Editor’s Note: At Strata+Hadoop World 2016 in New York, MapR Director of Enterprise Strategy & Architecture Jim Scott gave a presentation on “Handling the Extremes: Scaling and Streaming in Finance.”
As Jim explains, agility is king in the world of finance, and a message-driven architecture is a mechanism for building and managing discrete business functionality to enable agility. In order to accommodate rapid innovation, data pipelines must evolve. However, implementing microservices can create management problems, like the number of instances running in an environment.
Microservices can be leveraged on a message-driven architecture, but the concept must be thoughtfully implemented to show the true value. In this blog post, Jim outlines the core tenets of a message-driven architecture and explains its importance in real-time big data-enabled distributed systems within the realm of finance. Along the way, Jim covers financial use cases dealing with securities management and fraud – starting with ingestion of data from potentially hundreds of data sources to the required fan-out of that data without sacrificing performance – and discusses the pros and cons around operational capabilities and using the same data pipeline to support development and quality assurance practices.
You can watch Jim Scott’s presentation here or read his blog post below to learn more:
Legacy Business Platforms
To set the stage, let’s start off with a story. One day, my boss comes up to me and says, “We need to build out some new software for this new use case to meet our customer needs,” and asks me what I can do. In this situation, I look at the operational side, because I have to build a transactional-based system, and so that means: I need storage, and I need a relational database – since that is the tool that everybody has been using for the last 20 years to solve every single business problem that exists. In addition, we’re Java-based, so we’re going to use a J2EE app server, plus I’ll want to implement a message-driven architecture.
We get this standard set-up in place; it works well, scales wonderfully, and meets all of our needs. But then, a handful of months later, my boss has a new request: “How can we cross-sell our products to our customers? Who are our top 10 users?” Now we need an analytical platform. So what do we do? We build out another set of specialized storage and we get another database. And since it’s going to be our data warehouse, we have to put an ETL tool in place, because we’ve got to get our data out of our operational database, and then of course, we need to have some BI tools there.

After I build this out, my boss is pleased with the results and compliments me on my work. Then he says, “But,” and here’s the big but: “We need to have full depth of history, because we have new features we want to put back into this user interface. We want to customize the experience on the fly. We want to be able to make better live recommendations.”
Can you productionize that data warehouse to meet the same service level that you have on the operational side? Well, technically, you can, if you throw enough money at it. But you will still have to keep your fingers crossed, hoping that it does not fall over on its face under peak load. The problem here is that the IT team has to go through a lot of extra integration work. And there’s a significant cost to scale up in the enterprise data warehouse world. It is drastically expensive.
Converged Data Platform
We’re accustomed to having two sets of completely separate specialized storage and platforms with completely different data models – one for analytical applications and one for operational applications. The data model looks different for operations versus data warehouse because of the speed and availability that you need to get the data to the user in time. Denormalization for the data is another concept in place for the same reason: we’ve had to make trade-offs to use a relational database to solve every problem we’ve had. While we’ve done it this way for a long time, we can make changes to our infrastructure to become a more nimble, more agile organization. The foundational piece of building a next generation platform is to converge these separate spheres.
When you’re dealing with two different data models, you often hear: “I want to pick the right tool for the job.” The RDBMS is the answer because the IT team supported it to get the software into production, and they have already figured out backup strategies. When you work on the analytics side, you’re creating BI reports or KPIs on data warehouse, or doing data science modeling, and so you need history. When you work on the developer side, you are create databases to support persistence and have a need for event-based applications. You have APIs to work against, you need to persist your data to a database, and you want to have a message-driven architecture, all of which support the operational side of your company.
The converged data platform plays a pivotal role in changing this dichotomy. The beauty of this model is that when you operate in a converged data platform, you have everything in one place. You don’t have to move your data from one schema to another. You don’t have to go through a transformation to be able to query the data. Both sides can work on this information at the same time. With converged applications, you have complete access to real-time and historical data in one platform.
We have customers that operate in this model, especially in the financial industry, and they typically ask us this important question: “I need to be able to ask the same question two times in a row and get the same answer, and if I’m doing analytics on my operational platform, how do I do that?” That, in fact, is where MapR comes into the picture, because for this type of platform, you can take a consistent point-in-time snapshot of all of the data, whether it’s an event stream, the database, or files in the system.
