Microservices for Java Developers: Implementing microservices (synchronous, asynchronous, reactive, non-blocking)
1. Introduction
The previous parts of the tutorial were focused on more or less high-level topics regarding microservice architecture, like for example different frameworks, communication styles and interoperability in the polyglot world. Although it was quite useful, starting from this part we are slowly getting down to earth and direct our attention to the practical side of things, as developers say, closer to the code.
Table Of Contents
We are going to begin with a very important discussion regarding the variety of paradigms you may encounter while implementing the internals of your microservices. The deep understanding of the applicability, benefits and tradeoffs each one provides would help you out to make the right implementation choices in every specific context.
2. Synchronous
Synchronous programming is the most widely used paradigm these days because of its simplicity and ease to reason about. In the typical application it usually manifests as the sequence of function calls, where the each one is executed after another. To illustrate it in action, let us take a look on the implementation of the JAX-RS resource endpoint from the Customer Service.
@POST
@Produces(MediaType.APPLICATION_JSON)
@Consumes(MediaType.APPLICATION_JSON)
public Response register(@Context UriInfo uriInfo, @Valid CreateCustomer payload) {
final CustomerInfo info = conversionService.convertTo(payload, CustomerInfo.class);
final Customer customer = customerService.register(info);
return Response
.created(
uriInfo
.getRequestUriBuilder()
.path(customer.getUuid())
.build())
.build();
}
As you read this code, there are no surprises along the way (aside from possibility to get the exceptions). First, we convert customer information from the RESTful web API payload to the service object, after that we invoke the service to register the new customer and finally we return the response back to the caller. When the execution completes, the result of it is known and fully evaluated.
So what are the problems with such a paradigm? Surprisingly, it is the fact that the current invocation must wait for the previous one to finish. As an example, what if we have to send a confirmation email to the customer upon successful registration? Should we absolutely wait for the confirmation to be sent out or we could just return the response and make sure the confirmation is scheduled for delivery? Let us try to find the right answer in the next section.
3. Asynchronous
As we just discussed, the results of some operations may not necessarily be required in order for the execution flow to continue. Such operations could be executed asynchronously: concurrently, in parallel or even at some point in the future. The result of the operation may not be available immediately.
In order to understand how it works under the hood, we have to talk a little bit about concurrency and parallelism in Java (and on JVM in general), which is based on threads. Any execution in Java takes place in the context of the thread. As such, typical ways to achieve the execution of the particular operation asynchronously are to borrow the thread from the thread pool (or spawn a new thread manually) and perform the invocation in its context.
It looks pretty straightforward but it would be good to know when the asynchronous execution actually completes and, most importantly, what is the result of it. Since we are focusing primarily on Java, the key ingredient here is CompletableFuture which represents the result of an asynchronous computation. It has a number of the callback methods which allow the caller to be notified when the results are ready.
The veteran Java developers definitely remember the predecessor of the CompletableFuture, the Future interface. We are not going to talk about Future nor recommend using it since its capabilities are very limited.
Let us get back to sending a confirmation email upon successful customer registration. Since our Customer Service is using CDI 2.0, it would be natural to bind the notification to the customer registration event.
@Transactional
public Customer register(CustomerInfo info) {
final CustomerEntity entity = conversionService.convertTo(info, CustomerEntity.class);
repository.saveOrUpdate(entity);
customerRegisteredEvent
.fireAsync(new CustomerRegistered(entity.getUuid()))
.whenComplete((r, ex) -> {
if (ex != null) {
LOG.error("Customer registration post-processing failed", ex);
}
});
return conversionService.convertTo(entity, Customer.class);
}
The CustomerRegistered event is fired asynchronously and registration process continues the execution without awaiting for all observers to process it. The implementation is somewhat naïve (since the transaction may fail or application may crash while processing the event) but it is good enough to illustrate the point: asynchronicity makes it harder to understand and reason about the execution flows. Not to mention the hidden costs of it: threads are precious and expensive resource.
