Microservices for Java Developers: Configuration, Service Discovery and Load Balancing
1. Configuration, Service Discovery and Load Balancing – Introduction
Slowly but steadily we are moving towards getting our microservices ready to be deployed in production. In this section of the tutorial we are going to talk about three main subjects: configuration, service discovery and load balancing.
Our goal is to understand the essential basic concepts rather to cover every option available. As we will see later in the tutorial, the configuration management, service discovery and load balancing are going to pop up over and over again, although in the different contexts and shapes.
Table Of Contents
2. Configuration
It is very likely that the configuration of each of your microservices is going to vary from environment to environment. It is perfectly fine but raises the question: how to tell the microservice in question what configuration to use?
Many frameworks offer different mechanisms to configuration management (like profiles, configuration files, command line options, …) but the approach we are going to advocate here is to follow The Twelve-Factor App methodology (which we have touched upon already).
The twelve-factor app stores config in environment variables (often shortened to env vars or env). Env vars are easy to change between deploys without changing any code; unlike config files, there is little chance of them being checked into the code repo accidentally; and unlike custom config files, or other config mechanisms such as Java System Properties, they are a language- and OS-agnostic standard. – https://12factor.net/config
The environment variables exhibit only one major limitation: they are static in nature. Any change in their values may require the full microservice restart. It may not be an issue for many but it is often desirable to have some kind of flexibility to modify the service configuration at runtime.
2.1. Dynamic Configuration
Ability to update the configuration without restarting the service is a very appealing feature to have. But the price to pay is also high since it requires a descent amount of instrumentation and not too many frameworks or libraries offer such transparent support.
For example, let us think about changing the database JDBC URL connection string on the fly. Not only the underlying datasources have to be transparently recreated, also the JDBC connection pools have to be drained and reinitialized as well.
The mechanics behind the dynamic configuration really depends on what kind of the configuration management approach you are using (Consul, Zookeeper, Spring Cloud Config, …), however some frameworks, like Spring Cloud for example, take a lot of this burden away from the developers.
2.2. Feature Flags
The feature flags (or feature toggles) do not fall precisely into the configuration bucket but it is a very powerful technique to dynamically change the service or application characteristics. They are tremendously useful and widely adopted for A/B testing, new features roll out, introducing experimental functionality, just to name a few areas.
In the Java ecosystem, FF4J is probably the most popular implementation of the feature flags pattern. Another library is Togglz however it is not actively maintained these days. If we go beyond just Java, it is worth looking at Unleash, an enterprise-ready feature toggles service. It has impressive list of SDKs available for many programming languages, including Java.
2.3. Spring Cloud Config
If your microservices are built on top of the Spring Platform, then Spring Cloud Config is the one of the most accessible configuration management options to start with. It provides both server-side and client-side support (the communication is based on HTTP protocol), is exceptionally easy to integrate with and even to embed into existing services.
Since the JCG Car Rentals platform needs the configuration management service, let us see how simple it is to configure one using Spring Cloud Config backed by Git.
server:
port: 20100
spring:
cloud:
config:
server:
git:
uri: file://${rentals.home}/rentals-config
application:
name: config-server
To run the embedded configuration server instance, the idiomatic Spring Boot annotation-driven approach is the way to go.
@SpringBootApplication
@EnableConfigServer
public class ConfigServerRunner {
public static void main(String[] args) {
SpringApplication.run(ConfigServerRunner.class, args);
}
}
Although Spring Cloud Config has out of the box encryption and decryption support, you may also use it in conjunction with HashiCorp Vault to manage sensitive configuration properties and secrets.
2.4. Archaius
In the space of the general-purpose library for configuration management, probably Archaius from Netflix would be the best known one (in case of JVM platform). It does support dynamic configuration properties, complex composite configuration hierarchies, has native Scala support and could be used along with Zookeeper backend.
3. Service Discovery
One of the most challenging problems, incidental to microservices which use at least some form of direct communication, is how the peers discover each other. For example, in the context of the JCG Car Rentals platform the Reservation Service should know where the Inventory Service is. How to solve this particular challenge?
One may argue that it is feasible to pass the list of host/port pairs of all running Inventory Service instances to Reservation Service using the environment variables but this is not really sustainable. What if the Inventory Service was scaled up or down? Or what if some Inventory Service instances become inaccessible due to network hiccups or just crashed? This is truly a dynamic, operational data and should be treated as such.
To be fair, service discovery often goes side by side with cluster management and coordination. It is a very interesting but broad subject so our focus is going to gravitate towards service discovery side. There are many open source options available, ranging from quite low-level to full-fledged distributed coordinators, and we are going to glance over the most widely used ones.
3.1. JGroups
JGroups, one of the oldest of its kind, is a toolkit for reliable messaging which, among its many other features, serves as backbone for cluster management and membership detection. It is not the dedicated service discovery solution per se but could be used at the lowest level to implement one.
