What’s the ultimate alerting strategy to make sure your alerts are meaningful and not just noise?
Production monitoring is critical for your application’s success; from going manually over the logs, through using 3rd party tools or homegrown solutions – to each of us its own. However, there are some elements and guidelines that can help us get the most out of our monitoring techniques, no matter what they are.
In order to help you develop a better workflow, we’ve identified the top ingredients your alerts should have to be meaningful. Sugar, spice and everything monitored. Let’s check them out.
Table of contents
1. Timeliness – Know as soon as something bad happens
Our applications and servers are always running and working, and there’s a lot going on at any given moment. That’s why it’s important to stay on top of new errors when they’re first introduced into the system.
Even if you’re a fan of sifting through log files, they will only give you a retroactive perspective of what happened to the application, servers or users. Some would say that timing is everything, and getting alerts in real time is critical for your business. We want to fix issues before they severely impact users or our application.
This is where 3rd party tools and integrations are valuable, notifying us the minute something happens. This concept might not sound as nice when an alert goes off at 03:00 AM or during a night out, but we can’t deny its importance.

TL;DR – When it comes to production environment every second counts, and you want to know the minute when an error is introduced.
2. Context is key to understanding issues
Knowing when an error has occurred is important, and the next step is understanding where is it happening. Aleksey Vorona, Senior Java Developer at xMatters, told us that for his company context is the most important ingredient when it comes to alerts; “Once an error is introduced into the application, you want to have as much information as possible so you can understand it. This context could be the machine on which the application was running on, user IDs and the developer that owns the error. The more information you have, the easier it is to understand the issue”.
Context is everything. And when it comes to alerts, it’s about the different values and elements that will help you understand exactly what happened. For example, it would benefit you to know if a new deployment introduced new errors, or to get alerts when the number of logged errors or uncaught exceptions exceeds a certain threshold. You’ll also want to know whether a certain error is new or recurring, and what made it appear or reappear.
Breaking it down further, there are 5 critical values we want to see in each error:
- What error was introduced into the system
- Where it happened within the code
- How many time each error happened and what is its urgency
- When was the first time this error was seen
- When was the last time this error occurred
These were some of the issues we had to face ourselves here at OverOps, trying to help developers, managers and DevOps teams automate their manual error handling processes. Since each team has its own unique way of handling issues, we created a customizable dashboard in which you can quickly see the top 5 values for each error. OverOps allows you to identify critical errors quickly, understand where they happened within the code and know if they’re critical or not.
TL;DR – You need to know what, where, how many and when errors and exceptions happen to understand its importance and urgency.
3. Root cause detection – Why did it happen in the first place?
Now that we’re getting real time alerts with the right context, it’s time to understand why they happened in the first place. For most engineering teams, this would be the time to hit the log files and start searching for that needle in our log haystack. That is, if the error was logged in the first place. However, we see that the top performing teams have a different way of doing things. The full research will be shared on our upcoming webinar on October 25th. Check it out.
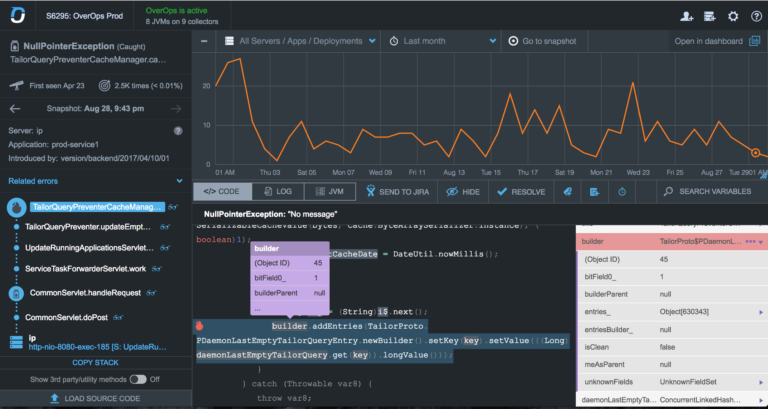
Usually, applications fire hundreds of thousands or even millions of errors each day, and it becomes a real challenge to get down to their real root in a scalable manner without wasting days on finding it. For large companies such as Intuit, searching through the logs wasn’t helpful; Sumit Nagal, Principal Engineer in Quality by Intuit points out that “Even if we did find the issues within the logs, some of them were not reproducible. Finding, reproducing and solving issues within these areas is a real challenge.”
