There has been a lot of research in document image processing over the past 20 years, but not much research has been done in terms of parallel processing. Some of the solutions proposed for parallel processing have been to create threads of execution for each image, or to use GNU Parallel.
In this blog post, you will learn how to use a big data platform to process images in parallel. This solution was implemented for one of our healthcare customers, medical images are scanned and made searchable for data exploration. To extract text from the images, optical character recognition (OCR) software called Tesseract is used. Extracted text from image documents is stored on the MapR Platform for fast retrieval. This use case uses the TIFF image format, which can be extended and applied to other types of images.
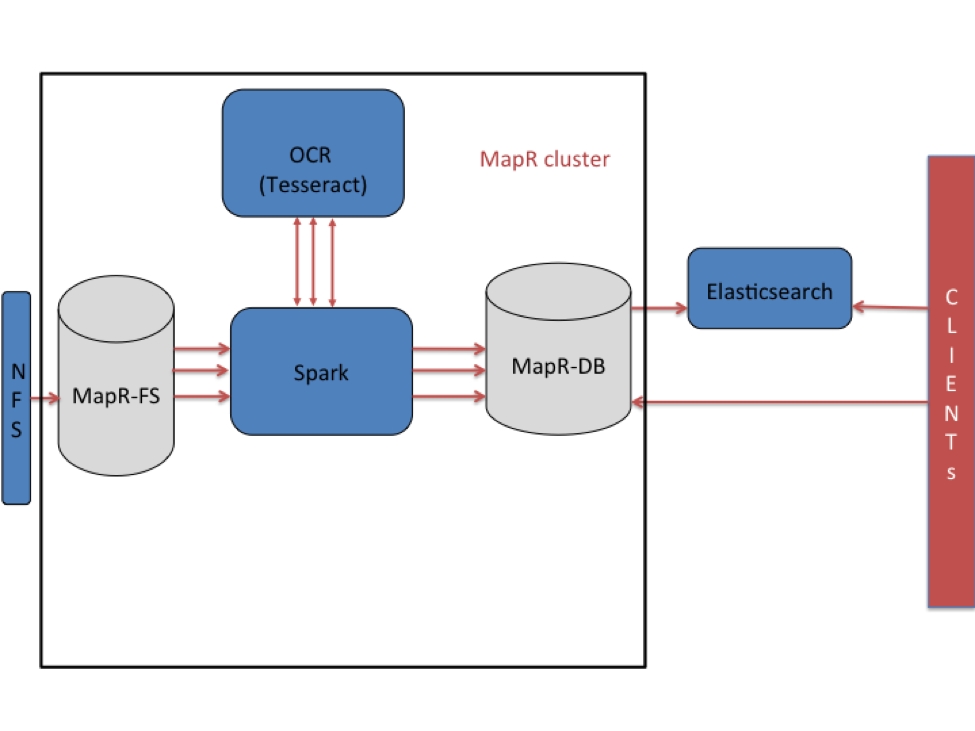
High-Level Architecture
In this use case, images are stored in the MapR File System (MapR-FS) and processed using Apache Spark and OCR software. Files are ingested through an NFS mount into MapR-FS. Once the files are ingested into MapR-FS, they can be read and processed serially. To parallelize the processing, the Spark framework is used. Embedded text is extracted using Tesseract, and the extracted text is populated into MapR-DB. Tesseract is an open source OCR engine, which was originally developed at HP Labs, and later released as open source software and sponsored by Google. Based on my research, Tesseract is the most accurate open source library available for OCR.
With the 5.0 release of MapR, external search indexes on columns, column families, or entire tables in MapR-DB can be created in Elasticsearch. The tables in MapR-DB are enabled with the Elasticsearch replication, so as the data is inserted in the tables, and it is indexed in Elasticsearch. That is, the extracted text and the metadata stored in MapR-DB tables will be automatically replicated and indexed in Elasticsearch. Since the wide column data model of MapR-DB natively supports multiple versions of data, there can be multiple versions of a document stored in MapR-DB. The latest version in the MapR-DB table is indexed in Elasticsearch.
