Even though Docker was a 2016 thing, it is still relevant today. It is the foundation of Kubernetes, the most popular Orchestration platform, that has become the go-to solution for cloud deployment.
Docker is the defacto standard solution to containerise applications/(micro)services. If you run Java application you need to beaware of a few gotchas and tricks. If you don’t this post should still help you.
2014 – We must adopt #microservices to solve all problems with monoliths
2016 – We must adopt #docker to solve all problems with microservices
2018 – We must adopt #kubernetes to solve all problems with docker pic.twitter.com/CrnvX9Lgpq— Syed Aqueel Haider (@sahrizv) July 14, 2018
Why should I put Java in a container anyway?
This is a good question to ask. Wasn’t Java built with the “Write once, run anywhere” slogan? Even though true, this statement only encompasses the Java binaries.
Your bytecode (i.e.Jar file) will run fine on every possible version of the JVM. However what about database drivers? File system access? Networking? Available entropy? Third party application you rely on? All these things will vary across Operating Systems.
Often your application will require a fine balance between your Java binaries and any of those third party dependencies. If you have ever supported Java applications installed by your clients, you will know what I mean.
First came the VMs
Before containers, the universal solution was to use Virtual Machines. Create a new blank virtual computer with the operating system of your choice, install all of your third-party dependencies, copy your Java binaries, take a snapshot and finally ship it.
With a VM you are certain that what you ship runs exactly the way it is supposed to run and also consistently each time. There is no room for environment configuration issues.
They also provide strong encapsulation. If you run your application in the cloud, each virtual machines will be strongly isolated. There is very limited space for corruption between VMs running on the same hardware.
But, there is always a but, they are heavy. If you found a bug in your application and had to change one line of code, you must recompile your Jar file, reinstall the VM and ship the whole thing. One line of code turns into several GB files to be uploaded to the cloud or downloaded at your clients. Operating System files are heavy, probably much heavier than your Java binaries, and you have to ship them every time even though they don’t really change.
Containers to the rescue
As explained above, VM have their own copy of the OS whereas containers are made to be smaller and contain just what you want to ship:
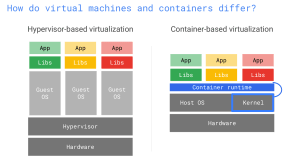
With a container, the OS(to be exact it is the Kernel that is being shared, you can choose to build images from different distributions like Ubuntu, Debian, Alpine etc…) is provided by the engine (e.g. Docker) and you don’t have to ship with your application.
With Docker, you ship images which are built in layers. The instructions for building an image is put into a Dockerfile.
Conceptually a Dockerfile could be something like:
- Start with a blank Ubuntu distribution
- Install Java
- Install dependency A
- Install dependency B
- Copy jar file
(actual Dockerfile example available below)
Each instruction in the Dockerfile creates an immutable layer. This is clever and a great optimisation. If you keep the instruction that copies your Java binaries at the end (and you should), you only have to change the last layer when you make a code change. That means if you are shipping change for the end-users, you only need to upload the last layer, the previous unchanged layers are cached; end users will only need to download the changed layers from the bottom of the image. With Docker, a change in one line of code means only a few MB upload/download (While if this was the VM the changes would be in GB instead of MB).
Warning
Be aware that containers DO NOT provide the same level of encapsulation as VMs. Docker containers are just processes running on the host machine. There are Linux kernel features (namely namespaces and control groups) that help reduce the access level of a Docker container but this is nowhere near as resilient as VM isolation. This might or might not be an issue for your business, but you need to be aware.
Java + Docker = ❤️ ???
Before we look into how to pack a Jar file inside a Docker container, we need to cover some important limitations. Java 1.0 was released in 1996 while Linux containers originate around 2008. From this follows that the JVM would not have been expected to accommodate Linux containers.
One of the key features of Docker is the ability to limit a container’s memory and CPU usage. This is one of the main reason why it’s economically interesting to run many Docker containers in the Cloud. Orchestration solutions like Kubernetes (k8s) will try to efficiently “pack” containers on multiple nodes. Here “pack” refers to memory and CPU (see how k8s plays Tetris for you). If you give sensible boundaries for memory and CPU to your Docker containers, K8s will be able to efficiently arrange them on multiple nodes.
Unfortunately, this is precisely where Java runs short. Let’s use an example to understand the problem.
Imagine you have a node with 32GB of memory and you want to run a Java application with a limit of 1GB. Remember that Docker containers are no more than a glorified process on a host machine. If you do not provide a -Xmx parameter the JVM will use its default configuration:
- The JVM will check the total available memory. Because the JVM is not aware of the Linux container (in particular of the Control Group which limits memory) it thinks it is running on the Host machine and has access to the full 32GB of available memory.
- By default, the JVM will use MaxMemory/4 which in this case is 8GB (32GB/4).
