As continuation of anatomy-of-apache-spark-job post i will share how you can use Spark UI for tuning job. I will continue with same example that was used in earlier post, new spark application will do below things
– Read new york city parking ticket
– Aggregation by “Plate ID” and calculate offence dates
– Save result
DAG for this code looks like this
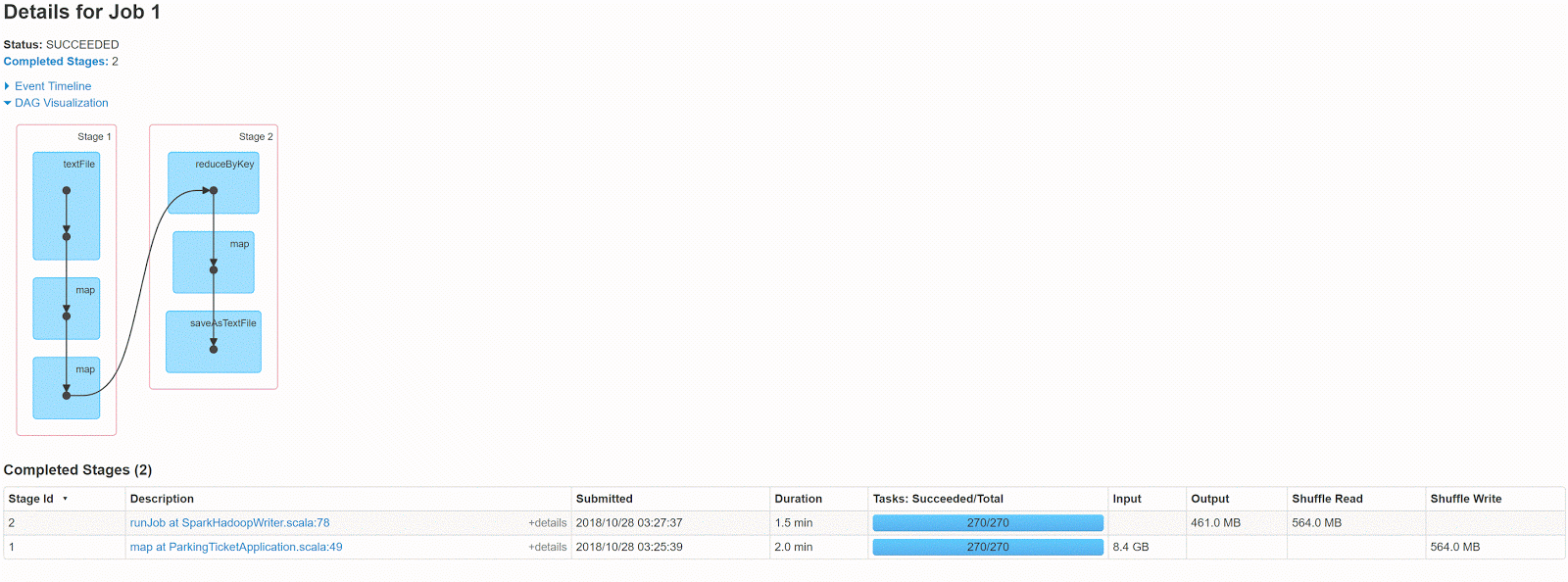
This is multi stage job, so some data shuffle is required, for this sample shuffle write is 564mb and output is 461 MB.
Lets see what we can do to reduce this ?
lets take top down approach from “Stage2”. First thing that comes to mind is explore compression.
Current code
aggValue.map {
case (key, value) => Array(key, value._1, value._2.mkString(",")).mkString("\t")
}.saveAsTextFile(s"/data/output/${now}")New Code
aggValue.map {
case (key, value) => Array(key, value._1, value._2.mkString(",")).mkString("\t")
}.saveAsTextFile(s"/data/output/${now}", classOf[GzipCodec])New code is only enabling gzip on write, lets see what we see on spark UI

With just write encoder write went down by 70%. Now it 135Mb and it speed up the job.
Lets see what else is possible before we dive in more internals tuning
Final output looks some like below
1RA32 1 05/07/2014 92062KA 2 07/29/2013,07/18/2013 GJJ1410 3 12/07/2016,03/04/2017,04/25/2015 FJZ3486 3 10/21/2013,01/25/2014 FDV7798 7 03/09/2014,01/14/2014,07/25/2014,11/21/2015,12/04/2015,01/16/2015
Offence date is stored in raw format, it is possible to apply little encoding on this to get some more speed.
