I have previously blogged about the optimizations we are doing in the next Camel 3.1 release (part 1).
Today I wanted to post a status update on the progress we have made since, about 4 weeks later.
We have focused on optimizing camel-core in three areas:
- unnecessary object allocations
- unnecessary method calls
- improve performance
In other words we are making Camel create less objects, calling fewer methods, and improving the performance during routing.
To help identify these issues in camel-core we were using a simple Camel route:
from timer:foo
to log:foo
And other times we focused on longer routes:
from timer:foo
to log:foo1
to log:foo2
to log:foo3
…
to log:fooN
Or the focus on the bean component:
from timer:foo
to bean:foo
And so on. We also added an option to the timer component to not include metadata so the message dont contain any body, headers or exchange properties. This allowed us to focus on the pure routing engine and its overhead.
So all together this has helped identify many smaller points for improvements that collectively gains a great win.
tl:dr – Show me the numbers
Okay let’s post some numbers first and then follow up with details what has been done.
Object Allocations – (5 minute sampling)
Camel 2.25 2.9 M objects created
Camel 3.0 55 M objects created
Camel 3.1 1.8 M objects created
Okay we have to admit that Camel 3.0 has an issue with excessive object allocations during routing. There are no memory leaks but it creates a lot of unnecessary objects. And I will get into details below why.
However what is interesting is the gain between Camel 2.25 and 3.1 (40% less objects created).
Method Calls – (5 minute sampling)
Camel 2.25 139 different Camel methods in use
Camel 3.0 167 different Camel methods in use
Camel 3.1 84 different Camel methods in use
The table above lists the number of methods from Camel that Camel calls during routing. The data does not include all the methods from the JDK. As we cannot optimize those, but we can optimize the Camel source code.
As you can see from the table we have improvement. Camel 3.1 uses less than half of 3.0, and 40% less than Camel 2.2.5.
Camel 3.0
Okay so Camel 3.0 has a problem with using too much memory. A big reason is the new reactive executor which now executes each step in the routing via event looping, by handing over tasks to a queue and having workers that execute the tasks. So this handoff now requires creating additional objects and storing tasks in queue etc.
Some of the biggest wins was to avoid creating TRACE logging message which unfortunately was always created regardless if TRACE logging level was enabled. Another big win was to avoid creating toString representation of the route processes with child elements. Instead Camel now only output the id of the process which is a fast operation and dont allocate new objects.
Another problem was new code that are using java.util.stream. This is both a blessing and a curse (mostly a curse for fast code). So by using plain for loops, if structures, and avoiding java.util.stream in the critical parts of core routing engine we reduces object allocations.
Camel 3 is also highly modularised, and for example in Camel 2.x we had all classes in the same classpath and could use instanceof checks. So in Camel 3 we had some code that performed poorly doing these kind of checks (java util streams again).
Another problem was the reactive executor which was using a LinkedList as its queue. So if you have tasks going into the queue and workers processing them in the same pace, so the queue is empty/drained, then LinkedList performs poorly as it allocates/deallocates the object constantly. By switching to a ArrayQueue which has a pre-allocated size of 16 then there is always room in the queue for tasks and no allocation/deallocation happens.
There are many more optimisations but those mentioned above where likely the biggest problems. Then a lot of smaller optimisations gained a lot combined.
Many smaller optimisations
The UUID generator of Camel is using a bit of string concat which costs. We have reduced the need for generating UUIDs in the message and unit of work so we only generate 1 per exchange.
The internal advices in the Camel routing engine (advice = before/after AOP). Some of these advices has state which they need to carry over from before to after, which means an object needs to be stored. Before we allocated an array for all advices even for those whom do not have state and thus storing a null. Now we only allocate the array with the exact number of advices that has state. (very small win, eg object[6] vs object[2] etc, but this happens per step in the Camel route, so it all adds up.). Another win was to avoid doing an AOP around UnitOfWork if it was not necessary from the internal routing processor. This avoids additional method calls and to allocate a callback object for the after task. As all of this happens for each step in the routing then its a good improvement.