Tesseract Installation
On a Linux machine, login as “root” and follow the instructions below:
# yum install tesseract
# yum install leptonica
MapR-DB Table Schema Description
The schema for the table is simple. The rowkey consists of the document id, which is the filename without the suffix. There is one column family “cf” with two columns, “info” and “data.” The first is for storing the metadata and the other is for the extracted text. The file path will be stored in the “info” column. Clients will be able to search using the text and metadata in the Elasticsearch indexes. Once the record is located, the entire document can retrieved using the file path of the original document.
MapR-DB Table Creation
Tables can be created programmatically using the Java API or the HBase shell. Here are the instructions using the shell:
$ hbase shell hbase(main):001:0> create '/user/user01/datatable', 'cf'
where “/user/user01/datatable” is the path to the data table and “cf” is the column family with the default number of versions.
Follow the quick tutorial for enabling Elasticsearch Replication
Install Elasticsearch by downloading it from elastic.co.
$ /opt/mapr/bin/register-elasticsearch -r localhost -e /opt/mapr/QSS/miner/elasticsearch-2.2.0 -u mapr -y -c maprdemoes $ /opt/mapr/bin/register-elasticsearch -l $ maprcli table replica elasticsearch autosetup -path /srctable -target maprdemoes -index sourcedoc -type json
The open source Tesseract uses the Leptonica image-processing library. To read the images, process and store the documents, download the source code, build it and run the program. The Spark code in Java reads the binary files as shown below.
Reading Image Files
To read the images, binaryFiles() API is invoked on JavaStreamingContext. This API reads only binary image files; once read, each file is processed in processFile() method.
JavaPairRDD<String, PortableDataStream> readRDD = jsc.binaryFiles(inputPath);
readRDD.map(new Function<Tuple2<String, PortableDataStream>, String>() {
@Override
public String call(Tuple2<String, PortableDataStream> pair) {
String fileName = StringUtils.remove(pair._2.getPath(), "maprfs://");
processFile(StringUtils.remove(fileName, "file:"));
return null;
}
}).collect();In the “processFile” method, the Tesseract API is invoked to extract the text. Here the documents are in English, so the API is set to “eng”.
public static String processImageFile(String fileName) {
Tesseract instance = new Tesseract();
File imageFile = new File(fileName);
String resultText = null;
instance.setLanguage("eng");
try {
resultText = instance.doOCR(imageFile);
} catch (Exception e) {
e.printStackTrace();
} finally {
return resultText;
}
}After the text is extracted, it is stored in MapR-DB by calling the method populateDataInMapRDB(). Here the data is stored in the column family “cf” and column “data.” Meta data of the file (filename) is stored in the “info” column. If there is more data that needs to be indexed, it can be populated under a different column qualifier.
populateDataInMapRDB(config, convertedTable, rowKey, cf, "data", resultText); populateDataInMapRDB(config, convertedTable, rowKey, cf, "info", fileName);
Run the Application
- Download the code and sample data from here:
git clone https://github.com/ranjitreddy2013/imageprocessing
- Build the application using maven:
mvn clean install
- Copy the sample image file located in the sample directory to the directory where the Spark program is reading. See inputPath set in binaryFiles() api in the program.
- To invoke the Spark program:
${SPARK_HOME}/bin/spark-submit --class com.mapr.ocr.text.ImageToText --conf "spark.driver.extraJavaOptions=-Dlog4j.configuration=log4j-spark.properties" --master local[4]document-store-0.0.1-SNAPSHOT-jar-with-dependencies.jarAfter the program completes execution, data should should be replicated and indexed in Elasticsearch.
Accessing the Indexed Text from Elasticsearch:
Run the following query to extract the documents in Elasticsearch:
curl -XGET "http://maprdemo:9200/medicaldoc/json/_search" -d'
{
"query": {
"match": {
"cf.info": "quick"
}},
"fields" : ["_id", "cf.filepath", "cf.info"]
}' | python -m json.toolConclusion
In this blog, you have learned how OCR software can be used to scan image documents using Spark. You’ve also learned how the extracted text is stored in MapR-DB. With Elasticsearch replication enabled on the MapR-DB tables, data indexing is automatic when the data is loaded into the table. This makes searchability of the extracted text very easy to manage. It simplifies the processing pipeline, which is important for environments that have continually growing volumes of images to process.
| Reference: | Processing Image Documents on MapR at Scale from our JCG partner Ranjit Lingaiah at the Mapr blog. |