Java 8 added LocalDate to make date manipulation easy and this class comes with some handy functions, one of that is toEpocDay.
This function convert date to day from 1970 and so it means that in 4 bytes(Int) we can store upto 5K years, this seems big saving as compared to current format which is taking 10 bytes.
Code snippet with epocDay
val issueDate = LocalDate.parse(row(aggFieldsOffset.get("issue date").get), ISSUE_DATE_FORMAT)
val issueDateValues = mutable.Set[Int]()
issueDateValues.add(issueDate.toEpochDay.toInt)
result = (fieldOffset.map(fieldInfo => row(fieldInfo._2)).mkString(","), (1, issueDateValues))Spark UI after this change. I have also done one more change to use KryoSerializer

This is huge improvement , Shuffle write changed from 564Mb to 409MB ( 27% better) and output from 134Mb to 124 Mb( 8% better)
Now lets go to another section on Spark UI that shows logs from executor side.
GC logs for above run shows below thing
2018-10-28T17:13:35.332+0800: 130.281: [GC (Allocation Failure) [PSYoungGen: 306176K->20608K(327168K)] 456383K->170815K(992768K), 0.0222440 secs] [Times: user=0.09 sys=0.00, real=0.03 secs] 2018-10-28T17:13:35.941+0800: 130.889: [GC (Allocation Failure) [PSYoungGen: 326784K->19408K(327168K)] 476991K->186180K(992768K), 0.0152300 secs] [Times: user=0.09 sys=0.00, real=0.02 secs] 2018-10-28T17:13:36.367+0800: 131.315: [GC (GCLocker Initiated GC) [PSYoungGen: 324560K->18592K(324096K)] 491332K->199904K(989696K), 0.0130390 secs] [Times: user=0.11 sys=0.00, real=0.01 secs] 2018-10-28T17:13:36.771+0800: 131.720: [GC (GCLocker Initiated GC) [PSYoungGen: 323744K->18304K(326656K)] 505058K->215325K(992256K), 0.0152620 secs] [Times: user=0.09 sys=0.00, real=0.02 secs] 2018-10-28T17:13:37.201+0800: 132.149: [GC (Allocation Failure) [PSYoungGen: 323456K->20864K(326656K)] 520481K->233017K(992256K), 0.0199460 secs] [Times: user=0.12 sys=0.00, real=0.02 secs] 2018-10-28T17:13:37.672+0800: 132.620: [GC (Allocation Failure) [PSYoungGen: 326016K->18864K(327168K)] 538169K->245181K(992768K), 0.0237590 secs] [Times: user=0.17 sys=0.00, real=0.03 secs] 2018-10-28T17:13:38.057+0800: 133.005: [GC (GCLocker Initiated GC) [PSYoungGen: 324016K->17728K(327168K)] 550336K->259147K(992768K), 0.0153710 secs] [Times: user=0.09 sys=0.00, real=0.01 secs] 2018-10-28T17:13:38.478+0800: 133.426: [GC (Allocation Failure) [PSYoungGen: 322880K->18656K(326144K)] 564301K->277690K(991744K), 0.0156780 secs] [Times: user=0.00 sys=0.00, real=0.01 secs] 2018-10-28T17:13:38.951+0800: 133.899: [GC (Allocation Failure) [PSYoungGen: 323808K->21472K(326656K)] 582842K->294338K(992256K), 0.0157690 secs] [Times: user=0.09 sys=0.00, real=0.02 secs] 2018-10-28T17:13:39.384+0800: 134.332: [GC (Allocation Failure) [PSYoungGen: 326624K->18912K(317440K)] 599490K->305610K(983040K), 0.0126610 secs] [Times: user=0.11 sys=0.00, real=0.02 secs] 2018-10-28T17:13:39.993+0800: 134.941: [GC (Allocation Failure) [PSYoungGen: 313824K->17664K(322048K)] 600522K->320486K(987648K), 0.0111380 secs] [Times: user=0.00 sys=0.00, real=0.02 secs]
Lets focus on one the line
2018-10-28T17:13:39.993+0800: 134.941: [GC (Allocation Failure) [PSYoungGen: 313824K->17664K(322048K)] 600522K->320486K(987648K), 0.0111380 secs] [Times: user=0.00 sys=0.00, real=0.02 secs]
Heap before minor GC was 600MB and after that 320MB and total heap size is 987 MB.
Executor is allocated 2gb and this Spark application is not using all the memory, we can put more load on executor by send more task or bigger task.
I will reduce input partition from 270 to 100


100 input partition looks better with around 10+% less data to shuffle.
