When discussing the development impact on existing applications while transitioning to microservices, there are five questions that keep popping up in one form or another. They are the same regardless of the size of the organization and seem to become part of strategy discussions later in the process as organizations move towards microservice architectures.

These articles cover questions that everyone should ask about microservices. Their based on experiences from interactions with organizations in the process of conquering microservices for existing development and for delivering modern applications.
Previously we covered three questions; the performance impact of microservices, a question on state and monoliths, and one about
data and microservices. In this fourth article covers a question around testing stateful microservices.
Testing microservices
Assuming all goes well, everyone eventually gets to the point of testing all these new fancy distributed microservices. Then comes the realization that data source state information’s spread across the application landscape, raising the following.
“How can the state of a main application be transferred from production to a test environment when there are many data sources tied to stateful services in production?”
In a microservices world, each microservice is operating as if it’s part of another business external to your organization. As you’re having a business-to-business relationship, the microservice development teams are forced to maintain a strong API and have their own test suite. We have to realize that a good microservice should be a black box.
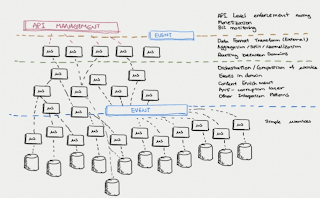
Few external business partners rarely have all the data, they only have the data they need for testing purposes. This same principle applies to internal teams developing and maintaining microservices in your organization. Testing tends to happen more in production in this new world, which is why we see the value of a service mesh technology such as Istio.
Going a bit more advanced with your solution, it’s possible to use
Debezium to replicate data through a common Kafka backbone, anonymize it and drop it to the locations needed by various independent microservice development teams (the business partners internal to your organization).
Next time in this series of articles, a look at using API management or service mesh.
(article co-authored with Burr Sutter)
Published on Java Code Geeks with permission by Eric Schabell, partner at our JCG program. See the original article here: 5 Questions Everyone’s Asking About Microservices (Question 4) Opinions expressed by Java Code Geeks contributors are their own. |
