Microservices are a big business. Thanks to advances in container orchestration, multi-process applications development and sheer user demand, companies are edging away from traditional monolithic applications towards distributed, highly-available microservices. Breaking applications into smaller chunks reaps rewards in many guises. However, with this distribution there arises a new requirement: messaging for inter-service communication.
How does microservices messaging tie back to CI/CD and the Codeship products? What does it means for developers?
The shoe horn solution
It seems, lately, that the old adage of “if all you have is a hammer, then every problem looks like a nail” is appropriate to microservices messaging. Since cloud-based applications are also Internet-based applications, many developers new to the cloud scene are intrinsically approaching each service design as simply micro-web-servers. Since the public interface for an API level service uses REST with JSON packets, it’s reasonable to utilize this format for each of the internal services, too.
Now, it might just be that using a JSON-based REST interface for each and every service in your application is exactly the right choice. At best, it may not be the wrong choice, but by remembering to ‘use the right tool for the job’, applications can be simplified, more efficient, more secure and easier to maintain. We know this is true of databases, languages and even server providers; so why not messaging?
The essentials of Internet messaging
Internet messaging uses the Internet Protocol (IP) on the network layer. Its role is to manage addressing and facilitate the delivery of packets, known as datagrams, from the sending to the receiving address.
Immediately above this layer is the transport layer. This includes TCP (Transmission Control Protocol), UDP (User Datagram Protocol) and the lesser known SCTP (Stream Control Transmission Protocol) and DCCP (Datagram Congestion Control Protocol). Both TCP and UDP are ubiquitous in Internet packet transport and make up the outer frame of almost all data on a network. The latter two are more recent additions to the Internet transport layer.
As the transport layer is so close to the network, it is necessary for networking hardware (the NAT’s) to understand the transport packet framing. As both SCTP and DCCP are not widely understood by such devices, their uptake is inhibited, which creates a vicious cycle as new NAT devices are unlikely to support such poorly known protocols.
The next layer is TLS (Transport Layer Security) which provides optional security capabilities to both TCP and UDP.
The final layer is the application layer. This facilitates additional framing on top of the transport layer, providing such protocols as HTTP, SMTP, SIP and many more.
The application layer protocols typically sit within either a TCP or a UDP frame. UDP is very lightweight and great for large amounts of lossy data. It is also useful for custom protocols and forms the bedrock of many high-speed messaging platforms. TCP, on the other hand, provides many additional built-in features, such as transmission reliability, retransmission and acknowledgments. It also supports changes in bandwidth, breaking packet data into smaller chunks to improve chances of delivery when bandwidth is limited.
Framing
Any data sent from one application to another will exist in one or more frames. The outer frame will almost always be UDP or TCP. Within that frame sits an Application layer protocol frame, such as HTTP. Additional frames may be nested further still until the eventual payload data is reached, though this is not required.
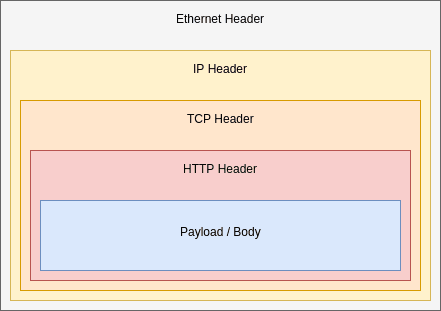
Framing typically consists of a header block and an optional payload. The payload may be a nested frame or raw data.
A frames header provides various details about the packet. This can include (but is not limited to):
- a signature, to identify the frame type;
- the header length;
- the payload length;
- the number of parameters stored in the header;
- the protocol specific header parameters;
- security values such as the packet checksum.
The UDP / TCP layer is modified by the NAT as the packet passes through, whereby both the transport address, port and checksum are translated. The same is also true of well-known nested application frames, such as SMTP, FTP and SIP.