Other tricks
Now i will share some of things that will make big difference in GC!
Code before optimization
private def mergeValues(value1: (Int, mutable.Set[Int]), value2: (Int, mutable.Set[Int])): (Int, mutable.Set[Int]) = {
val newCount = value1._1 + value2._1
val dates = value1._2
dates.foreach(d => value2._2.add(d))
(newCount, value2._2)
}
private def saveData(aggValue: RDD[(String, (Int, mutable.Set[Int]))], now: String) = {
aggValue
.map { case (key, value) => Array(key, value._1, value._2.mkString(",")).mkString("\t") }.coalesce(100)
.saveAsTextFile(s"/data/output/${now}", classOf[GzipCodec])
}Code after optimization
private def mergeValues(value1: GroupByValue, value2: GroupByValue): GroupByValue = {
if (value2.days.size > value1.days.size) {
value2.count = value1.count + value2.count
value1.days.foreach(d => value2.days.add(d))
value2
}
else {
value1.count = value1.count + value2.count
value2.days.foreach(d => value1.days.add(d))
value1
}
}
private def saveData(aggValue: RDD[(String, GroupByValue)], now: String) = {
aggValue.mapPartitions(rows => {
val buffer = new StringBuffer()
rows.map {
case (key, value) =>
buffer.setLength(0)
buffer
.append(key).append("\t")
.append(value.count).append("\t")
.append(value.days.mkString(","))
buffer.toString
}
})
.coalesce(100)
.saveAsTextFile(s"/data/output/${now}", classOf[GzipCodec])
}New code is doing optimized merge of set, it is adding small set to the big one and also introduced Case class.
Another optimization is in save function where it is using mapPartitions to reduce object allocation by using StringBuffer.
I used http://gceasy.io to get some GC stats.

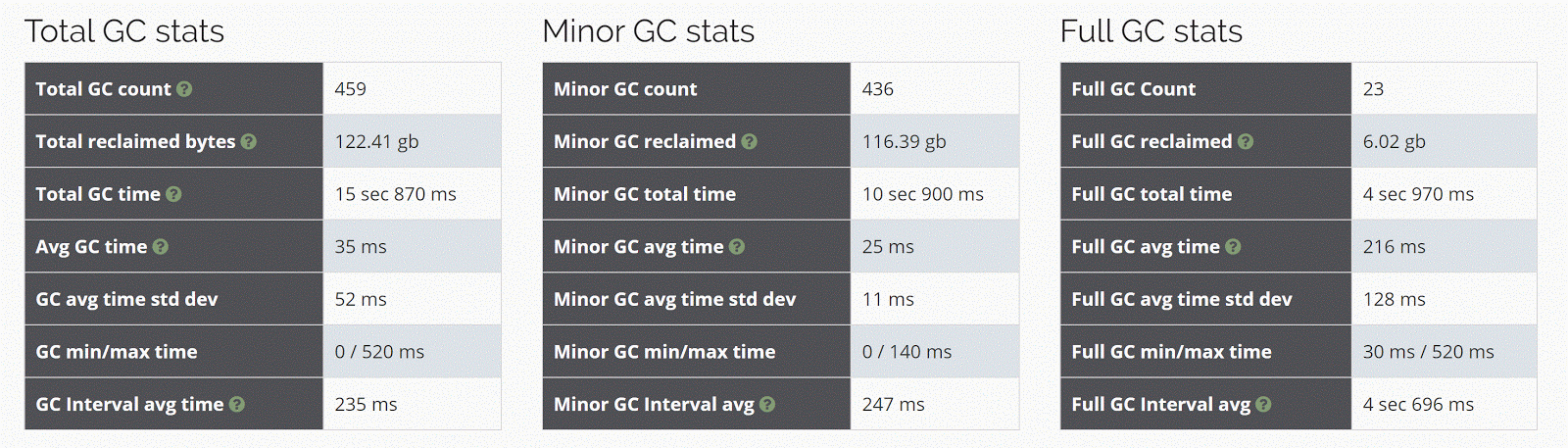
New code is producing less garbage for eg.
Total GC 126 gb vs 122 gb ( around 4% better)
Max GC time 720ms vs 520 ms ( around 25% better)
Optimization looks promising.
All the code used in this blog is available on github repo sparkperformance
Stay tuned up for more on this.
| Published on Java Code Geeks with permission by Ashkrit Sharma, partner at our JCG program. See the original article here: Insights from Spark UI Opinions expressed by Java Code Geeks contributors are their own. |
