Everyone is aware of relation data modeling and it has served industry for long time but as data pressure increased relation data modeling that is based on Edgar_F._Codd rules are not scaling well.
Those rules were based on hardware limit in 1970s and RDMS database took all that stuff and build database that was good fit based on hardware limit of 70s.
We are in 2020 and time has changed, hardware is so much cheap and better. Look at storage price over period of time.
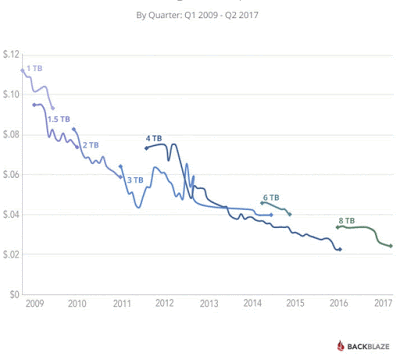
Many data system has taken advantage of cheap storage to build highly available & reliable systems. Some of RDMS are still playing catch up game. I would say NoSQL has taken lead by leveraging this.
Data modeling is very different when storage is not an issue or bottleneck, today limit is CPU because they are not getting faster, you can have more but not faster. Lets look at some of the data modeling technique that can be used today even with your favorite RDBMS to get blazing fast performance.
One thing before diving in modeling that real world is relational and data will always have relations, so any modeling technique that can’t handle 1-2-1 , 1-2-Many or Many-2-Many etc is useless. Each data model has trade off and it is designed with purpose and it could be optimizing for write or read for specific access pattern.
Few things that makes RDBMS slow are unbounded table scans , Joins and Aggregation. If we build data model that does not need these slow operation then we can build blazing fast systems!
Most of RDBMS is key value store with B-Tree index on top of it, if all the query to DB can be turned into key lookup or small index scan then we can best out of databases.
With that lets dive into some of the ideas to avoid joining Dataset.
Use non scalar attribute type
Specially for complex relationship like customer to preference, customer to address , Fedex delivery to destinations, customer to payment options etc we tend to create table to have multiple rows and then join with foreign key at read time.
If such type of request comes to your system millions time a day and then it not really good option to do join million time. What should we do then ?
Welcome to non scalar type of your data storage system use maps, list, vector or blob.
I know this may sound like crazy but just by using above stated type you have avoided join and saved big CPU cost million time. You should also know the trade off this pattern, now it is no more possible to use plan SQL to see the value of non scalar column but that is just tooling gap and can be addressed.
Code snippet for such data model
case class Customer(customerId: String, email: String, paymentOption: List[PaymentOption]) case class InternetBanking(bankName: String, userId: String, bankWebSite: URI) extends PaymentOption case class CreditCard(cardType: String, issuer: String, cardNo: Long) extends PaymentOption case class DebitCard(cardType: String, issuer: String, cardNo: Long) extends PaymentOption case class Payla(id: String) extends PaymentOption
Many join i have avoided using this pattern and user experience has improved so much with this. Database will load this column for free and you can assemble it in application layer if database does not support that.
One more thing to be aware with this is that column value should not be unbounded, put some limit and chunk it when limit is crossed to keep your favorite database happy.
Duplicate immutable attributes
This pattern need more courage to use. If you clearly know that some thing in system is immutable like product name , desc , brand , seller etc then anytime product is referred like order item refer to product that is bought then you can copy all the immutable attributes of product to order item.
case class Product(id: Long, name: String, desc: String, brand: String, price: Double)
case class OrderItem(orderId: Long, itemId: Long, noOfUnit: Int, totalPrice: Double,
productName: String, productDesc: String, productBrand: String, productPrice: Double)
Showing order details is very frequent access pattern in e-commerce site and such type of solution will help with that access pattern.
Trade off involved is that if attributes are not immutable then this has overhead of updating it whenever referenced entity is changed but if that does not changes frequently then you will benefit with this in big way.
– Single table or multi entity table
This will definitely get most resistant because seems like insult to RDBMS but we have this done in past remember those parent child query where both parent and child is stored in single table and we join with parent and id. Employee and manager was modeled like this for many years.
Lets take another example for parent & child relationship.
Class and student is also classic example where class will have many student and vice-versa.
Anytime we want to show details of all the student for specific class then we make first query to get class id and then all the student for that class or we can join based on class id.
How can we avoid join or sequential load dependency?
When we write the join query we are trying to create de-normalized view at runtime and discard it after request is served but what if this view is created at the write time then we managed to pre-join data and we just avoid the join at runtime.
case class Registration(pk1: String, pk2: String,
className: String = null, classDesc: String = null, frequency: Int = 0,
firstName: String = null, lastName: String = null)
Registration("class:C1", "class:C1", className = "Maths", classDesc = "Basic Algebra")
Registration("class:C1", "student:S1", firstName = "Student1", lastName = "Student1")
Registration("class:C1", "student:S2", firstName = "Student2", lastName = "Student2")
Registration("class:C1", "student:S2", firstName = "Student2", lastName = "Student2")
This model is using generic name(pk1,pk2) for identifying entity in single table, this looks little different but is very powerful because with pre-join data we can get answer of questions like
– Single class details ( pk1=”class:c1″ , pk2=”class:c1″)
– Single student for given class( pk1=”class:c1″ , pk2=”student:s1″ ).
– Both class and all the students (pk1=”class:c1″)
– All the student of given class (pk1=”class:c1″ , pk2!=”class:c1″)
Lets add one more scenario to get all the classes student is attending. This need just flipping pk1 and pk2 to make it something like
Registration(“student:s1”, “class:C1”, className = “science”, classDesc = “Science for Primary kids”)
Registration(“student:s1”, “class:C2”, className = “Maths”, classDesc = “Basic Algebra”)
I would say that this is one of the most different one and needs out of the box thinking to give a try but with this you can solve many use case.
– Projected column index
This is common one where projection and aggregation is done upfront and can be treated like de-normalization view at write time. If aggregation is linear like sum, avg, max , min then aggregation can be done incremental. This will avoid running Group By query for every request. Think how much CPU can be saved by using this simple pattern.
– Extreme projection index
This is extension of above pattern taking to next level by calculating projection at every level and very effective for hierarchy based query. This can help in totally avoiding group and aggregation at read time.
Conclusion
All the patterns shared are nothing new and are taking advantage of cheap storage to avoid de-normalization at read time.
If all the joins and most aggregation can be done at write time then reads are so fast that it might feel that you are not hitting any database.
In this post we did not touch on data partition strategy but that also plays important role in building system that user love to use.
Time to get little closer to your data and spend time in understanding access pattern and hardware limit before design system!
Published on Java Code Geeks with permission by Ashkrit Sharma, partner at our JCG program. See the original article here: Data modeling is everything Opinions expressed by Java Code Geeks contributors are their own. |

The Proxy Design Pattern has the same intent has the proxy servers in computer networks. In this article we will define what is proxy design pattern, walk through the implementation and also see what are the benefits of using the proxy design pattern in java.