In my previous article, I discussed how to maintain Resiliency in Microservice/Distributed Architecture. In this tutorial, I will discuss Distributed Service Registry.
What is a Distributed Service Registry?
In a service registry pattern, all the services are registered in a Registry(A Map Data Structure). If any service needs an instance of another service it contacts Registry and gets the service instance. Very simple isn’t it? But when we deal with a distributed environment it’s getting highly complex.
Let’s discuss why it is getting so complex in a distributed environment. When we are talking about the distributed environment we assume that each service is deployed in a separate web server/application server. To be very simple each service runs in a separate JVM. per service per JVM. As Service registry holds the service name and its instances in a key/Value pair so we need a centralized system which only maintains this service registry and performs CRUD operations on it and each service contacts this registry for getting required services, so far so good. But the problem is when we make service registry centralized i.e a separate service or JVM we bring a Single point of failure in our architecture. Think about the scenario that the Service registry is unavailable, then our application falls down as no service can contact service registry so it not gets the desired service and fails. So makes service registry centralize is a bad idea.
See the following picture and think how can we improve the architecture.
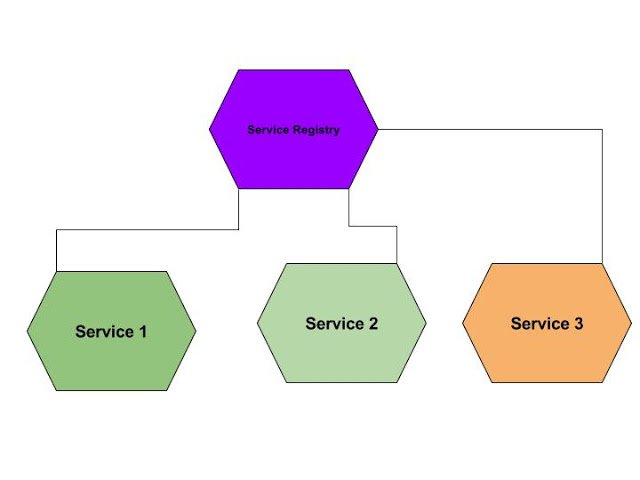
One thing we can do to improve the architecture if we maintain multiple instances of Service registry so if one is unavailable other can serve the purpose then there will be no SPF(Single point of failures).
Distributed Service Registry Algorithm
The idea is like there will be one Leader Node(Service registry) all the CRUD operation applied on this node, and it is leader node duty to distribute the updated state of the registry to another Service registry(peer nodes). Although by reading it seems very easy and robust solution but it is very complex to implement and a new set of challenges comes with this architecture.
I am trying to talk about the challenges one by one
Leader Election: As the Service registries are connected to each other How we can select one node as a Leader? Also if that node fails basis on which we will elect another leader who will take over the responsibility?
State Synchronization: As there are multiple service registry nodes now the question is if the Leader registry gets updated by adding a new instance or deleting an instance then how leader node distribute that state to others and how it becomes to know that all nodes are updated with the latest state?
To solve these problems Distributed registry takes help from Algorithm.
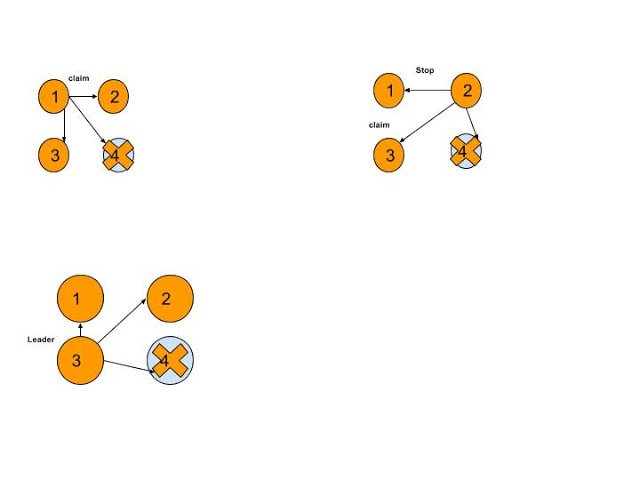
Bully Algorithm for Leader Election: In Bully algorithm each node/Service registry has a process Id, greater process Id will select as the Leader node. Suppose assume Leader node is not available then How Bully Algorithm selects the next leader?
Step 1: When a node discovers that Leader node is unavailable it starts the election by sending a claim message to all other nodes who have greater id than this node.
Step 2: When greater nodes are received this claim message, they either show interest or not provide the response for the message. If they are interested they send previous node a response to stop as they will take it from here and send claim message to all other nodes which have greater Id than this.
Step 3: If it does not receive any response from the higher node, then it selects itself as Leader node and sends message to all other nodes by saying it is the Leader.
State Synchronization by Consensus: If any instances are added or deleted from the leader node it has to be reflected on other nodes so every service registry got the same value. To decide the correct state of the registry majority of the node has to agree on a certain value/latest value. And faulty nodes needs to update its state to be sync with other nodes and system will be eventually consistent.
Consensus works on two major criteria
Value proposition: Each node/Service registry propose a value.
Agreement: Majority of the node should agree on the proposed value.
A consensus algorithm works in following way
Termination
Every node decides some value.
Validity
If all registry proposes the same state say X, then all correct nodes decide X as an updated state.
Integrity
Every correct node decides at most one value, and if it decides some value X then X must have been proposed by Leader Node.
Agreement
Every correct process must agree on the same value X.
Conclusion: To maintains a Highly available and fault tolerant service registry in a distributed system Consensus and Leader election is the main techniques to be followed.
| Reference: | Deep Dive to Distributed Service Registry from our JCG partner Shamik Mitra at the Make and Know Java blog. |