Instead of sifting through logs trying to find critical issues and closing tickets with a label stating “could not reproduce”, Intuit chose to use OverOps. With OverOps, the development team were able to immediately identify the cause of each exception, along with the variables that caused it. The company was able to improve the development team’s productivity significantly by giving them the root cause with just a single click.
TL;DR – Getting to the root cause, along with the full source code and variables, will help you understand why errors happened in the first place.
4. Communication – Keeping the team synced
You can’t handle alerts without having everyone on the development team on board. That’s why communication is a key aspect when it comes to alerts. First of all, it’s important to assign the alert to the right person. The team should all be on the same page, knowing what each one of them is responsible for and who’s working on which element of the application.
Some teams might think that this process is not as important as it should, and they assign different team members to handle alerts only after they “go off”. However, that’s bad practice and it might not be as effective as some would hope.
Imagine the following scenario: it’s a Saturday night and the application crashes. Alerts are being sent to various people across the company and some team members are trying to help. However, they didn’t handle that part of the application or the code. You now have 7 team members trying to talk to each other, trying to understand what needs to be done in order to solve it.
This is caused due to lack of communication in earlier parts of the project, leading to team members to not being aware of who’s in charge, what was deployed or how to handle incidents when alerts are sent out.

TL;DR – Communication is important, and you should work on making it better as part of your error handling process.
5. Accountability – Making sure the right person is handling the alert
Continuing our communicational theme from the previous paragraph, an important part of this concept is knowing that the alert reaches the right person, and that he/she are taking care of it. We might know which team member was the last one to handle the code before it broke, but is he the one responsible for fixing it right now?
On our interview him, Aleksey Vorona pointed out that it’s important for him to know who’s the person in charge of every alert or issue that arises. The person who wrote the code is more likely to handle it better than other members of the team, and he’s most likely to apply a faster fix than others.
The bottom line is that it doesn’t matter what you do, as long as you know who’s doing what. Otherwise, your alerts might pile up and it’ll take a while to filter the critical ones from the known issues – which will lead to unhappy users, performance issues or even a complete crash of servers and systems.
TL;DR – Team members should be responsible for their code throughout the development process, even after the code was shipped to production.
6. Processing – Alerting handling cycle
You have your team members communicating and working together, which is great. However, you still need to create a game plan that the team will aspire to achieve. A good example of a game plan is having an informed exception handling strategy rather than treating each event in isolation.
Exceptions are one of the core elements of a production environment, and they usually indicate a warning signal that requires attention. When exceptions are misused, they may lead to performance issues, hurting the application and its users without your knowledge.
How do you prevent it from happening? One way is to implement a “game plan” of an Inbox Zero policy in the company. It’s a process in which we handle unique exceptions as soon as they’re introduced, acknowledging them, taking care of them and eventually eliminating them.
We’ve researched how companies handle their exceptions, and found out that some have the tendency to treat them at a “later” date, just like emails. We found out that companies that implement an inbox zero policy have better understanding on how their application work, clearer log files and developers can focus on important and new projects. Read more about it.
TL;DR – Find the right game plans for you and implement them as part of a better alerting handling process.
7. Integrations? Yes please
Handling alerts on your own might work, but it’s not scalable in the long run. For companies such as Comcast, servicing over 23 million X1 XFINITY devices, it’s almost impossible to know which alerts are critical and should be handled ASAP. This is where 3rd party tools and integrations will be your best friends.
After integrating OverOps with their automated deployment model, Comcast were able to instrument their application servers. The company deploys a new version of their application on a weekly basis, and OverOps helps them identify the unknown error conditions that Comcast didn’t foresee. Watch John McCann, Executive Director of Product Engineering at Comcast Cable explain how OverOps helps the company automate their deployments.
Integrations can also be helpful in your current alerting workflow. For example, Aleksey Vorona from xMatters works on developing a unified platform for IT alerting, and developed an integration with OverOps. The integration allows the company to get access to critical information, such as the variable state that caused each error and alert the right team member.
TL;DR – Use third party tools and integration to supercharge your alerts and make them meaningful.
Final thoughts
Alerts are important, but there’s much more to it than just adding them to your application. You want to make sure you have information on why they happened in the first place, how you should handle them and how can you make the most out of them (vs. just knowing that something bad happened). Our basic recipe aims to help you create a better process, and it’s waiting for you to add the special ingredient that’s important for your team, company and workflow.
What are your top alerting ingredients? We would love to hear about them in the comments below.
| Published on Java Code Geeks with permission by Henn Idan, partner at our JCG program. See the original article here: Meaningful Alerts: 7 Must-Have Ingredients to Prevent a Production Crisis Opinions expressed by Java Code Geeks contributors are their own. |
