With my qualifying exam just ten days away, I’ve decided to move away from the textbook and back into writing. After all, if I can explain the concepts, I should be able to pass a test on them, right? Well, today I’m interesting in covering one of the concepts from my algorithms course: minimum spanning trees.
Minimum Spanning Trees Overview
Before we can talk about minimum spanning trees, we need to talk about graphs. In particular, undirected graphs which are graphs whose edges have no particular orientation. In other words, it’s a graph with edges that connect two nodes in both directions:
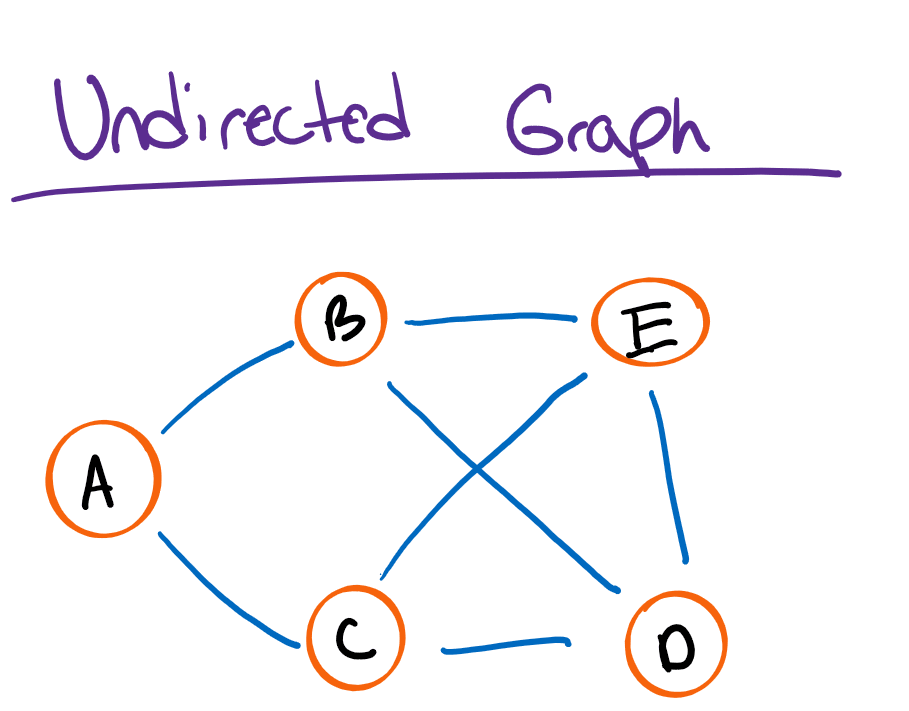
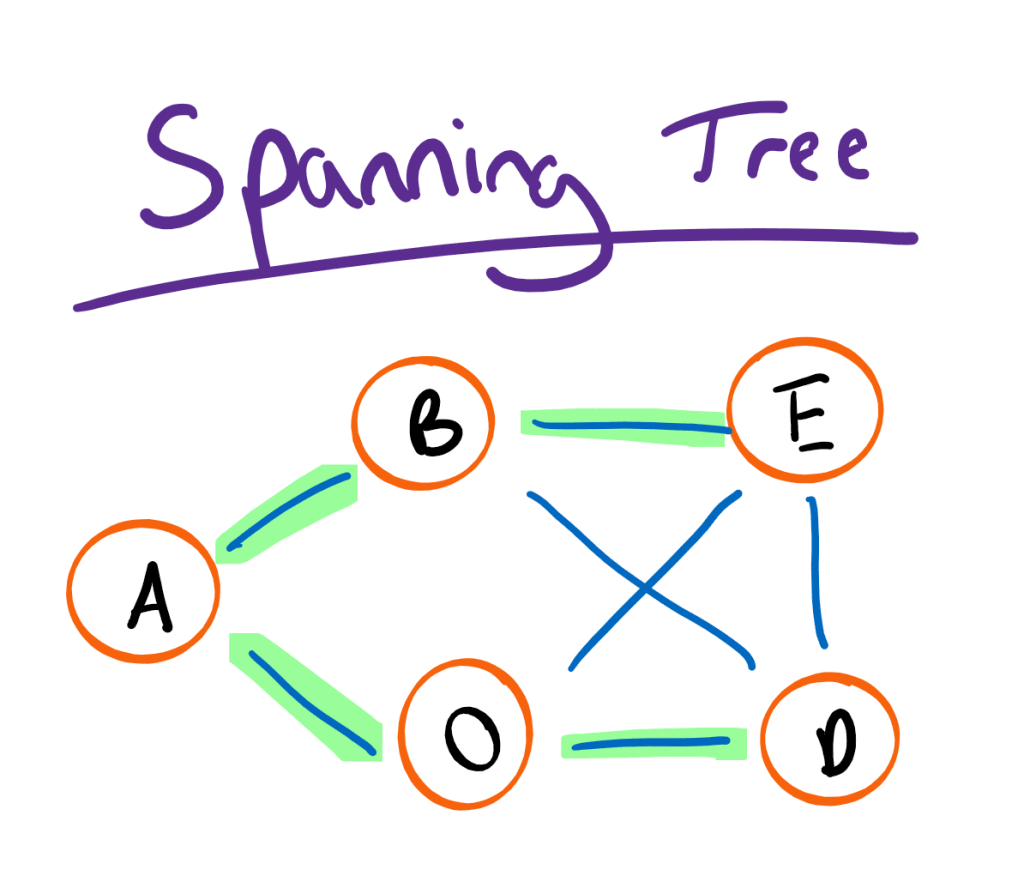
If we were to traverse an undirected graph in a special way, we could construct a tree known as a spanning tree. More specifically, a