Based on our experience, we believe Round robin may not be an effective load balancing algorithm, because it doesn’t equally distribute traffic among all nodes. You might wonder how this is possible? Yes, it is possible
How Round robin algorithm works?
Round robin algorithm sends requests among nodes in the order that requests are received. Here is a simple example. Let’s say you have 3 nodes: node-A, node-B, and node-C.
• First request is sent to node-A.
• Second request is sent to node-B.
• Third request is sent to node-C.
The load balancer continues sending requests to servers based on this order. It makes to sound that traffic would get equally distributed among the nodes. But that isn’t true.
What is the problem with Round robin algorithm?
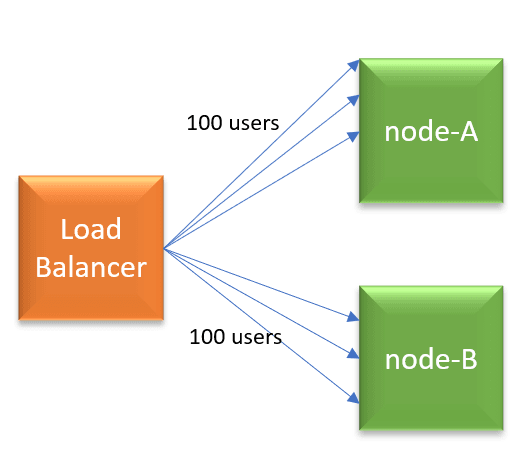
Let’s pick up a simple example. Let’s say you launched your web application with a load balancer, and it has two nodes (node-A, node-B) behind it. The load balancer is configured to run with Round robin algorithm, and sticky-session load balancing is enabled. Let’s say 200 users are using your application currently. Since the Round robin algorithm is enabled in load balancer, each node will get 100 users requests.
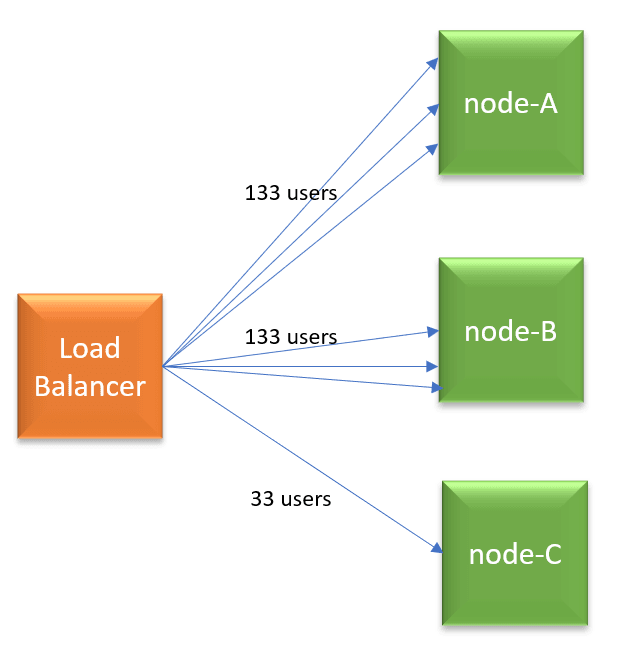
A few minutes later, you are adding node-C. Let’s say now additional 100 users start using the application. Since it’s Round robin algorithm, load balancer will distribute new users’ requests equally to all 3 nodes (i.e., 33 users request to each node). But remember node-A and node-B is already processing 100 users requests each. So now node-A and node-B will end up processing 133 users requests each (i.e., 100 original users requests + 33 new users requests), whereas node-C will process only 33 (new) users requests. Now, do you see why round-robin isn’t equally distributing the traffic? In the Round robin algorithm, always older nodes in the pool will end-up processing more requests. Newly added nodes will end up processing less amount of traffic. The load is never evenly distributed. For maintenance, patching & installation purposes, you have to continually keep adding and removing nodes from the load balancer pool. If you instrumented auto-scaling in place, problem gets worse even further. Because in auto-scaling nodes are more dynamic. They get added and removed even more frequently.
What algorithm to use?
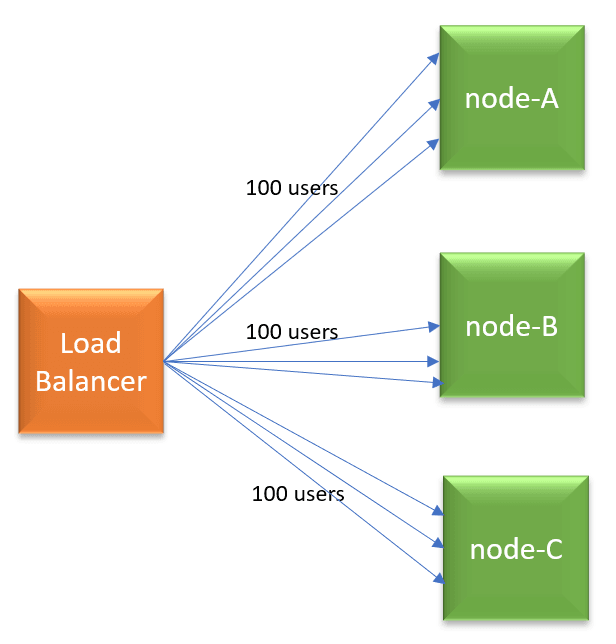
There are variety of load balancing algorithms: Weighted Round Robin, Random, Source IP, URL, Least connections, Least traffic, Least latency. Given the shortcoming in Round robin, you can consider trying other choices. One choice you may consider is: ‘Least connections‘ algorithm. As per this algorithm, the node which has the least number of connections will get the next request. Thus, as per our earlier example, when new 100 users start to use the application, all new users’ requests will be sent to node-C. Thus, load will be equally distributed among all nodes.
|
Published on Java Code Geeks with permission by Ram Lakshmanan, partner at our JCG program. See the original article here: Load balancing: Round robin may not be the right choice Opinions expressed by Java Code Geeks contributors are their own. |