3.2. Atomix
In the same vein, Atomix framework provides capabilities for cluster management, communicating across nodes, asynchronous messaging, group membership, leader election, distributed concurrency control, partitioning, replication and state changes coordination in distributed systems. Fairly speaking, it is also not a direct service discovery solution, rather an enabler to have your own given that the framework has all the necessary pieces in place.
3.3. Eureka
Eureka, developed at Netflix, is a REST-based service that is dedicated to be primarily used for service discovery purposes (with an emphasis on AWS support). It is written purely in Java and includes server and client components.
It is really independent of any kind of framework. However, Spring Cloud Netflix provides outstanding integration of the Spring Boot applications and services with a number of Netflix components, including the abstractions over Eureka servers and clients. Let us take a look on how JCG Car Rentals platform may benefit from Eureka.
server:
port: 20200
eureka:
client:
registerWithEureka: false
fetchRegistry: false
healthcheck:
enabled: true
serviceUrl:
defaultZone: http://localhost:20201/eureka/
server:
enable-self-preservation: false
wait-time-in-ms-when-sync-empty: 0
instance:
appname: eureka-server
preferIpAddress: true
We could also profit from the seamless integration with Spring Cloud Config instead of hard-coding the configuration properties.
spring:
application:
name: eureka-server
cloud:
config:
uri:
- http://localhost:20100
Similarly to Spring Cloud Config example, running embedded Eureka server instance requires just a single annotated class.
@SpringBootApplication
@EnableEurekaServer
public class EurekaServerRunner {
public static void main(String[] args) {
SpringApplication.run(EurekaServerRunner.class, args);
}
}
On the services side, the Eureka client should be plugged in and configured to communicate with the Eureka server we just implemented. Since the Reservation Service is built on top of Spring Boot, the integration is really simple and concise, thanks to Spring Cloud Netflix.
eureka:
instance:
appname: reservation-service
preferIpAddress: true
client:
register-with-eureka: true
fetch-registry: true
healthcheck:
enabled: true
service-url:
defaultZone: http://localhost:20200/eureka/
For sure, picking these properties from Spring Cloud Config or similar configuration management solution would be preferable. When we run multiple instances of the Reservation Service, each will register itself with the Eureka service discovery, for example:
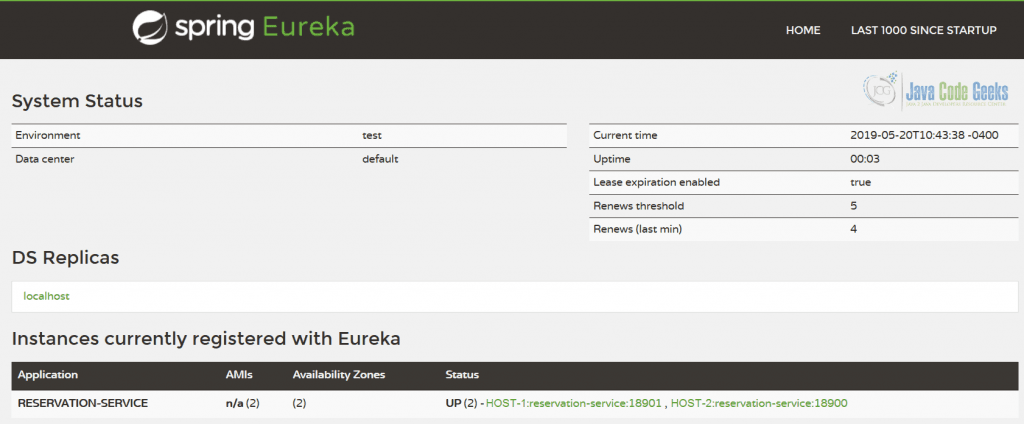
In case you are looking for self-hosted service discovery, Eureka could be a very good option. We have not done anything sophisticated yet but Eureka has a lot of features and configuration parameters to tune.

3.4. Zookeeper
Apache ZooKeeper is a centralized, highly available service for managing configuration and distributed coordination. It is one of the pioneers of the open source distributed coordinators, is battle-tested for years and serves as the reliable backbone for many other projects.
For JVM-based applications, the ecosystem of the client libraries to work with Apache ZooKeeper is pretty rich. Apache Curator, originally started at Netflix, provides high-level abstractions to make using Apache ZooKeeper much easier and more reliable. Importantly, Apache Curator also includes a set of recipes for common use cases and extensions such as service discovery.
Even more good news for Spring-based applications since the Spring Cloud Zookeeper is solely dedicated to provide Apache Zookeeper integrations for Spring Boot applications and services. Similarly to Apache Curator, it comes with the common patterns baked in, including service discovery and configuration.