As a result, you can build your models against a consistent point-in-time view. When you’ve got all your analytics in place, you point at the real-time data, and you’re done. There’s no extra work, and it’s a copy-on-write filesystem, so you don’t have to figure out how to operationalize it or how to enable a team to support it.
Application Development and Deployment
Why is this important? Well, number one, you can reduce the total amount of time it takes with a document database to persist your data with a single line of code, because every single language has JSON serializers and deserializers. One line of code enables you to persist your data structures to the database or with one line of code you can pull it out of the database and put it in your data structure.
A decade ago, to build a software stack, they didn’t need to be ultra-creative. It was a simple design. They didn’t have the capabilities to spend crazy amounts of money on these different technologies. The open source movement with all of the options that we now see in the ecosystem hadn’t yet flourished. But today this is what it looks like:
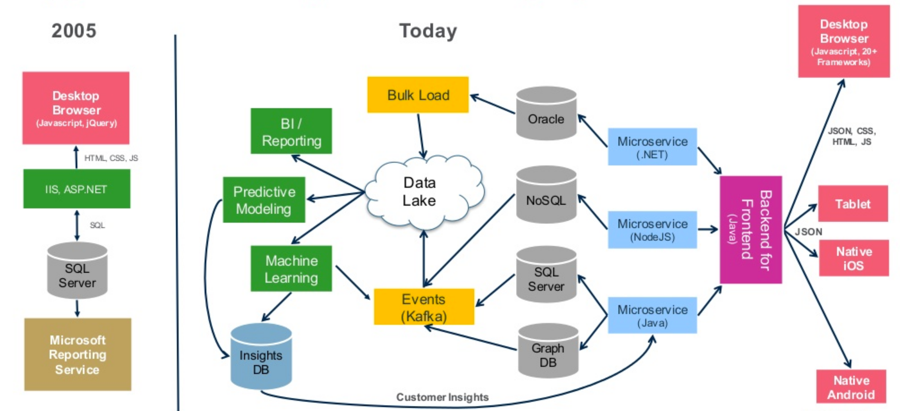
You have different data stores for different use cases. As soon as you have more than one database, and pretty much every company has more than one database, you start creating data silos. Once your data is siloed, you have to figure out how to integrate and how to bring everything together to deliver your capabilities. However, with MapR, you can actually do all of these things on the same platform.
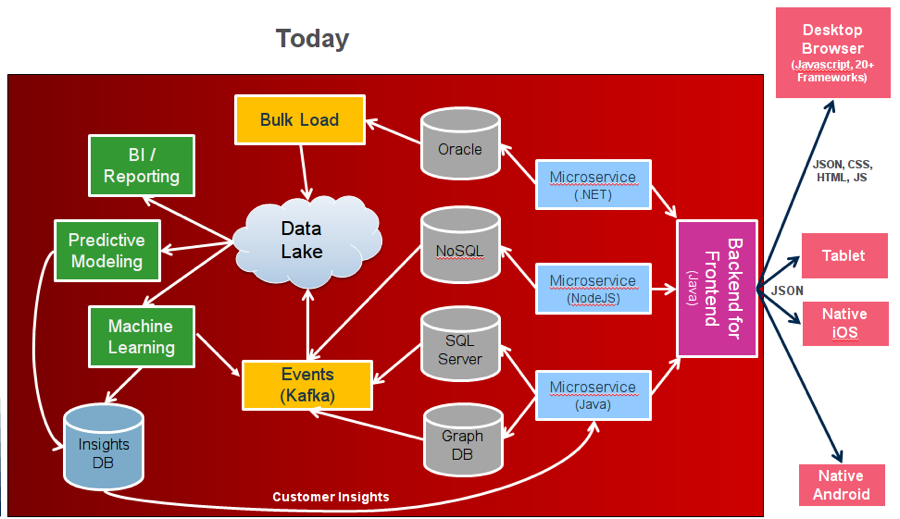
That doesn’t necessarily mean that you do it all in one cluster, but you have all of the enterprise capabilities for any of those features. You can perform analytics across any or all of them simultaneously.
