
How we realized the old way of solving errors in pre-production is not enough, and how we were able to change that
There’s no such thing as perfect code on the first try, and we can all testify that we’ve learned that the hard way. It doesn’t matter how many test cycles, code reviews or tools we use, there’s always at least one sneaky bug that manages to surprise us.
In the following post, we’ll share our own story of such a bug, the common workflow that developers use to solve it compared to the new way we do it at OverOps. Spoiler alert: log files don’t cut it, and now it’s time to understand why.
Big shoutout to Dor Levi who helped us through this issue and post!

Act I: Detecting there’s an issue
A couple of weeks ago our AWS server started sending out distress signals. Our QA team came across it during one of their tests, and complained that the server couldn’t handle their load testing. They turned to our VP R&D seeking help. The VP R&D pulled out his credit card, increased the server load and told QA that the issue was fixed.
As you can guess, the problem was far from over. After the second cycle of complaint -> increasing AWS payment -> complaint, we realized that there’s more to this issue and it needs further investigation. We had to figure out what went wrong, and our first step was to open the Amazon CloudWatch Monitoring Details, which gave us the following chart:
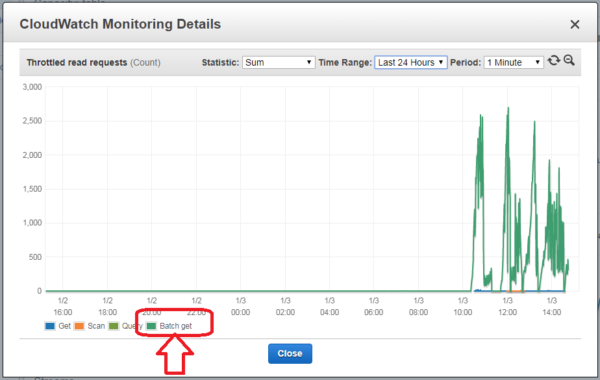
As you can see, the “batch-get” request started to go haywire right after 10:00 AM, consuming an ever-growing amount of resources and failing operations, effectively causing an outage of the staging environment on which QA were running load tests.
While the data Amazon provides can tell us which type of operation is causing the issue, it can’t tell us where it is coming from and why is it happening in the first place. It was time to roll up the sleeves and start digging inside the code. Read the full whitepaper to find out what we did next.


What type of clickbait is that? If you don’t want to share your stuff with the public, don’t post it here! Why do I need to download the information from a third party site?