Some of the most used EIPs has been optimized. For example
allows you to send the message to an endpoint using a different MEP (but this is rarely used). Now the EIP detects this and avoids creating a callback object for restoring the MEP. The pipeline EIP (eg when you do to -> to -> to) also has a little improvement to use an index counter instead of java.util.Iterator, as the latter allocates an extra object
Camel also has a StopWatch that used a java.util.Date to store the time. This was optimized to use a long value.
Another improvement is the event notification. We now pre-calculate if its in use and avoid calling it all together for events related to routing messages. BTW in Camel 3.0 the event notifier was refactored to use Java 8 Supplier’s and many fancy APIs but all of that created a lot of overhead. In Camel 3.1 we have restored the notifier to be like before in Camel 2.x and with additional optimisations.
So let me end this blog by saying that …. awesome. Camel 3.1 will use less memory, execute faster by not calling as many methods (mind that we may have had to move some code which was required to be called but doing this in a different way to avoid calling too many methods).
One of the bigger changes in terms of touched source code was to switch from using an instance based logger in ServiceSupport (base class for many things in Camel), to use a static logger instance. This means that there will be less Logger objects created and it’s also better practice.
Better performance
Other improvements is that we have moved some of the internal state that Camel kept as exchange properties to fields on the Exchange directly. This avoids storing a key/value in the properties map, but we can use primitives like boolean, int etc. This also performs better as its faster to get a boolean via a getter than to lookup the value in a Map via a key.
In fact in Camel 3.1 then during regular routing then Camel doesnt lookup any such state from exchange properties which means there is no method calls. There are still some state that are stored as exchange properties (some of those may be improved in the future, however most of these states are only used infrequently). What we have optimized is the state that are always checked and used during routing.
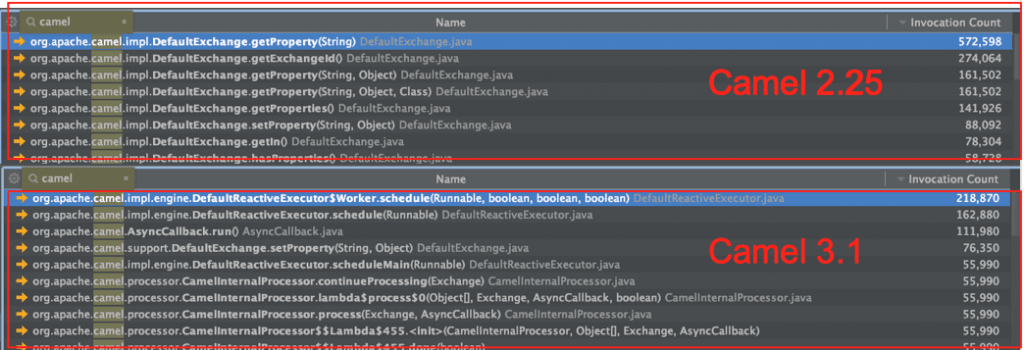
Exchange getProperty(5 minute sampling)
Camel 2.25 572598 getPropety(String)
Camel 2.25 161502 getPropety(String, Object)
Camel 2.25 161502 getPropety(String, Object, Class)
Camel 2.25 141962 getPropeties()
Camel 3.0 574944 getProperty(String)
Camel 3.0 167904 getPropety(String, Object)
Camel 3.0 167904 getPropety(String, Object, Class)
Camel 3.0 91584 getPropeties()
Camel 3.1 0 getProperty(String)
Camel 3.1 0 getPropety(String, Object)
Camel 3.1 0 getPropety(String, Object, Class)
Camel 3.1 0 getPropeties()
As you can see Camel 2.25 and 3.0 lookup this state a lot. And in Camel 3.1 we have optimized this tremendously and there are no lookup at all – as said the state is stored on the Exchange as primitive types which the JDK can inline and execute really fast.
The screenshot below shows Camel 2.25 vs 3.1. (The screenshot for 3.1 is slightly outdated as it was from yesterday and we have optimised Camel since). See screenshot below:
Okay there are many other smaller optimizations and I am working on one currently as I write this blog. Okay let me end this blog, and save details for part 3.
Published on Java Code Geeks with permission by Claus Ibsen, partner at our JCG program. See the original article here: Apache Camel 3.1 – More camel-core optimizations coming (Part 2) Opinions expressed by Java Code Geeks contributors are their own. |