- As the heap size grows and goes beyond 1GB, the container will be killed by Docker.
Earlier adopters of Java on Docker had a fun time trying to understand why their JVM kept crashing without any error message. To understand what happened you need to inspect the dead Docker container and in that case, you’d see a message saying “OOM killed” (OutOf Memory).
Of course, an obvious solution is to fix the JVM’s heap size using Xmx parameter, but that means you need to control memory twice, once in Docker and once in the JVM. Every-time you want to make a change you have to do it twice. Not ideal.
The first workaround for this issue was released with Java 8u131 and Java 9. I say workaround because you had to use the beloved -XX:+UnlockExperimentalVMOptions parameters. If you work in Financial services I’m sure you love to explain to your clients or your boss that this is a sensible thing do to.
Then you had to use -XX:+UseCGroupMemoryLimitForHeap which would tell the JVM to check for the Control Group memory limit to set the maximum heap size.
Finally, you’d have to use -XX:MaxRAMFraction to decide the portion of the maximum memory that can be allocated for the JVM. Unfortunately, this parameter is a natural number. For example with a Docker memory limit set to 1GB you’d have the following:
- -XX:MaxRAMFraction=1 The maximum heap size will be 1GB. This is not great as you can’t give the JVM 100% of the allowed memory. There might be other components running on that container
- -XX:MaxRAMFraction=2 The maximum heap size will be 500MB. That’s better but now it seems we are wasting a lot of memory.
- -XX:MaxRAMFraction=3 The maximum heap size will be 250MB. You are paying for 1GB of memory and your java app gets to use 250MB. That’s getting a bit ridiculous
- -XX:MaxRAMFraction=4 Don’t even go there.
Basically, the JVM flags to control Maximum available RAM was set as a fraction rather than a percentage, making it hard to set values that would make efficient use of the available (allowed) RAM.
We focused on memory but the same would apply for CPU. You’d need to use parameters like
-Djava.util.concurrent.ForkJoinPool.common.parallelism=2
to control the size of the different thread pools in your applications. The 2 means two threads (the maximum value would be limited to the number of hyper-threads available on your host machine).
To summarise, with Java 8u131and Java 9 you’d have something like:
-XX:+UnlockExperimentalVMOptions -XX:+UseCGroupMemoryLimitForHeap -XX:MaxRAMFraction=2 -Djava.util.concurrent.ForkJoinPool.common.parallelism=2

Luckily Java 10 came to the rescue. First, you don’t have to use the scary experimental feature flag. If you run your Java application in a Linux container the JVM will automatically detect the Control Group memory limit. Otherwise, you simply need to add -XX:-UseContainerSupport.
Then you can control the memory with -XX:InitialRAMPercentage, -XX:MaxRAMPercentage and -XX:MinRAMPercentage. For example with
- Docker memory limit: 1GB
- -XX:InitialRAMPercentage=50
- -XX:MaxRAMPercentage=70
Your JVM will start with 500MB(50%) heap size and will grow up to 700MB(70%), in the container the maximum available memory is 1GB .

Java2Docker
There are different ways to turn a Java Application into a Docker image.
You can use a Maven plugin (fabric8 or Spotify) or a Graddle plug-in. But perhaps the simplest and more semantical approach is to write a Dockerfile yourself. This approach also allows you to leverage JDK’s jlink introduced in JDK9. Using jlink you can build a custom JDK binary containing only the modules required by your application.
Let’s look at an example:
FROM adoptopenjdk/openjdk11 AS jdkBuilder RUN $JAVA_HOME/bin/jlink \ --module-path /opt/jdk/jmods \ --verbose \ --**add**-modules java.base \ --output /opt/jdk-minimal \ --compress 2 \ --no-header-files FROM debian:9-slim COPY --from=jdkBuilder /opt/jdk-minimal /opt/jdk-minimal ENV JAVA_HOME=/opt/jdk-minimal COPY target/*.jar /opt/ CMD $JAVA_HOME/bin/java $JAVA_OPTS -jar /opt/*.jar
Let’s go through it line by line
FROM adoptopenjdk/openjdk11 AS jdkBuilder
We start from an existing Docker image which contains the full JDK 11. Here we used the build provided by AdoptOpenJDK but you could use any other distribution (for example the newly announced AWS Corretto). The AS jdkBuilderinstruction is a special instruction that tells Docker we want to start a “stage” called jdkBuilder . This will be useful later.