The interesting property of the asynchronous invocation is the possibility to time it out (in case it is taking too long) or/and request the cancellation (in case the results are not needed anymore). However, as you may expect, not all operations could be interrupted, certain conditions apply.
4. Blocking
The synchronous programming paradigm in the context of executing I/O operations is often referred as blocking. Fairly speaking, synchronous and blocking are often used interchangeably but with respect to our discussion, only I/O operations are assumed to fall into this category.
Indeed, although from the execution flow perspective there is no much difference (each operation has to wait for previous one to complete), the mechanics of doing I/O is quite contrasting from, let say, pure computational work. What would be the typical examples of such blocking operation in mostly any Java application? Just think of relational databases and JDBC drivers.
@Inject @CustomersDb
private EntityManager em;
@Override
public Optional findById(String uuid) {
final CriteriaBuilder cb = em.getCriteriaBuilder();
final CriteriaQuery query = cb.createQuery(CustomerEntity.class);
final Root root = query.from(CustomerEntity.class);
query.where(cb.equal(root.get(CustomerEntity_.uuid), uuid));
try {
final CustomerEntity customer = em.createQuery(query).getSingleResult();
return Optional.of(customer);
} catch (final NoResultException ex) {
return Optional.empty();
}
}
Our Customer Service implementation does not use JDBC APIs directly, relying on high-level JPA specification (JSR-317, JSR-338) and its providers instead. Nonetheless, it easy to spot where the call to database is happening:
final CustomerEntity customer = em.createQuery(query).getSingleResult();
The execution flow is going to hit the wall here. Depending on the capabilities of the JDBC drivers, you may have some control over the transaction or query, like for example, cancelling it or setting the timeout. But by and large, it is a blocking call: the execution resumes only when the query is completed and results are fetched.
5. Non-Blocking
During the I/O cycles a lot of time is spent in waiting, typically for the disk operations or network transfers. Consequently, as we have seen in the previous section, the execution flow has to pay the price of that by being blocked from the further progress.
Since we already have gotten the brief introduction into the concept of the asynchronous programming, the obvious question would be why not to invoke such I/O operations asynchronously? All in all it makes perfect sense, however at least with respect to JVM (and Java) that would just offload the problem from one execution thread to another one (for instance, borrowed from the dedicated I/O pool). It is still looking quite inefficient from resource utilization perspective. Even more, the scalability is going to suffer as well since the application cannot just spawn or borrow new threads indefinitely.
Luckily, there are a number of techniques to attack this problem, collectively known as non-blocking I/O (or asynchronous I/O). One of the most widely used implementation of non-blocking, asynchronous I/O is based on Reactor pattern. The picture below depicts a simplified view of the it.
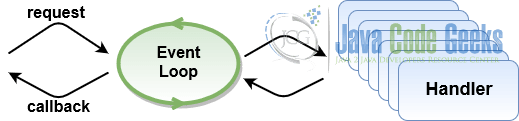
In the core of the Reactor pattern is a single-threaded event loop. Upon receiving the request for I/O operation, it is delegated to the pool of handlers (or to more efficient implementation specific to the operating system the application is running on). The results of I/O operation may be injected back (as the events) to the event loop and eventually, upon the completion, the outcome is dispatched to the application.
On JVM, the Netty framework is the de-facto choice for implementing an asynchronous, event-driven network servers and clients. Let us take a look on how the Reservation Service may call the Customer Service to lookup the customer by its identifier in a truly non-blocking fashion using AsyncHttpClient library, built on top of Netty (the error handling is omitted to keep the snippet short).
final AsyncHttpClient client = new DefaultAsyncHttpClient();
final CompletableFuture customer = client
.prepareGet("http://localhost:8080/api/customers/" + uuid)
.setRequestTimeout(500)
.setReadTimeout(100)
.execute()
.toCompletableFuture()
.thenApply(response -> fromJson(response.getResponseBodyAsStream()));
// ...
client.close();
Interestingly enough, for the caller the non-blocking invocation is no different from the asynchronous one, but the internals of how it is done matter a lot.