MapR Platform Services: Open API Architecture
MapR Platform Services provide an open API architecture, which assures interoperability and avoids vendor lock-in. That’s a big deal, because it means you will be able to pick and choose what works for you when it works for you.
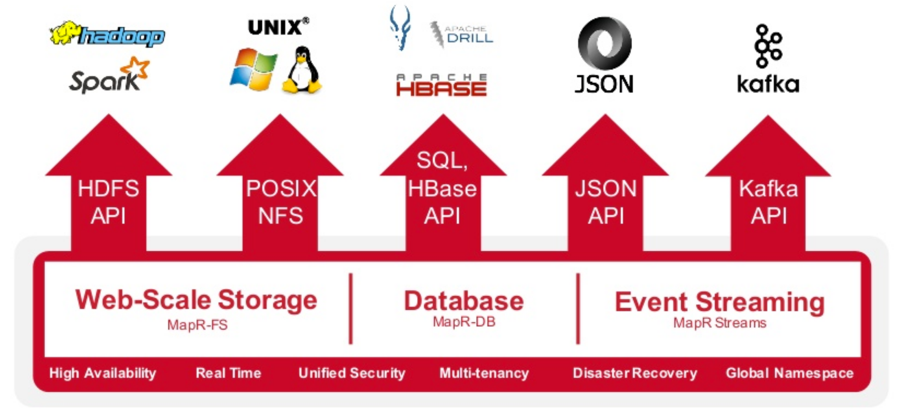
- MapR-FS supports the HDFS API, which enables distributed computation. You can use any open source engine or tool, like Spark or Apache Flink, that supports the HDFS API, and it will work everywhere.
- MapR-FS is a POSIX file system, which allows you to read and write directly to a MapR cluster. You may have an Apache web server in your business, and you write your logs on the server; you then use something to transport your logs to do analytics on it later. Wouldn’t it be amazing to write your logs directly through to the same platform where you are performing your analytics?
- MapR-DB allows you to have different types of query capabilities and a key value data store. You are able to store JSON documents and do mutations on documents in the database with speed and simplicity.
- MapR Streams allows you to handle event streaming. And with the Kafka API, you have the ability to run on-premise or in the cloud. You can handle events coming in anywhere. You can replicate them to anywhere else.
- With this Open API Architecture, you can also leverage cloud as infrastructure as a service. If you have an event-driven architecture and you are responding in real time, altering a user’s session as it goes, you have the ability to build that in one place and do analytics on the whole thing, any time you want, without having to figure out how to move your data between two different locations and whether or not you have enough storage to do so. When you aren’t bound to APIs that lock you into a cloud provider, you have the freedom and flexibility to pick any infrastructure platform. If a new company comes along and, for example, offers you bare metal access, you can switch providers. You handle replication as part of the platform. You don’t have to write all of those capabilities – snapshots, mirroring, replication of tables, events as they happen – that you need to deliver solutions for your business, allowing you to focus on the core competencies of your company.
I love to tinker and write code as much as anybody out there, but at the end of the day, the benefits of the open source ecosystem is that you can solve problems faster. Putting the tools that you want in your hands and enabling them across a single consistent data platform gives you the ability to pick and choose your applications, figuring out what works for you.
Messaging Platforms
What’s a stream? A stream is an unbounded sequence of events carried from a set of producers to a set of consumers. Producers produce events; consumers consume events.
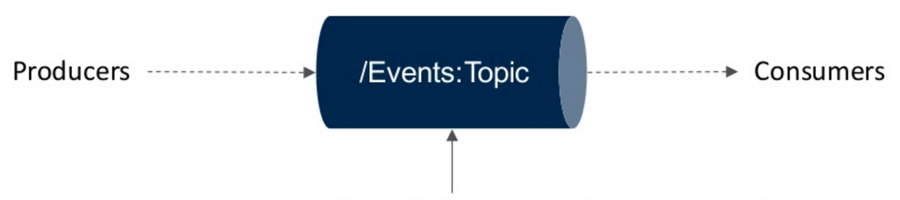
Very simply put: if I were a newspaper publisher, I would have a stack of newspapers, which I produced; when you’re ready to consume, you would come and pick up your newspaper. That’s the concept of a message queue. Producers and consumers don’t have to be aware of each other; instead, they participate in shared topics. This publish/subscribe model is where you can really pick up speed. When you start looking at the different types of event topics and how you want to process them, you need to figure out how to deal with the extremes of streaming.
