Monitoring Real-Time Uber Data Using Spark Machine Learning, Streaming, and the Kafka API (Part 2)
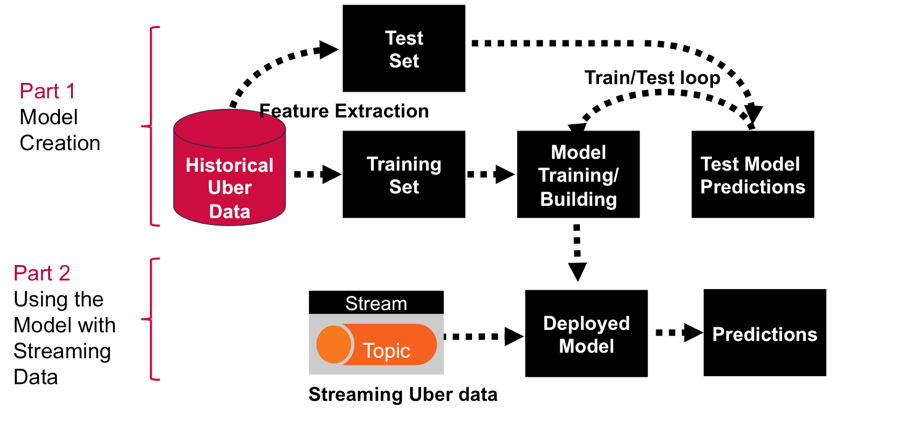
This post is the second part in a series where we will build a real-time example for analysis and monitoring of Uber car GPS trip data. If you have not already read the first part of this series, you should read that first.
The first post discussed creating a machine learning model using Apache Spark’s K-means algorithm to cluster Uber data based on location. This second post will discuss using the saved K-means model with streaming data to do real-time analysis of where and when Uber cars are clustered.
Example Use Case: Real-Time Analysis of Geographically Clustered Vehicles/Items
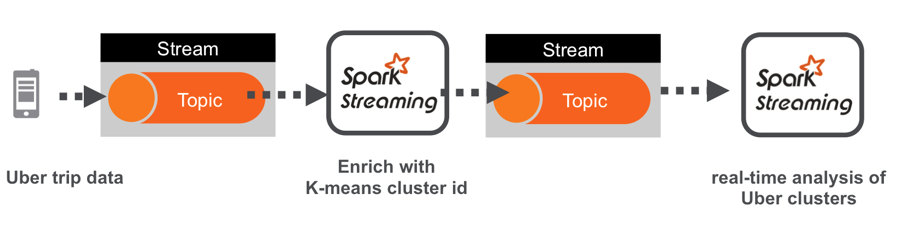
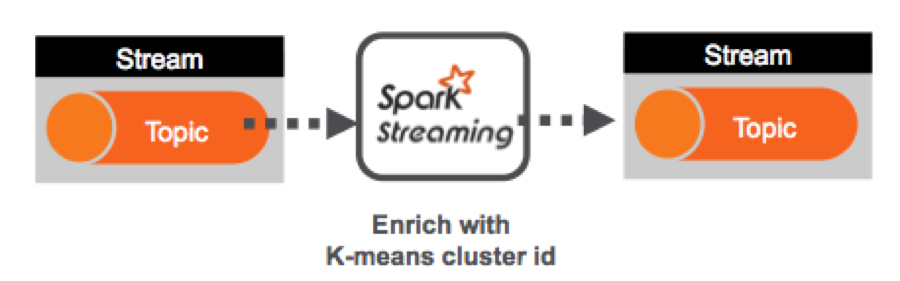
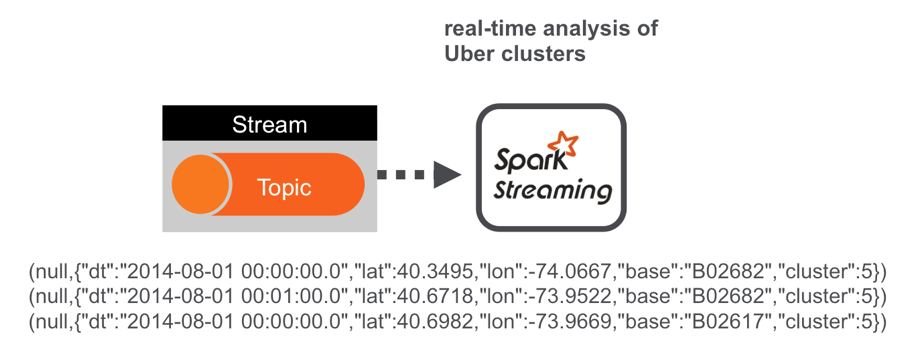
Uber trip data is published to a MapR Streams topic using the Kafka API. A Spark streaming application, subscribed to the topic, enriches the data with the cluster Id corresponding to the location using a k-means model, and publishes the results in JSON format to another topic. A Spark streaming application subscribed to the second topic analyzes the JSON messages in real time.
