Back in ancient history (2004) Google’s Jeff Dean & Sanjay Ghemawat presented their innovative idea for dealing with huge data sets – a novel idea called MapReduce
Jeff and Sanjay presented that a typical cluster was made of 100s to few 1000s of machines with 2 CPUs and 2-4 GB RAM each. They presented that in the whole of Aug 2004 Google processed ~3.3 PB of data in 29,423 jobs i.e. an average job processed around 110GB of data.
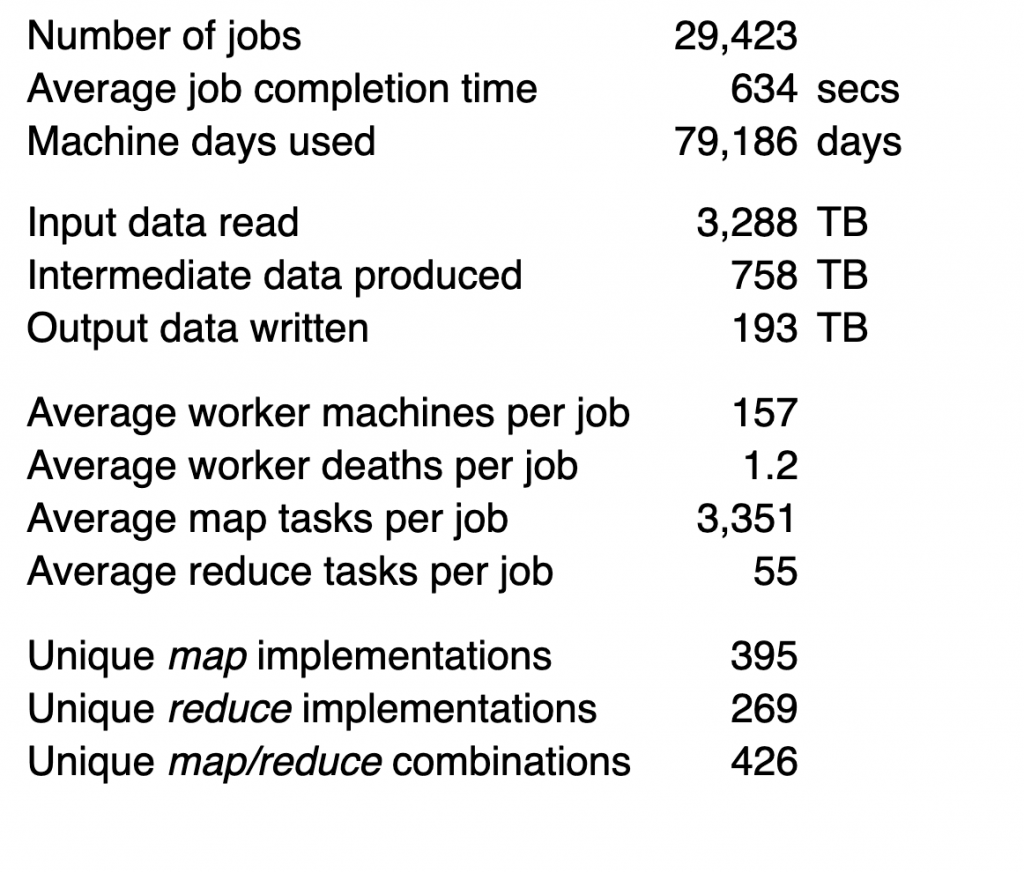
How does that compare to today’s systems and work loads?