What do I mean by extreme? I measure extreme as about a trillion plus events per day. I see potentially millions of producers or billions of events per second flowing through a system with multiple consumers.
This is extremely important because as you create a message-driven architecture, as you want to roll out new versions of code, you want to build new services, and you want to be able to connect to the official production stream and test. For a developer, this would be the utopian situation, being able to have access to real production data to see if the code really works, while still getting isolation in the events. If you’re using remote procedure calls, you have a tight binding between the components talking to each other. But when you go message driven, suddenly you’ve decoupled it. You now have the ability to test and move at the pace that you want to. You have full depth of history of events that have occurred over time for you to be able to operate on.
In addition, I consider multiple data centers as extreme. With the advent of cloud, if you have a web-facing presence to customers and you are running on a single cloud, I would argue that you have an opportunity to go multi-cloud and load balance (50/50 or some variation therein) between multiple data centers. You would then have global availability of your data. You can replicate across those data centers, and you don’t have to worry about having issues with a single cloud provider. Ultimately, you end up being able to meet different service levels different ways, because you can pick and choose which hardware and infrastructure services you use to meet your needs. And then your options are limitless: you can do streaming events in the clouds, have an on-prem data center, take aggregated information back to your data center, do analytics for fraud detection and build models around user profiles, etc.
Because of tools like MapR Streams and Kafka that allow you to break down services and applications, there is now a push to be able to support the concept of micro-services more readily, so that you have the ability to deploy smaller components into your environment. And so, for every one of those micro-services you deploy, you’re going to want to monitor every aspect of each component and emit your own metrics to gauge its performance. How many people are coming through your service? What features are being used?
When you start adding up all the different metrics you produce, the sample rate that you produce at, the ability to capture that information and push it through an event stream, you’re looking at almost 2 billion events per day with this simple setup. A couple billion events per day is realistic, and when you start taking into account, “I want to produce more of my software against the original production data coming through my stream,” your developers can now consume from that production stream to test the new code they’re putting out. Every time you add, you’re multiplying out, that many more times, the number of instances running in this environment.
How difficult is it to use this model? It is very simple and easy to write a couple of lines of code to produce an event, which go through the stream, and then it only takes a few lines of code for the consumers to be able to read from the stream.
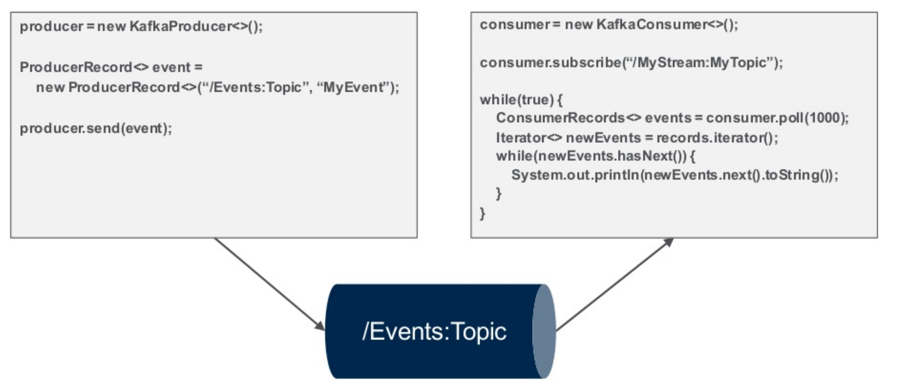
You now have the ability, when you think about web services, to take your back end or your front end, and you could have calls coming into it, and it could be proxying out to a whole bunch of other services. Every one of those services could be message driven, completely decoupled, and asynchronous; you could write the message going to the micro-service that it’s listening to, and it could then put it on a return topic on the same stream. It’s very easy to set up, automate, and manage: you could take the same topic name and add “return” as the topic name, so now this is the sender, and this is the return.