3.5. Etcd
In the essence, etcd is a distributed, consistent and highly-available key value store. But don’t let this simple definition to mislead you since etcd is often used as the backend for service discovery and configuration management.
3.6. Consul
Consul by HashiCorp has started as a distributed, highly available, and data center aware solution for service discovery and configuration. It is one of the first products which augmented service discovery to become a first-class citizen, not a recipe or a pattern.
Consul’s API is purely HTTP-based so there is no special client needed to start working with it. Nonetheless, there are a couple of dedicated JVM libraries which make integration with Consul even easier, including the Spring Cloud Consul project for Spring Boot applications and services.
Unsurprisingly, Consul is evolving very fast and has become much more than just service discovery and key/value store. In the upcoming parts of the tutorial we are going to meet it again, in the different incarnations though.
4. Load Balancing
The service discovery is foundational for building scalable and resilient microservice architecture. The knowledge about how many service instances are available and their locations is essential for the consumer to have the job done but also unexpectedly reveals another issue: among many, what service instance should be picked up for a next request? This is known as load balancing and aims to optimize the resource efficiency, overall system reliability and availability.
By and large, there are two types of load balancing, client-side and server-side (including the DNS ones). In case of the client-side load balancing, each client fetches the list of available peers through service discovery and makes its own decision which one to call. In contrast, in case of server-side load balancing though, there is single entry point (load balancer) for clients to communicate with, which forwards the requests to the respective service instances.
As you may expect, load balancers may sit on different OSI levels and are expected to support different communication protocols (like TCP, UDP, HTTP, HTTP/2, gRPC, …). From the microservices implementation perspective, the presence of the health checks is a necessary operational requirement in order for the load balancer to maintain the up-to-date set of live instances. It is really exciting to see the revived efforts regarding health checks formalization, namely Health Check Response Format for HTTP APIs and GRPC Health Checking Protocol.
In the rest of this section we are going to discuss typical open source solutions which you may find useful for load balancing (and reverse proxying).
4.1. nginx
nginx is an open source software for web serving, reverse proxying, caching, load balancing of TCP/HTTP/UDP traffic (including HTTP/2 and gRPC as well), media streaming, and much more. What makes nginx extremely popular choice is the fact that its capabilities go way beyond just load balancing and it works really, really well.
4.2. HAProxy
HAProxy is free, very fast, reliable, high performance TCP/HTTP (including HTTP/2 and gRPC) load balancer. Along with nginx, it has become the de-facto standard open source load balancer, suitable for the most kinds of deployment environments and workloads.
4.3. Synapse
Synapse is a system for service discovery, developed and open sourced by Airbnb. It is part of the SmartStack framework and is built on top of battle-tested Zookeeper, HAProxy (or nginx).
4.4. Traefik
Traefik is a very popular open source reverse proxy and load balancer. It integrates exceptionally well with existing infrastructure components and supports HTTP, Websocket and HTTP/2 and gRPC. One of the strongest sides of the Traefik is its operational friendliness, since it exposes metrics, access logs, bundles web UI and REST(ful) web APIs (beside clustering, retries and circuit breaking).
4.5. Envoy
Envoy is a representative of the new generation of edge and service proxies. It supports advanced load balancing features (including retries, circuit breaking, rate limiting, request shadowing, zone local load balancing, etc) and has first class support for HTTP/2 and gRPC. Also, one of the unique features provided by Envoy is a transparent HTTP/1.1 to HTTP/2 proxying.
Envoy assumes a side-car deployment model, which basically means to have it running alongside with applications or services. It has become a key piece of the modern infrastructure and we are going to meet Envoy shortly in the next parts of the tutorial.
4.6. Ribbon
So far we have seen only server-side load balancers or side-cars but it is time to introduce Ribbon, open sourced by Netflix, a client-side IPC library with built-in software load balancing. It supports TCP, UDP and HTTP protocols and integrates very well with Eureka.
Ribbon is also supported by Spring Cloud Netflix so its integration into Spring Boot applications and services is really no-brainer.
5. Cloud
Every single cloud provider offers its own services with respect to configuration management, service discovery and load balancing. Some of them are built-in, others might be available in certain contexts, but by and large, leveraging such offerings could save you a lot of time and money.
The move to serverless execution model lays down different requirements to discovery and scaling in response to changing demands. It really becomes the part of the platform and the solutions we have talked about so far my not shine there.
6. Conclusions
In this part of the tutorials we have discussed such important subjects as configuration management, service discovery and load balancing. It was not an exhaustive overview but focused on the understanding of the foundational concepts. As we are going to see later on, the new generation of infrastructure tooling goes even further by taking care of many concerns posed by the microservices architecture.
7. What’s next
In the next part of the tutorial we are going to talk about API gateways and aggregators, yet other critical pieces of the microservices deployment.