Example Use Case Data
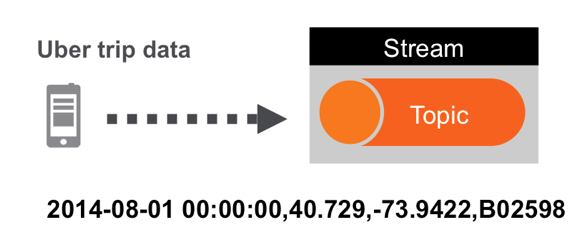
The example data set is Uber trip data, which you can read more about in part 1 of this series. The incoming Data Records are in CSV format.
An example line is shown below:
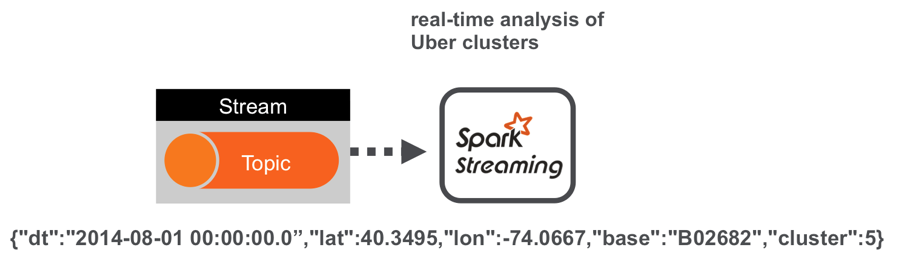
The enriched Data Records are in JSON format. An example line is shown below:
Spark Kafka Consumer Producer Code
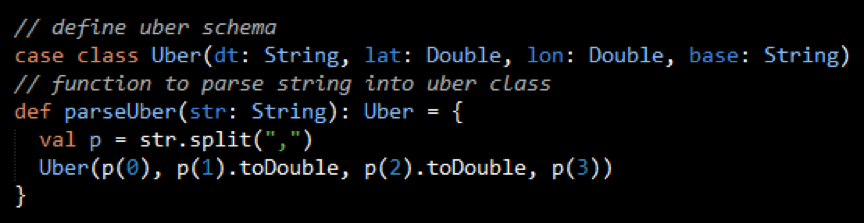
Parsing the Data Set Records
A Scala Uber case class defines the schema corresponding to the CSV records. The parseUber function parses the comma separated values into the Uber case class.
Loading the K-Means Model
The Spark KMeansModel class is used to load the saved K-means model fitted on the historical Uber trip data.

Output of model clusterCenters:

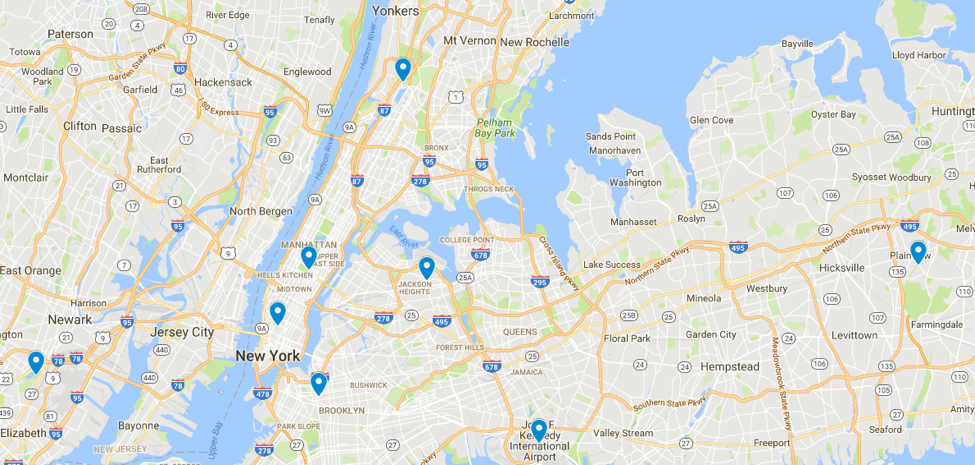
Below the cluster centers are displayed on a google map:
Spark Streaming Code
These are the basic steps for the Spark Streaming Consumer Producer code:
- Configure Kafka Consumer Producer properties.