Producers and Consumers
In the graphic below, you can see some generalized examples of what falls into the category of producers versus consumers.
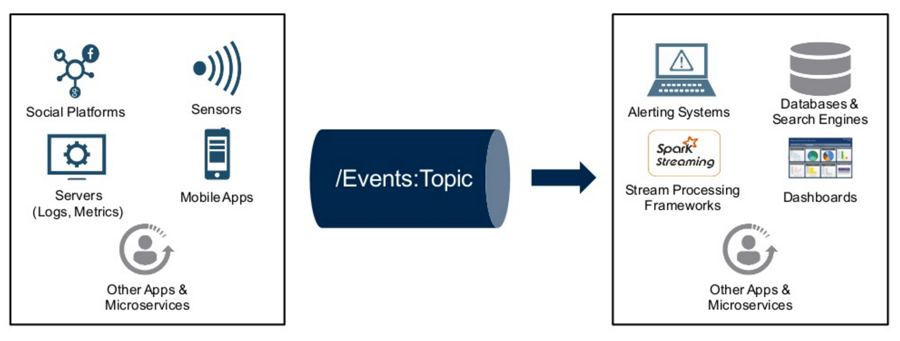
On the producer side, you have anything in your application stack that can be utilized to produce events. On the other side, you have consumers presenting information or leveraging the data coming through an event stream in a pipeline.
Considering a Messaging Platform
Just seven years ago, when I worked with Apache qpid, we were getting 50,000-100,000 messages per second throughput on that standard message queue, which we thought was amazing.
The problem with it, however, is that you can’t easily build a full message-driven architecture on an old-style message queue. It does not have the same capabilities that a publish/subscribe model does. For that reason, the scaling factor is the big benefit you pick up in a pub/sub model. For instance, let’s consider a micro-services model: if you’ve got 10 services, and you’re using a standard issue message queue, and you’re seeing 50-100k messages per second on a server, you can see that you’re going to have to scale out your messaging platform very rapidly to be able to keep up with every one of those services you put out there. With the pub/sub model, you have the ability to start looking at how fast it really is – and the Kafka model is blazing fast. These are benchmarks we’ve had on MapR Streams:
- Kafka 0.9 API with message sizes at 200 bytes
- MapR Streams on a 5 node cluster sustained 18 million events/sec
- Throughput of 3.5GB/s and over 1.5 trillion events/day
We have had these benchmarks validated independently. Of course, you will not reach those rates, because in order for you to do so, you would need a throughput of 3.5 gigabytes per second. That’s full saturation of three bonded 10Gb Ethernet links. Most people don’t set up their networking in that way. As you expand your networking capabilities, if you’ve got 100 gigabit can you reach this? Absolutely. I guarantee you’ll reach these types of numbers, very easily. The platform, MapR Streams, is not going to be a bottleneck for you as a scaling point. That’s the benefit. You don’t have to worry about those 50-100k messages per second holding you down. You will no longer have to worry about a developer wanting to connect to your production messaging and bringing everything down, because you can’t handle having 300,000 messages coming through per second and having someone test a model that he built on it.
Old-time message queues required manual sharding, defining where the routes go, which was a painful process. If you do manual sharding and have to come up with an algorithm to do it, you run into problems when you change your sharding at some point, and suddenly you have hotspots where messages are flowing through. It’s a nightmare.
Use Cases in Finance
When you start looking at the different opportunities for event-based, data-driven applications, there are a lot of areas that you can cover, such as real-time enablement for fraud protection and advertising through your network or financial customers.
Fraudulent Email
The Internet is a happy cloud, where nothing bad ever happens, which is why we don’t need fraud and risk departments within banks. Oh, sorry, I’ve got that exactly backwards. In actuality, we have fraudulent activity happening all over the board. We’ve got an angry cloud that wants to rain down and throw lightning bolts at everybody and pick us all off, and of course, that does not make consumers happy. We must deal with this reality.