spanning tree is a subset of a graph which contains all the vertices without any cycles. As an added criteria, a spanning tree must cover the minimum number of edges:
However, if we were to add edge weights to our undirected graph, optimizing our tree for the minimum number of edges may not give us a minimum spanning tree. In particular, a minimum spanning tree is a subset of an undirected weighted graph which contains all the vertices without any cycles. Once again, the resulting tree must have the minimum possible total edge cost:
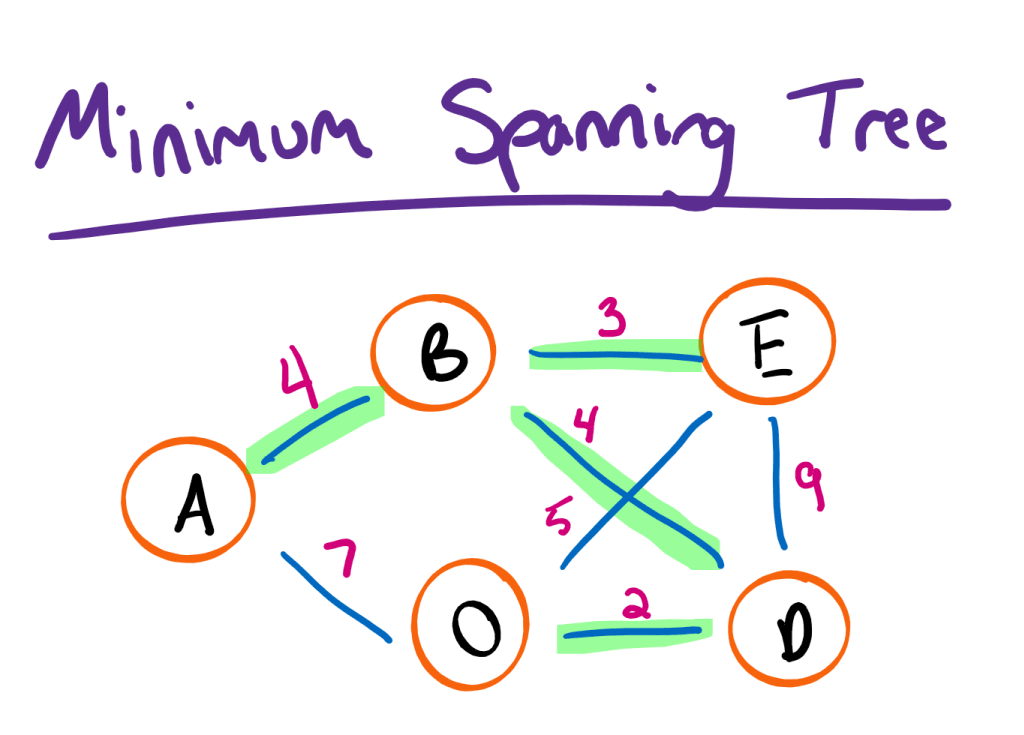
One final note: minimum spanning trees may not be unique. In other words, there may be multiple minimum spanning trees for a given graph. For example, if edge ED had cost 4, we could choose either ED or BD to complete our tree.