RUN $JAVA_HOME/bin/jlink \ --module-path /opt/jdk/jmods \ --verbose \ --add-modules java.base \ --output /opt/jdk-minimal \ --compress 2 \ --no-header-files
We run jlink to build our custom JDK binaries. In this example, we only use the java.base module which might not be sufficient to run your application. If you are still writing old classpath type application, you will have to manually add all the modules required by your application. For example for one of my Spring app I use the following modules:
--add-modules java.base,java.logging,java.xml, java.xml.bind,java.sql,jdk.unsupported, java.naming,java.desktop,java.management, java.security.jgss,java.security.sasl, jdk.crypto.cryptoki,jdk.crypto.ec, java.instrument,jdk.management.agent, jdk.localedata
If you are writing Java application with modules you can let jlink infer what modules are required. To do that you need to add your module(s) to the module-path argument (list of paths separated by “:” on MacOS/Linux and “;” on Windows). But because this process happens in the Docker image you need to bring it over with the COPY command. Then you only need to add your own module in the -add-modules command and the required modules will be added automatically. So it would be something like:
FROM adoptopenjdk/openjdk11 AS jdkBuilder COPY path/to/module-info.class /opt/myModules RUN $JAVA_HOME/bin/jlink \ --module-path /opt/jdk/jmods:/opt/myModules \ --verbose \ --**add**-modules my-module \ --output /opt/jdk-minimal \ --compress 2 \ --no-header-files
FROM debian:9-slim
Because we use another FROM keyword, Docker will discard everything we have done so far and start a fresh new image. Here we start with a Docker image that has Debian 9 installed and the bare minimum dependencies installed (slim tag). This Debian image doesn’t even have Java, so that’s what we will install next.
COPY --from=jdkBuilder /opt/jdk-minimal /opt/jdk-minimal ENV JAVA_HOME=/opt/jdk-minimal
This is where the stage name becomes important. We can tell Docker to copy a specific folder from an earlier stage, in that case from the jdkBuilder stage. This is interesting because in this first stage we could have downloaded a lot of intermediary libraries that are not needed in the end.
In this case, we started with the full JDK 11 distribution which weighs 200+MB but we only need to copy our custom JDK binaries which would typically be ~50/60MB; depending on which JDK modules you had to import. Then we set the JAVA_HOME environment variable to point to our new built JDK binaries.
This technique is called Docker multi-stage builds and can be very useful indeed. It makes efficient use of the layers created and helps to make slimmer docker images. If you have looked through a typical Dockerfile you might have seen instructions like the below:
rm -rf /var/lib/apt/lists/* \ apt-get clean && apt-get update && apt-get upgrade -y \ apt-get install -y --no-install-recommends curl ca-certificates \ rm -rf /var/lib/apt/lists/* \ ...
This technique to group as many commands as possible in a single Dockerfile instruction was useful to minimise the number of layers in your image. A high number of layers can impact performance at runtime. However, there is also a drawback to this approach. Having one layer per instruction means creating a lot of cached checkpoints.
If you made a mistake in your Dockerfile at instruction 15, Docker doesn’t have to re-run the previous 14, it can simply recover them from the cache. If one of your steps is to download a 400MB file having this instruction cache will save you a lot of time.
The good news is that multi-stage made this approach obsolete! You can create a first “throw-away” stage, in which you can create as many layers as you want. Then you create a new “final” stage in which you copy only the required file from the first throw-away stage.
The many layers from the first stage will be completely ignored!
COPY target/*.jar /opt/
Now that we have Java installed we need to copy your application. This will copy any jar file from the target directory and put them in the opt folder
CMD $JAVA_HOME/bin/java $JAVA_OPTS -jar /opt/*.jar
Finally, this tells Docker which command to execute when the container runs. Here we simply run java and allow for the JAVA_OPTS variable to be passed at runtime.
Note that it is really important to leave the instruction that copies your application at the end. This way, if you need to make a code change, you will only invalidate the last layer and won’t need to redo the previous steps.
Conclusion
That’s it, folks, we went through the pitfalls of running Java on Docker and how to write a generic Dockerfile which will only ship what your application needs!
If you want to know about how to run Docker containers in the cloud check my talk Cloud Ready JVM with Kubernetes.
Thank you, Mani Sarkar (@theNeomatrix369) for helping me write this article!
Resources
- Cloud Ready JVM with Kubernetes: https://skillsmatter.com/skillscasts/12502-ljc-london-java-community
- The JVM and Docker. A good idea? by Christopher Batey: https://www.youtube.com/watch?v=6ePUiQuaUos
- Java on Docker by Richard Warburton: https://www.opsian.com/blog/java-on-docker/
- Docker multi-stage builds: https://docs.docker.com/develop/develop-images/multistage-build/
- Bare-metal v/s VM v/s Containers: https://neomatrix369.wordpress.com/2016/03/13/containers-all-the-way-through/
- What is Kubernetes: https://learnk8s.io/blog/what-is-kubernetes
| Published on Java Code Geeks with permission by Cesar Tron-Lozai, partner at our JCG program. See the original article here: Docker and the JVM Opinions expressed by Java Code Geeks contributors are their own. |