There are multiple types of fraudulent email, including malware, spam, and phishing attempts. Let’s consider an example: you might work at a finance company that wants to keep track of all the emails coming in and classify phishing attempts that they see based on their bank. Some of the preventative options that we have would be to train people and tell them, “Don’t ever click random links that come to you in email.” But we all know that that doesn’t work. Email appliances, like Barracuda, that prevent users from seeing emails work decently, but they typically require users to intervene, are not easily customizable, and are very expensive.
So let’s look at a specific use case for constructing an email management pipeline, which could apply to any company, not just financial, although it really fits well in financial.
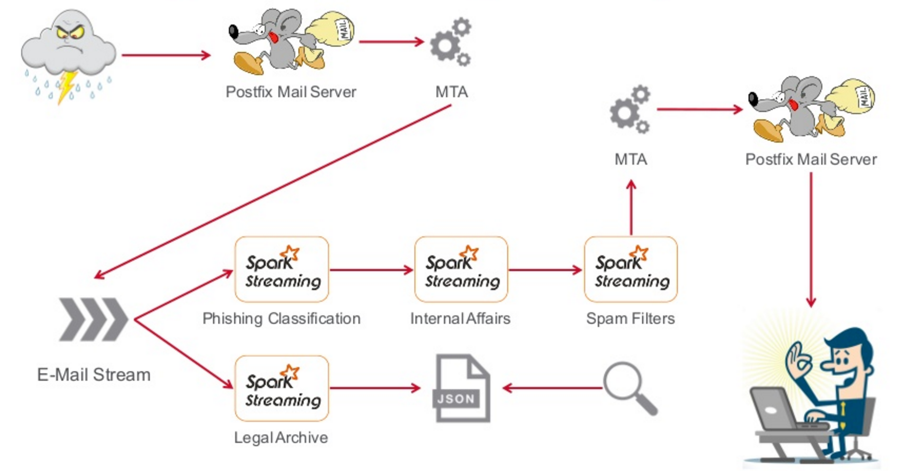
First, I could deploy a Postfix mail server, open source, and have all my email coming into there. From that point, I could create my mail transport agent and pick up all the email off my inbound mail server. My users never see this edge mail server. From there, I take every email, and I place it on a stream. Now, because it’s on a stream, I have full scalability, full flexibility to implement anything I want.
What does every legal team in every bank and every finance house do? These industries maintain all of their emails for some period of time for regulatory purposes. So I have a legal archive of all the email, although the user has never seen it yet. It can be stored in a JSON document database, which makes it well structured, easy to persist to and search, and now when we have legal inquiries, we have access to it, and can put litigation holds on those inquiries by altering the document.
On the flip side, I also process from that same email stream, and let’s say I want to do my own classification. I put into place all of the things I want to do before the email consumer ever sees the email: phishing classification, internal affairs for people leaking information, and spam filters. From there, I have another mail transport agent, and I put it back on to another Postfix (or other) mail server.
If you can imagine this pipeline being as complex or as simple as you want to meet your use case, it’s extremely powerful. You can put together your own phishing classification. And you can notify your partners or customers and let them know that you can classify, track, and list risk of all fraudulent emails coming into your company.
Now let’s consider a second use case with the user sending email out. Imagine your own internal mail server for your outbound mail, which you run through the same types of pipelines. Maybe you want to make sure that no one in your company is leaking proprietary, confidential information. Maybe you’re trying to assess risk in different areas of your organization for what is going out of the company. This internal affair type of model would make it so easy to implement, and the users never have to know about it. It’s easily scalable, and it’s all message driven, which solves any problems that you have in email.
To review, these are the biggest benefits of this approach:
- Customizable pipeline
- Can learn and apply new policies
- Spam
- Phishing classification
- Fraud attempts
- Retention policies
- Auditable
- Simple search and discovery
- Litigation hold
Fraudulent Web Traffic
Not all web traffic is bad, but most of it is – people doing things they shouldn’t be doing on the Internet. What can I do to flag fraudulent web traffic?