6. Reactive
The reactive programming lifts the asynchronous and non-blocking paradigms to a completely new level. There are quite a few definitions what the reactive programming really is, but the most compelling one is this.
Reactive programming is programming with asynchronous data streams. – https://gist.github.com/staltz/868e7e9bc2a7b8c1f754
This rather short definition is worth a book. To keep the discussion reasonably short, we are going to focus on a practical side of things, the reactive streams.
Reactive Streams is an initiative to provide a standard for asynchronous stream processing with non-blocking back pressure. – http://www.reactive-streams.org/
What is so special about it? The reactive streams unify the way we are dealing with data in our applications by emphasizing on a few key points:
- (mostly) everything is a stream
- the streams are asynchronous by nature
- the streams supports non-blocking back pressure to control the flow of data
The code is worth thousand words. Since Spring WebFlux comes with reactive, non-blocking HTTP client, let us take a look on how the Reservation Service may call the Customer Service to lookup the customer by its identifier in the reactive way (for simplicity, the error handling is omitted).
final HttpClient httpClient = HttpClient
.create()
.tcpConfiguration(client ->
client
.option(ChannelOption.CONNECT_TIMEOUT_MILLIS, 500)
.doOnConnected(conn ->
conn
.addHandlerLast(new ReadTimeoutHandler(100))
.addHandlerLast(new WriteTimeoutHandler(100))
));
final WebClient client = WebClient
.builder()
.clientConnector(new ReactorClientHttpConnector(httpClient))
.baseUrl("http://localhost:8080/api/customers")
.build();
final Mono customer = client
.get()
.uri("/{uuid}", uuid)
.retrieve()
.bodyToMono(Customer.class);
Conceptually, it looks pretty much like the AsyncHttpClient example, just a bit more ceremony. However, the usage of reactive types (like Mono<Customer>) unleashes the full power of reactive streams.
The discussions around reactive programming could not be complete without mentioning the The Reactive Manifesto and its tremendous impact on the design and architecture of the modern applications.
… We believe that a coherent approach to systems architecture is needed, and we believe that all necessary aspects are already recognised individually: we want systems that are Responsive, Resilient, Elastic and Message Driven. We call these Reactive Systems.
Systems built as Reactive Systems are more flexible, loosely-coupled and scalable. This makes them easier to develop and amenable to change. They are significantly more tolerant of failure and when failure does occur they meet it with elegance rather than disaster. Reactive Systems are highly responsive, giving users effective interactive feedback. – https://www.reactivemanifesto.org/
The foundational principles and promises of the reactive systems fit exceptionally well the microservice architecture, spawning a new class of microservices, the reactive microservices.
7. The Future Is Bright
The pace of innovation in Java has increased dramatically over the last couple of years. With the fresh release cadence, the new features become available to the Java developers every 6 months. However, there are many ongoing projects which may have a dramatic impact on the future of JVM and Java in particular.
One of those is Project Loom. The goal of this project is to explore the implementation of lightweight user-mode threads (fibers), delimited continuations (of some form), and related features. As of now, fibers are not supported by JVM natively, although there are some libraries like Quasar from Parallel Universe which are trying to fill this gap.
Also, the introduction of fibers, as the alternative to threads, would make it possible to have efficient support of the coroutines on JVM.
8. Implementing microservices – Conclusions
In this part of the tutorial we have talked about different paradigms you may consider while implementing your microservices. We went from the traditional way of structuring the execution flows as a sequence of consecutive blocking steps up to the reactive streams.
The asynchronous and reactive ways of thinking and writing the code may look difficult at first. Fear no more, but it does not mean all your microservices must be reactive. Every choice is a tradeoff and it is up to you to make the right ones in the context of your microservice architecture and organization.
9. What’s next
In the next part of the tutorial we are going to discuss the fallacies of the distributed computing and how to mitigate their impact in the microservice architectures.