With that out of the way, let’s talk about what’s going on in the rest of this article. In particular, we’ll take a look at two algorithms for constructing minimum spanning trees: Prim’s and Kruskal’s.
Minimum Spanning Tree Algorithms
As mentioned already, the goal of this article is to take a look at two main minimum spanning tree algorithms. Both algorithms take a greedy approach to tackling the minimum spanning tree problem, but they each take do it a little differently.
Prim’s Algorithm
One way to construct a minimum spanning tree is to select a starting node and continuously add the cheapest neighboring edge to the tree—avoiding cycles—until every node has been connected. In essence, that’s exactly how Prim’s algorithm works.
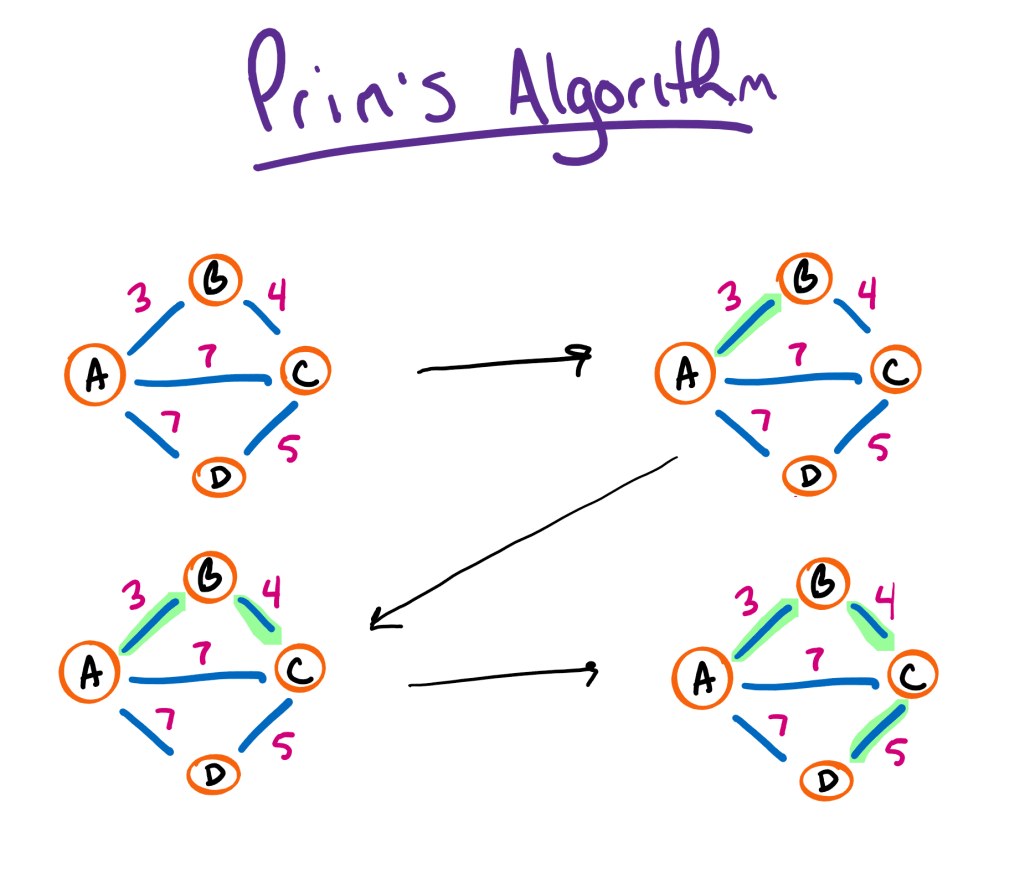
In this example, we start from A and continually expand our tree until we’ve connected all the nodes. In this case, we select AB then BC then CD. In the end, we end up with a minimum spanning tree of cost 12.
Of course, we could have always started from any other node to end up with the same tree. For example, we could have started from D which would have constructed the tree in the other direction (DC -> CB -> BA).
As you can imagine, this is a pretty simple greedy algorithm that always constructs a minimum spanning tree. Of course, there is a bit of decision making required to avoid generating cycles. That said, as long as the new edge doesn’t connect two nodes in the current tree, there shouldn’t be any issues.
