices that are light on integration use cases, this might not be a big factor. But if your domain involves complex integrations (which is increasingly becoming the case for everybody), following the microservices principles will not help you protect from coupling with the middleware. Even if the middleware is represented as libraries you include in your microservices, the moment you start migrating and changing these libraries, the coupling will become apparent. And the more distributed primitives you need, the more coupled into the integration platform you become. Consuming middleware as a separate runtime/process over a predefined API rather than a library helps loose coupling and enables the independent evolution of each component.
This is also a better way to distribute and maintain complex middleware software for vendors. As long as the interactions with the middleware are over inter-process communication involving open APIs and standards, the software vendors are free to release patches and upgrades at their pace. And the consumers are free to use their preferred language, libraries, runtimes, deployments methods, and processes.
What are the main drawbacks of this architecture?
Inter-process communication. The fact that the business logic and the middleware mechanics (you see where the name comes from) of the distributed systems are in different runtimes and that requires an HTTP or gRPC call rather than an in-process method call. Notice though, this is not a network call that is supposed to go to a different machine or datacenter. The Micrologic runtime and the Mecha are supposed to be colocated on the same host with low latency and minimal likelihood of network issues.
Complexity. The next question is, whether it is worth the complexity of development, and maintaining such systems for the gained benefits. I think the answer will be increasingly inclining towards yes. The requirements of distributed systems and the pace of release cycles are increasing. And this architecture optimizes for that. I wrote some time ago that the developers of the future will have to be with hybrid development skills. This architecture confirms and enforces further this trend. Part of the application will be written in a higher-level programming language, and part of the functionality will be provided by off-the-shelf components that have to be configured declaratively. Both parts are inter-connected not at compile-time, or through in-process dependency injection at startup time, but at deployment time, through inter-process communications. This model enables a higher rate of software reuse combined with a faster pace of change.
What comes after microservices are not functions
Microservices architecture has a clear goal. It optimizes for change. By splitting applications into business domains, this architecture offers the optimal service boundary for software evolution and maintainability through services that are decoupled, managed by independent teams, and released at an independent pace.
If we look at the programming model of the serverless architecture, it is primarily based on functions. Functions are optimized for scalability. With functions, we split every operation into an independent component so that it can scale rapidly, independently, and on-demand. In this model, the deployment granularity is a function. And the function is chosen because it is the code construct that has an input whose rate correlates directly to the scaling behavior. This is an architecture that is optimized for extreme scalability, rather than long term maintainability of complex systems.
What about the other aspect of Serverless, which comes from the popularity of AWS Lambda and its fully managed operational nature? In this regard, “AWS Serverless” optimizes for speed of provisioning for the expense of lack of control and lock-in. But the fully managed aspect is not application architecture, it is a software consumption model. It is an orthogonal functionally, similar to consuming a SaaS-based platform which in an ideal world should be available for any kind of architecture whether that is monolithic, microservices, mecha or functions. In many ways, AWS Lambda resembles a fully managed Mecha architecture with one big difference: Mecha does not enforce the function model, instead it allows a more cohesive code constructs around the business domain, split from all middleware concerns.
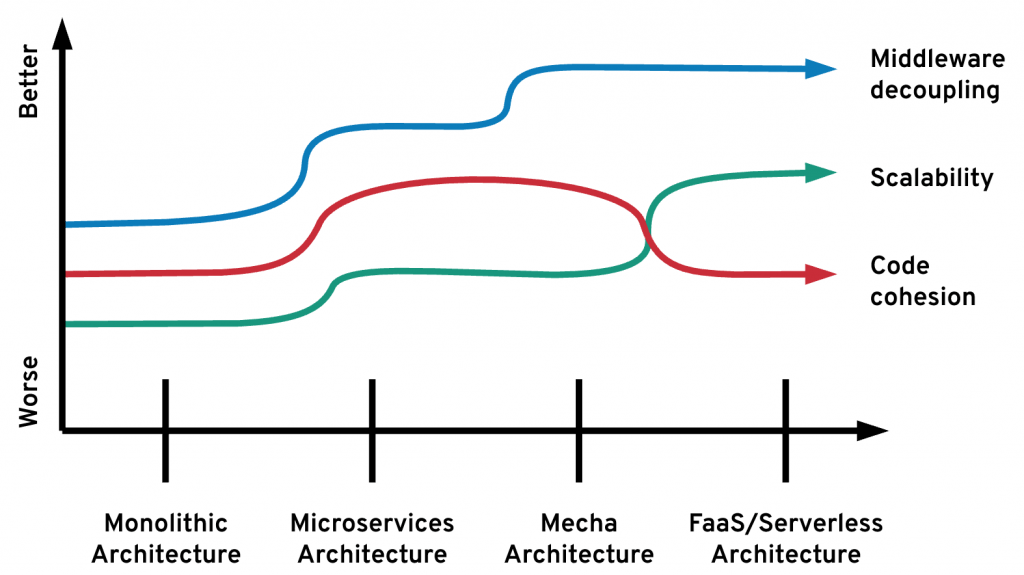
Mecha architecture, on the other hand, optimizes microservices for middleware independence. While microservices are independent of each other, they are heavily dependent on embedded distributed primitives. The Mecha architecture splits these two concerns into separate runtimes allowing their independent release by independent teams. This decoupling improves day-2 operations (such as patching and upgrades) and the long term maintainability of the cohesive units of business logic. In this regard, Mecha architecture is a natural progression of the microservices architecture by splitting software based on the boundaries that cause most friction. That optimization provides more benefits in the form of software reuse and evolution than the function model, which optimizes for extremely scalability at the expense of over-distribution of code.
Conclusion
Distributed applications have many requirements. Creating effective distributed systems requires multiple technologies and a good approach to integration. While traditional monolithic middleware provided all of the necessary technical features required by distributed systems, it lacked the ability to change, adapt, and scale rapidly, which was required by the business. This is why the ideas behind microservices-based architectures contributed to the rapid popularization of containers and Kubernetes; with the latest developments in the cloud-native space, we are now coming full circle by moving all of the traditional middleware features into the platform and off-the-shelf auxiliary runtimes.
This commoditization of application features is primarily using the out-of-process model for feature extension, rather than runtime libraries or pure platform features. That means that in the future it is highly likely that we will use multiple runtimes to implement distributed systems. Multiple runtimes, not because of multiple microservices, but because every microservice will be composed of multiple runtimes; a runtime for the custom micro business logic, and an off-the-shelf, configurable runtime for distributed primitives.
This article was originally published on InfoQ here.
Published on Java Code Geeks with permission by Bilgin Ibryam, partner at our JCG program. See the original article here: Multi-Runtime Microservices Architecture Opinions expressed by Java Code Geeks contributors are their own. |