First, I want to take the click stream, regardless of what it is, and bring it through an activity stream. I want to be able to scale it out, and I want to be able to perform different types of analytics on it, which I will call my classifiers. These analytics will allow me to create a model that classifies certain types of known activity, that I have targeted in the past, as fraudulent. I want to create a blacklist, but I also want to create a whitelist, which will enable me to identify activities that every normal user does, but robots don’t do. In addition, I want to classify: what is my deviation from normal? Imagine building your user profiles in this model, and as a user’s click stream comes through, you can compare that activity to what their normal activity is. In addition, you can create your own segment populations for types of people or types of accounts. You can then determine what is normal activity for people with this type of an account by comparing them against themselves as well as the population.
The output of this classification is that we now want to alter the user’s session – whether we’re making recommendations for the good guy or crippling the functionality of the bad guy – by doing analytics and classification on the click stream. On this session alteration stream, I also want to have the ability to notify security, so I can open an inquiry or do in-depth analytics to track the source of these threats.
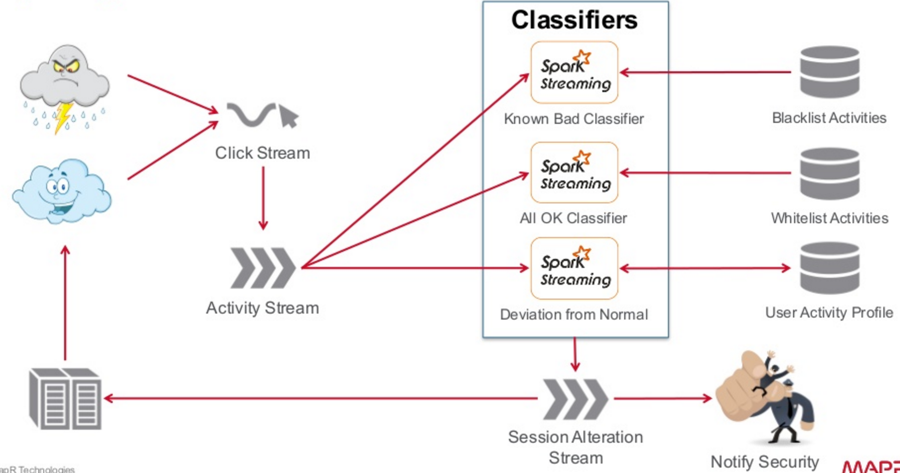
This diagram could be way more complicated, depending on how you’re deploying your models. But the core capability, in an event-driven model, is that it becomes very easy to scale these components, and as you pick up new classification models and new recommendation engines, it also becomes very easy to plug them into the click stream and chain them together inside your classification engine. You’re putting your own rules together, so you have a lot of flexibility.
Similiarities Between Marketing and Fraud
I recently noticed some important similarities between marketing and fraud. Customer 360 and marketing fraud are remarkably similar. First, you build a user profile in both of these cases. The primary difference how to use the profile: maybe you want to make a recommendation to them, maybe you’re looking at normal usage patterns, but you end up taking this history and using it. Second, in both cases, you build segmented profiles. You want to create segmented populations in marketing, so you know how to target audiences. You do the same thing on the fraud side, because you want to figure out what is normal for this type of an account. Third, on both sides, you dynamically alter your website. It’s the most common thing done on the Internet today, using cookie tracking and click stream analytics (and, in some cases, phishing attempts) to keep people on your website longer and reduce the bounce rate by giving them content that keeps them there. The last similarity is that both of them kick off external workflows. On the marketing side, these could be nurture emails; on the other side, it would be kicking off a security workflow. These two things are the core foundation for Customer 360 and fraud detection.
These similarities are important if you are trying to figure out how to explain to people what these capabilities do. It becomes very simple to say, “If we’ve done one of these, we can do the other one,” especially from the finance perspective, because it is the same user profile. The different sides have a lot of overlap, which becomes evident when the marketing and fraud teams have an opportunity to interact. In one case that started with website fraud, a customer in the marketing team said, “We’ve been trying to get this information forever. We actually have it stored in our system?” The fraud team opened up that data to the marketing team, and then they had it.
In conclusion, when you think about implementing next-generation tools and technologies, keep in mind that not all data platforms are the same. If you’d like to learn more about MapR’s converged application blueprint, visit this link.
| Reference: | Handling the Extremes: Scaling and Streaming in Finance from our JCG partner Jim Scott at the Mapr blog. |