- Initialize a Spark StreamingContext object. Using this context, create a DStream which reads message from a Topic.
- Apply transformations (which create new DStreams).
- Write messages from the transformed DStream to a Topic.
- Start receiving data and processing. Wait for the processing to be stopped.
We will go through each of these steps with the example application code.
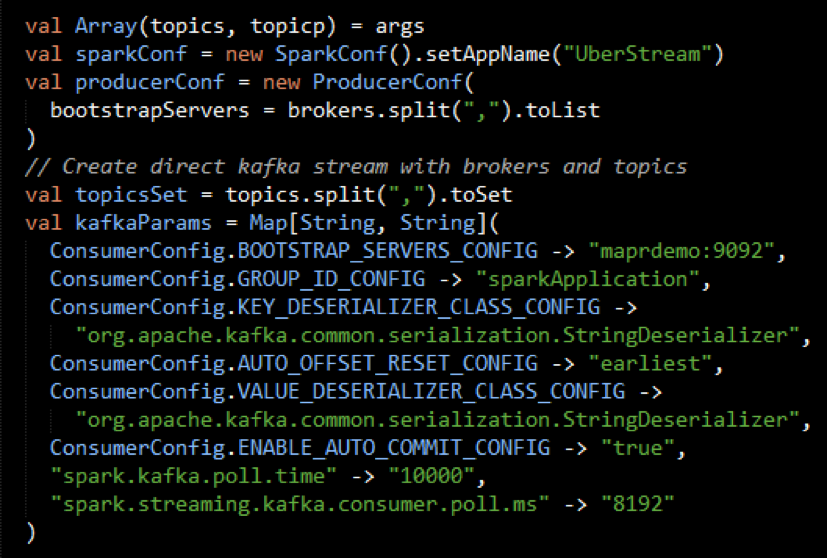
- Configure Kafka Consumer Producer properties
The first step is to set the KafkaConsumer and KafkaProducer configuration properties, which will be used later to create a DStream for receiving/sending messages to topics. You need to set the following paramters:
- Key and value deserializers: for deserializing the message.
- Auto offset reset: to start reading from the earliest or latest message.
- Bootstrap servers: this can be set to a dummy host:port since the broker address is not actually used by MapR Streams.
For more information on the configuration parameters, see the MapR Streams documentation.
- Initialize a Spark StreamingContext object.
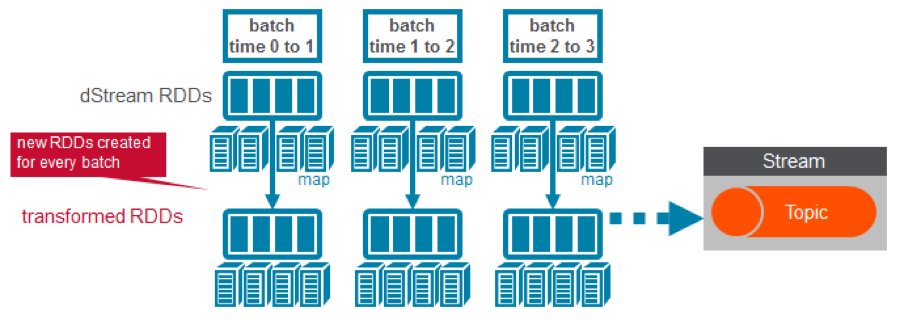
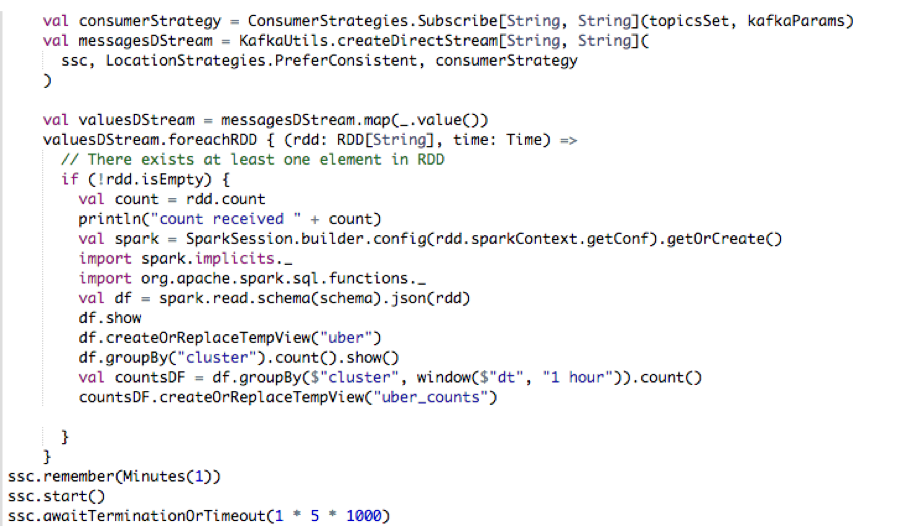
ConsumerStrategies.Subscribe, as shown below, is used to set the topics and Kafka configuration parameters. We use the KafkaUtils createDirectStream method with a StreamingContext, the consumer and location strategies, to create an input stream from a MapR Streams topic. This creates a DStream that represents the stream of incoming data, where each message is a key value pair. We use the DStream map transformation to create a DStream with the message values.
