This is the third article from the series about OpenHub framework – the first introduced OpenHub framework and the second presented asynchronous messaging model.
This last article from the series will introduce some other interesting features in more detail and it will show the reasons why OpenHub can be a good choice for your integration project.
Throttling
Throttling is a functionality that checks the count of input requests to integration platform and if this count exceeds the defined limit then new requests are restricted.
The main goal of throttling is to limit disproportionate (and often wilful) overload of integration platform with huge amount of input requests for processing. This would have bad impact on the application performance and it can even stop the processing of current messages.
Throttling component counts input requests from specified source (external) system and for specific operation. If this count exceeds the defined limit in the defined time interval then OpenHub will start to reject new input requests (only requests from specified source system and for specified operation) – exception is thrown. Throttling component supports cluster.
Throttling functionality can be configured as follows:
############################################################################### # Throttling configuration # # There the following property names: # - throttling.defaultInterval: default time interval (in seconds) if not defined by system/operation # - throttling.defaultLimit: default limit if not defined by system/operation # - throttling.sourceSystem.operationName, where # - sourceSystem is specific source system or '*' if any system # (source system is case-insensitive value from trace header (ExternalSystemExtEnum)) # - operationName is specific operation name or '*' if any operation # # Property values (except for default values) have the following format: # limit [/interval] # # Examples: # throttling.crm.op1=10 # throttling.crm.*=10/40 # throttling.*.sendSms=60/30 ############################################################################### throttling.defaultInterval=60 throttling.defaultLimit=60 throttling.sourceSystem.*=300/60 throttling.*.syncHello=15/60 throttling.*.asyncHello=50/60
For example:
throttling.crm.op1=10 (restriction to calls of operation op1 from CRM system to 10 requests for 60 seconds)
throttling.crm.*=10/40 (restriction to calls of any operation from CRM system to 10 requests for 40 seconds)
throttling.*.sendSms=60/30 (restriction to calls of operation sendSms from any system to 60 requests for 30 seconds)
Alerts
Alerts define metrics for watching database data and if any metric exceeds its limit then alert is activated and further operation can be executed.
Metrics are configurable – the SQL query for getting count of items and limit for checking.
Examples of alerts (also with follow-up operations):
- when count of failed messages for last 10 minutes exceeds 5 then sends email to administrators
- when count of messages which wait for response from external system for more then 5 minutes exceeds 10 then sends email to administrators
Example of the default configuration:
############################################################################### # Alerts configuration # # There the following property names: # - alerts.N.id: unique alert identification (if not defined then order number (=N) is used instead) # - alerts.N.limit: limit that must be exceeded to activate alert # - alerts.N.sql: SQL query that returns count of items for comparison with limit value # - [alerts.N.enabled]: if specified alert is enabled or disabled; enabled is by default # - [alerts.N.mail.subject]: notification (email, sms) subject; can be used Java Formatter placeholders (%s = alert ID) # - [alerts.N.mail.body]: notification (email, sms) body; can be used Java Formatter placeholders (%d = actual count, %d = limit) # ############################################################################### # checks if there is any waiting message that exceeds time limit for timeout alerts.900.id=WAITING_MSG_ALERT alerts.900.limit=0 alerts.900.sql=SELECT COUNT(*) FROM message WHERE state = 'WAITING_FOR_RES' AND last_update_timestamp < (current_timestamp - interval '3600 seconds')
Note: Every configuration can be set via JMX on the fly.
Scheduled jobs
There are two types of the scheduled jobs which OpenHub supports:
- jobs which can run on random node and can be executed concurrently (it’s not condition to start jobs in the same time)
- jobs which can run only once in the cluster, no matter on which node (note: we don’t take into consideration the possibility that a scheduled job has to run on specific node only)
OpenHub framework offers own API for jobs definition.