I couldn’t fine numbers from Google but others say that by 2017 Google processed over 20PB a day (not to mention answering 40K search queries/second) so Google is definitely in the big data game. The numbers go down fast after that, even for companies who are really big data companies – Facebook presented back in 2017 they handle 500TB+ of new data daily, Whole of Twitter’s data as of May 2018 was around 300PB and Uber’s reported their data warehouse is in the 100+ PB
Ok, but what about the rest of us? Let’s take a look at an example
Mark Litwintschik took a data set of 1.1 billion rides in Taxis and Uber published by Todd W. Schnider 500GB of uncompressed CSV (i.e. 5 times larger than the average job Google ran in 2004) and benchmarked it on modern big data infrastructure. For instance, he ran his benchmark with a Spark 2.4.0 on
21-node m3.xlarge cluster – i.e. 4 vCPUs and 15 GB RAM per node (that’s x2 CPUs and x4 RAM than the 2004 machines)
His benchmark includes several queries. The one below took 20.412 seconds to complete – so overall seems like decent progress in 14 years (I know this isn’t a real comparison – but the next one is :) ).
01 02 03 04 05 06 07 08 09 10 | SELECT passenger_count, year(pickup_datetime) trip_year, round(trip_distance), count(*) trips FROM trips_orc GROUP BY passenger_count, year(pickup_datetime), round(trip_distance) ORDER BY trip_year, trips desc; |
However, the truth is that this “1.1 billion rides” data set – isn’t a big data problem. As it happens, Mark also ran the same benchmark on a single core i5 laptop (16GB RAM) using Yandex’s ClickHouse and the same query took only 12.748 seconds almost 40% faster
Where I work today one of our biggest sets is of 7 millions of hours of patient hospitalizations at a minute resolution with hundreds of different features: vital signs, medicines, labs and a slew of clinical features built on top of them – this still fits comfortably in the community edition of Vertica (i.e. < 1 TB of data)
In fact, @ less than 7$/hour Amazon will rent you a 1TB RAM machine with 64 cores -and they have machines that go up to 12TB of RAM – so huge number of datasets and problems are actually “fit in memory” data.
Looking at another aspect – one of the basic ideas behind Map/Reduce and the slew of “big data” technologies that followed is that since data is big it is much more efficient to move the computation where the data is. The documentation for Hadoop, the poster child for big data systems, explains this nicely in the HDFS architecture section
“A computation requested by an application is much more efficient if it is executed near the data it operates on. This is especially true when the size of the data set is huge. This minimizes network congestion and increases the overall throughput of the system. The assumption is that it is often better to migrate the computation closer to where the data is located rather than moving the data to where the application is running. HDFS provides interfaces for applications to movethemselves closer to where the data is located.”
In one of the previous companies I worked for, we then handled 10 billion events/day. We were still able to store our data in S3 and read it into a spark cluster to build reports like “weekly retention” that looked back as 6 months of data – i.e. all data which was in the terabytes was read from remote storage – it was still what you’d call a big data job running on 150 servers with lots of RAM (something like 36TB cluster-wide), but again, we could and did bring the data to computation and not the other way around.
Hadoop itself now support RAID-like erasure codes and not just 3x replication (which was very helpful in getting data locality) as well as provided storage (i.e. not managed by HDFS).
As a side-note, this inability to provide a real competitive-edge over cloud storage (and thus cloud offerings of Hadoop), along wit the rise of Kubernetes – is probably what led Cloudera and HortonWorks to consolidate and merge – but that’s for another post.
Anyway, the point I am trying to make is that while data is getting bigger, the threshold to big data is also moving further away. I often see questions on StackOverflow where a person runs a 3 node spark cluster and complains why he/she sees bad performance compared with whatever they were doing before – of course, that is what going to happen – big data tools are built for big data (duh!) and when used with small data (and that can be rather big as we’ve seen) you are paying all of the overhead and get none of the benefits. The examples I gave here are for static data – but the same holds true for streaming solutions. Solutions such as Kafka are complex – they solve certain types of problems really well and when you need it is invaluable.
In both cases streaming and batch – when you don’t need the big data tools they’re just a burden. In a lot of cases “big data” isn’t
Published on Java Code Geeks with permission by Arnon Rotem Gal Oz, partner at our JCG program. See the original article here: Big data isn’t – well, almost Opinions expressed by Java Code Geeks contributors are their own. |
