Rising toil is a worry for all DevOps teams. The reasons from where toil arises are numerous. This makes it a very difficult problem to tackle, and nearly impossible to eliminate completely. Therefore the best strategy that teams have to tackle toil is to minimize them as much as possible. In this post, we go over some of the basics of managing toil arising due to poor alerting and paging practices.

Toil arises from the effort that engineers have to spend in performing tasks that can generally be automated or avoided. Generally speaking, engineering tasks that feel unnecessary over a period of time contribute to toil the greatest. The Google SRE book defines Toil as being tasks that could be “manual, repetitive, automatable, tactical, devoid of enduring value, and that scales linearly as a service grows”.
Let us look at an example of how poor alerting practices produce toil for a team that has embraced DevOps practices.
Assume that you are running a web application on production with AWS. You have a standard setup. And a scaling policy that determines when your Auto Scaling group should scale out or scale in. However, what if you didn’t set the scaling policy correctly? What if a bad threshold was picked? Here’s the way this would play out for your team …
- Your hosts will issue alerts about CPU/Memory exhausting.
- An increasing number of 5xx responses will trigger alerts from Cloudwatch
- Pingdom checks will begin to report increased load time or failed responses and send you alerts
- Application logs will begin to log more errors. Any log-monitoring will begin to issue alerts based on this.
- Increased logs could also trigger disk I/O alerts.
There may be many many more other alerts that would be triggered. While all of these represent problems, the fundamental problem here is a poor scaling policy.
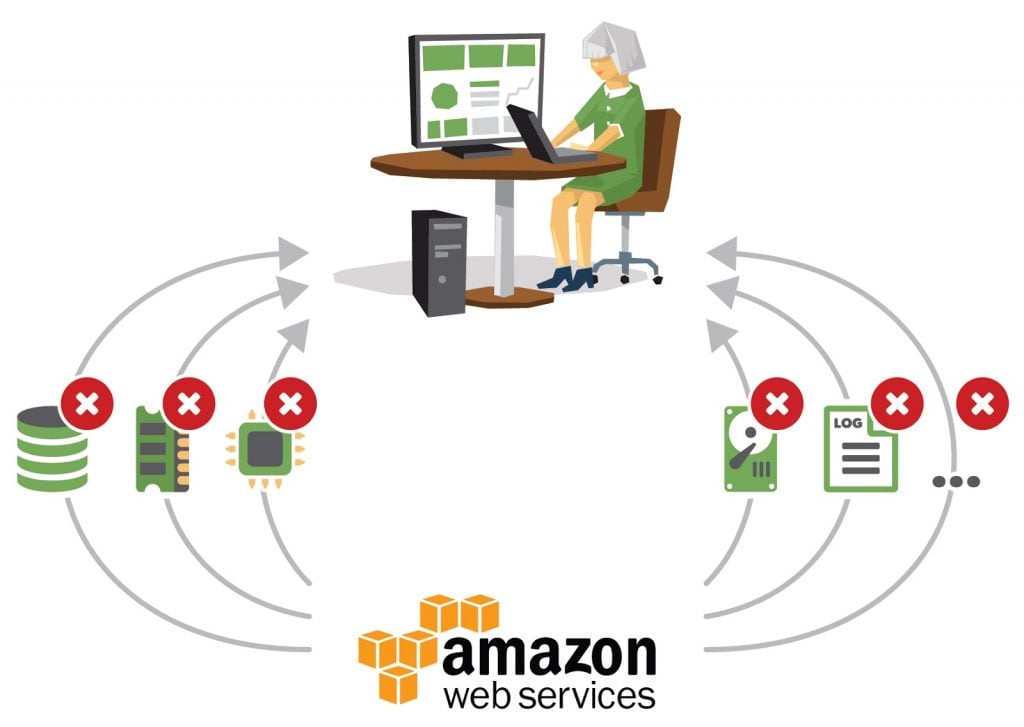
Getting alerts for the root cause may not always be possible. However, this is not an excuse to overwhelm engineers with alerts. This situation is also illustrative of how context switching, alerting setup costs, and the cost of response and diagnostics can quickly add up. Having a poor signal upon which the alert is based is at the core of this issue.
This is one of the problems that we set out to solve when building Plumbr. Plumbr works at the intersection of application monitoring and real user monitoring. Because Plumbr builds on data that is collected from real usage, it is the most accurate reflection of what a user experiences when interacting with web applications.
Better separation of the important alerts from the noisy ones that arise is required. An important source for an alerting signal, therefore, is to use data from real usage of an application. Real user monitoring places the focus on users and usage as opposed to system-level behavior. This forms a more objective basis for alerting. No one can deny that if users are affected beyond certain levels, engineers must take note and begin investigating for fixes. Whether the root cause may be database issues, CPU provisioning, scaling policy on the PaaS, or a 3-rd party infrastructure failure – if users are affected adversely, it is reasonable to alert engineers.
Your team can also use real user monitoring data to provide a better basis for alerting and paging. Start your free Plumbr trial now. Enjoy our complete feature set for 14-days at no cost.
P.S. It isn’t possible to explain everything about toil in a single document. However, we care about engineers being able to focus on the things that matter. We’ve published a white-paper that deals more extensively with the topic of toil. For the more visual learners, we’ve also posted this information as an on-demand webinar here. Cheers!
Published on Java Code Geeks with permission by Ram Iyengar, partner at our JCG program. See the original article here: Toil Arising From Alerting Opinions expressed by Java Code Geeks contributors are their own. |