Kruskal’s Algorithm
Another way to construct a minimum spanning tree is to continually select the smallest available edge among all available edges—avoiding cycles—until every node has been connected. Naturally, this is how Kruskal’s algorithm works.
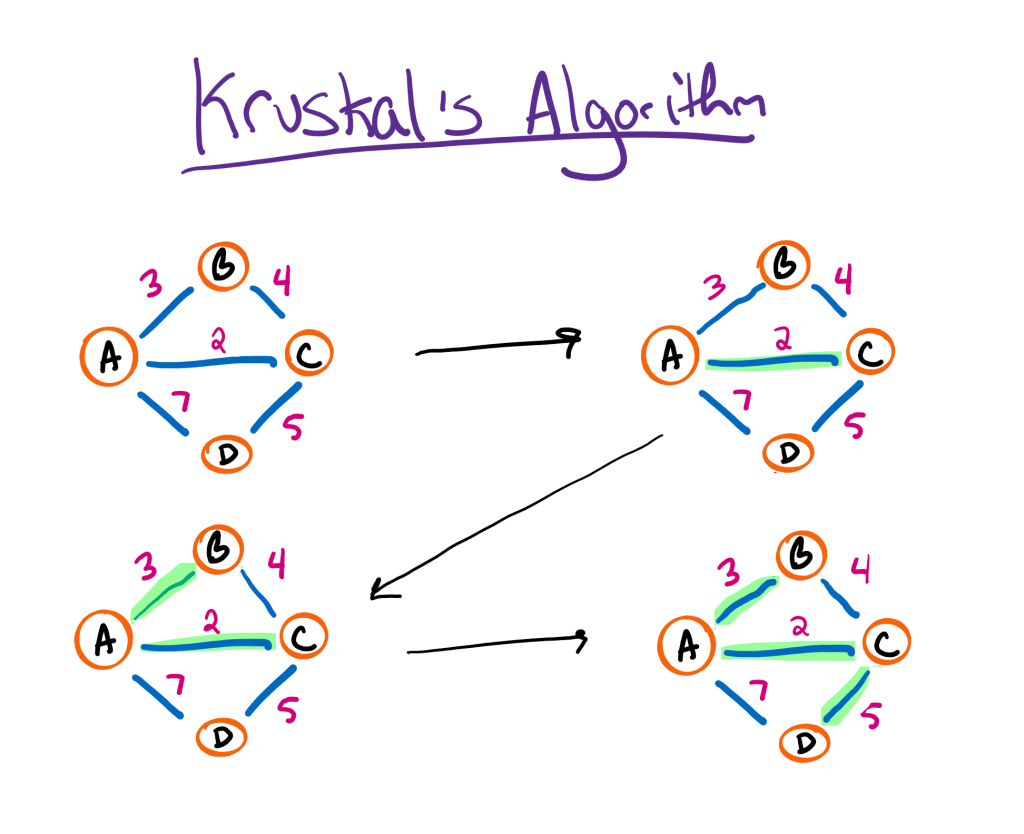
In this example, we start by selecting the smallest edge which in this case is AC. To recognize this connection, we place A and C in a set together. Then, we find the next smallest edge AB. In this case, B is not already in the set containing A, so we can safely add it.
At this point, we run into a problem. If we select BC, we’ll create a cycle because B and C are already connected through A. Since B and C are in the same set, we can safely skip that edge.
Finally, we consider the next smallest edge which is CD. Since D is not connected to C in some way, we can add it to our set containing A, B, and C. Since our set now contains all four vertices, we can stop.
Unfortunately, this example is probably not the best because Prim’s algorithm would run similarly if we started from A or C. Of course, drawing these examples takes time, so I recommend checking out Wikipedia for both Prim’s and Kruskal’s algorithms. Each page has a nice animation showing the difference.
Personally, I find this algorithm to be a bit more challenging to grasp because I find the avoiding cycles criteria a bit less obvious. That said, as I’ve seen it in various textbooks, the solution usually relies on maintaining collections of nodes in sets that represent distinct trees. Then, the algorithm only selects two nodes if they are in different trees. Otherwise, drawing an edge between the nodes would create a cycle.
Published on Java Code Geeks with permission by Jeremy Grifski, partner at our JCG program. See the original article here: Minimum Spanning Tree Algorithms Opinions expressed by Java Code Geeks contributors are their own. |