Configuration examples:
@OpenHubQuartzJob(name = "AsyncPostponedJob", executeTypeInCluster = JobExecuteTypeInCluster.NOT_CONCURRENT,
simpleTriggers = @QuartzSimpleTrigger(repeatIntervalMillis = 30000))
public void invokePostponedJob() {}
@OpenHubQuartzJob(name = "MoreTriggerJob", executeTypeInCluster = JobExecuteTypeInCluster.CONCURRENT,
cronTriggers = {
@QuartzCronTrigger(cronExpression = "0 00 23 ? * *",
name = "FirstTriggerForJob",
group = "MoreTriggerGroup"),
@QuartzCronTrigger(cronExpression = "0 00 10 ? * *",
misfireInstruction = CronTriggerMisfireInstruction.FIRE_ONCE_NOW,
name = "SecondTriggerForJob",
group = "MoreTriggerGroup")},
simpleTriggers = {
@QuartzSimpleTrigger(repeatIntervalMillis = 10000,
repeatCount = 20,
name = "ThirdTriggerForJob",
group = "MoreTriggerGroup"),
@QuartzSimpleTrigger(repeatIntervalProperty = ASYNCH_PARTLY_FAILED_REPEAT_TIME_SEC,
intervalPropertyUnit = SimpleTriggerPropertyUnit.SECONDS,
misfireInstruction = SimpleTriggerMisfireInstruction.FIRE_NOW,
name = "FourthTriggerForJob",
group = "MoreTriggerGroup")
})
public void invokeJob() {}
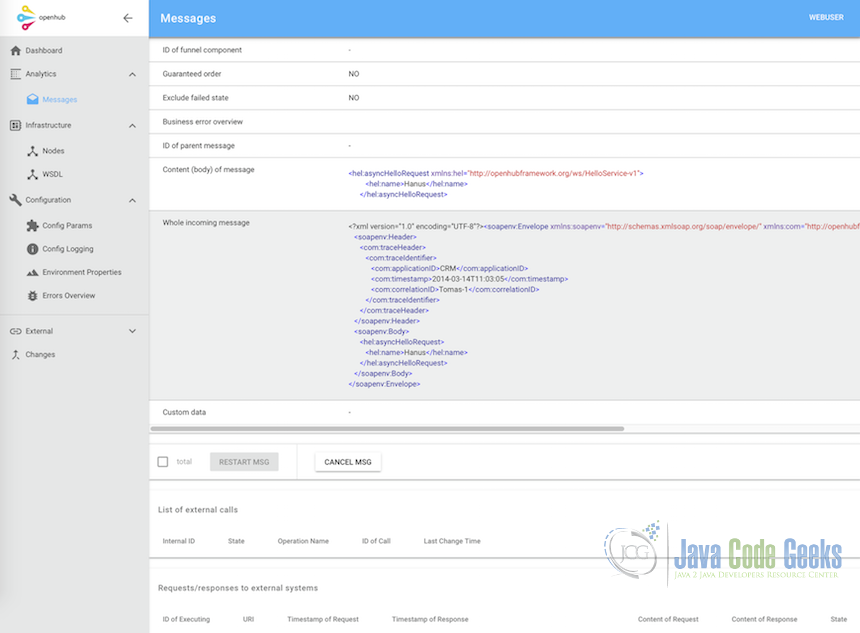
Request/response tracking
Request/response tracking functionality allows to save internal communication between routes or communication with external systems into database. Afterwards you can go directly into database and go through request and response tables or look at admin console.
Error handling
There is a basic error handling in Apache Camel but OpenHub framework has its own concept how to handle errors:
- there is own exceptions hierarchy with basic IntegrationException
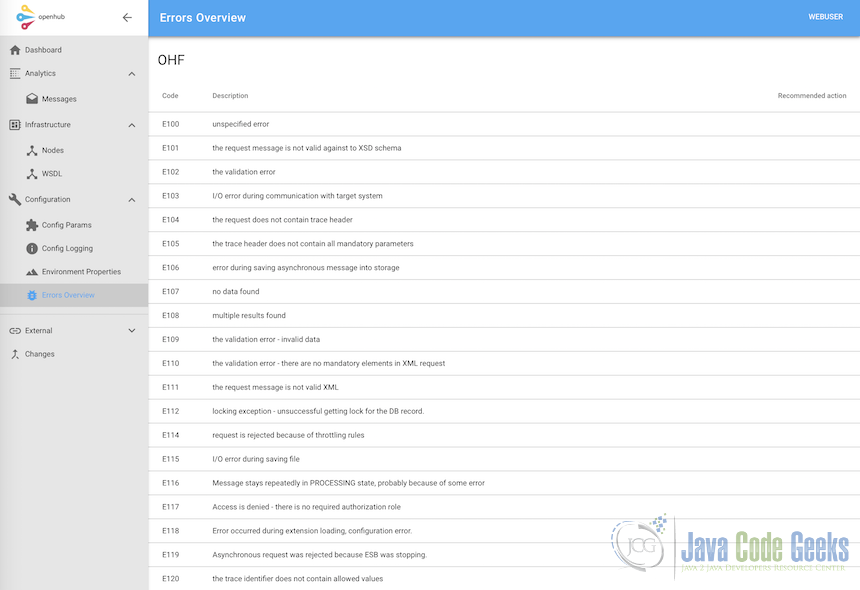
- there is error catalogue that defines unique error codes with descriptions – this helps to identify problems in the source system
- error catalogue is presented in admin console