A HTTP packet consists of an Ethernet outer frame, then an IP frame, a TCP frame, the HTTP frame and, finally, the content payload. The sizes of these frames are thus:
| Minimum Header Size | Maximum Header Size | Typical Size | ||
|---|---|---|---|---|
| Ethernet | (fixed) | (fixed) | 24 bytes | |
| IP | (fixed) | (fixed) | 20 bytes | |
| UDP | (fixed) | (fixed) | 8 bytes | |
| TCP | 20 bytes | 60 bytes | 32 bytes | |
| HTTP | no-minimum | no-maximum | 100 – 800 bytes |
The UDP header sizes were included for comparison. As you can see, a simple REST request could result in a response packet size of nearly 900 bytes without counting the actual body content. That is big. If you imagine sending a thousand such requests per second, one could easily envisage needless congestion on internal network sockets.
Selecting a messaging option
When considering your messaging needs, you need to consider both the choice of message transport and the format of the message body.
Message format
Selecting a serialization format for your message body is relatively simple:
- Does the data need to be serialized (such as with non-binary data or complex data types)?
- Does the data need to be read by humans?
- Does the underlying platform provide an easy to use serializer library?
- Is there a lot of data that would benefit from compression?
- Does the data need to be understood by an existing third-party platforms?
There are numerous message formats to choose from. As mentioned earlier, JSON is a commonly selected option due to its clarity, expressiveness, flexibility and its ubiquitous use with REST. Other formats include:
- Apache Avro: a binary serialization format that is more efficient in size than JSON. The format uses JSON to describe the data schema used by the serializer / deserializer.
- ASN.1: is both human and machine readable. Used by telecommunications companies for some time, it is a tried and tested format.
- BSON: is typically more verbose than JSON and not easily human readable. However, it was designed for storage and scanning efficiency, which is perfect for document stores and the like.
- Protocol Buffers: like Apache Avro, is a condensed binary format that utilises readable schemas. Its ubiquity and speed make it an attractive choice.
Transport format
Once you have selected your serialization format, it’s time to decide how to distribute the data. However, this is not straight forward.
Direct messaging
If the active member of a message exchange is aware of all data that passes through it, then the connection between the active partner and its peer can be simplified.
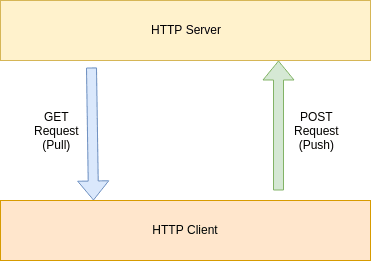
Data can be pushed or pulled along a transport. If a service has data and needs to send it somewhere specific, then the data is pushed. If the data exists somewhere and is required by a service, then it is pulled.
In the case of REST, both transit types are experienced. Data is typically pushed and pulled with every request, whether the intent is to send data, retrieve data or both. However, pushing and pulling data is considered intentional; thus a request for a file download is a pull, while POSTing data for storage is considered a push.
Under such circumstances, the transport may be a simple UDP or TCP socket. If the data is a continuous stream and of a lossy format (it can recover if packets are dropped, such as some video or audio streams), then UDP is a good fit. If, however, you require a guarantee of your data’s delivery (or to be notified if it fails), then TCP is a good choice. Then, of course, there are various application level formats that build on these.
Differences between framing and serialization
The data that forms a packet header is simply bytes. The same can be said of the body. As such, at the application level, the data sent between services can be a packet, a serialized body or both.
Framing exists at a lower level to control throughput. For instance, values stored in a TCP frame provide segments that tell the TCP socket library utilised how to manage the incoming and outgoing data. This exists simply to make it easier for the higher level application. If the TCP handles packet retransmission and acknowledgements, then the application doesn’t have to.
When working with your own data, you may choose to implement your own control functionality and implement your own headers, using your own framing technique. Alternatively, if commands are what you require, you may choose to embed them in the serialised body itself.
As an example, the Redis database’ utilizes TCP sockets for its client utilities. Then, rather than further framing the packet data with commands such as SELECT, SET and INCR, the commands form part of the serialisation format; for instance:
*2\r\n$4\r\nLLEN\r\n$6\r\nmylist\r\n
This can be rewritten as:
*2 // the packet is an array of two elements $4 // the first is an element (a command) of 4 characters LLEN $6 // the second is a value of 6 characters mylist
This, then, would be viewed by the database as the command:
LLEN mylist
The difference between the RESP (REdis Serialization Protocol) format and framing is simply that the metadata describing the packet is inline. If, however, the format was defined as:
*2\r\n\$4\r\n$6\r\nLLEN\r\nmylist\r\n
then one could aptly view it as a frame, since the entirety of the body data follows the meta.
Message brokering
Oftimes, in order to benefit from service encapsulation, the messages emitted or available from an applications services are not known, are not available, or are simply intentionally ambiguous. For instance, it might be that a given service within your cluster produces animated GIFs. Several other services within your application make use of notifications from these generated images; one service logs the image meta to a data store, one service sends an email to the initiator and another service watermarks the image.
At such times, it may not make sense to have each of these services connect to the GIF generating service directly; it doesn’t make sense for the GIF generator to know the existence of each of the other services, and the logging service may log data from every service in your application. Ensuring the logging service is aware of all the other services in your application is far more work than is necessary.
Such notifications can be considered Events. Much like within monolithic applications development, it should be possible to publish and subscribe to these notifications without hardcoding the relationships between services and, indeed, is made possible through the use of brokers.
Since a broker is independent of your services, the service technology doesn’t need to match your service implementation. There are numerous message broker implementations; a handful of which include:
- Apache Kafka: works on streams of data, such as time-based logging, using pipelines.
- RabbitMQ: is an AMQP (application level framing) messaging broker.
- Apache ActiveMQ: is a multi-frame supporting message broker.
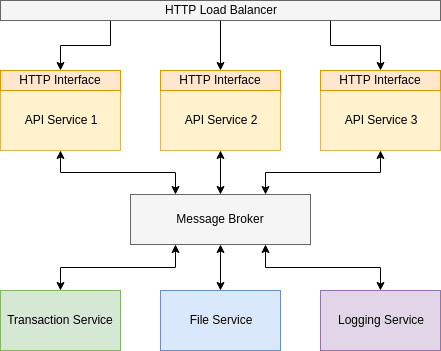
Each broker provides different capabilities and are beneficial under different circumstances. The broker you choose should depend on the requirements of your application, but it is possible to alleviate a lot of coding within your services by choosing the right broker.
Broker functionality may include:
- short and long term storage of messages
- fault tolerance
- high availability, increasing the HA of your overall application
- message inspection and visibility using a console or web interface
- additional security, filtering messages restricted from services that do not have the correct permissions
Another great aspect of brokering messages is the additional message patterns they may support. RabbitMQ, for instance, supports several patterns, including:
- Fan-out. The fan-out pattern is a means of distributing messages to all listening queues. Essentially, any service listening to the broker will receive a fan-out message.
- Topic exchange. Here, messages are routed based on partial queue key patterns. If, for example, there are three queues with the paths
users.forms.data,users.access.dataandfiles.forms.submitted, then the topic*.forms.*will match two of the queues, whilefiles.*.*will match one of them. - Header exchange. The header exchange sends packets based on filtering of packet header values. Using this exchange, packets essentially sort themselves based on type rather than knowing explicitly where to send the message.
Conclusion
There are many options when it comes to messaging. Simply choosing what you know is not always the best approach. By thinking your requirements through, it’s possible to save yourself a lot of work in the long term, but also improve the speed and efficiency of your application on the whole.
| Published on Java Code Geeks with permission by Lee Sylvester, partner at our JCG program. See the original article here: Microservices Messaging: Why REST Isn’t Always the Best Choice Opinions expressed by Java Code Geeks contributors are their own. |

So basically zeromq for microservice messaging for the win outsode the external api? Then the zeromq book covers the whole topic and we don’t need this article?
My suggestion: Instead of internal POST requests use Message Broker like Apache Kafka.
Instead of internal GET requests, use again Kafka request/reply patterns. HTTP fails too much, so this is one of the good solutions.
I think with header compression in HTTP2, REST does not have such overhead.