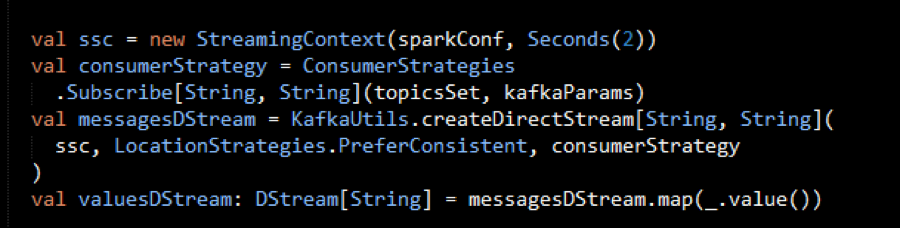

- Apply transformations (which create new DStreams)
We use the DStream foreachRDD method to apply processing to each RDD in this DStream. We parse the message values into Uber objects, with the map operation on the DStream. Then we convert the RDD to a DataFrame, which allows you to use DataFrames and SQL operations on streaming data.
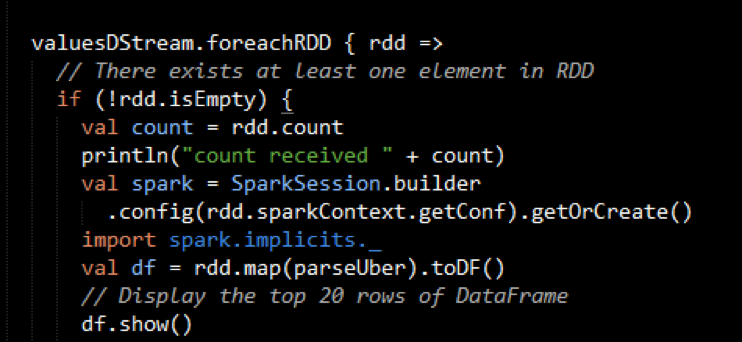
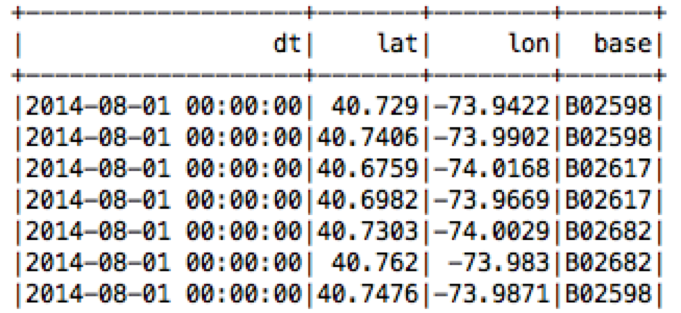
Here is example output from the df.show:
A VectorAssembler is used to transform and return a new DataFrame with the latitude and longitude feature columns in a vector column.

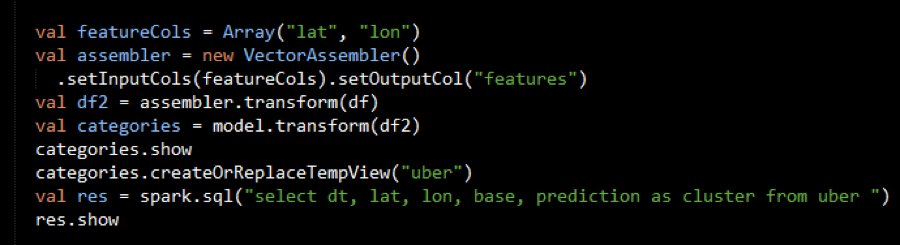
Then the model is used to get the clusters from the features with the model transform method, which returns a DataFrame with the cluster predictions.
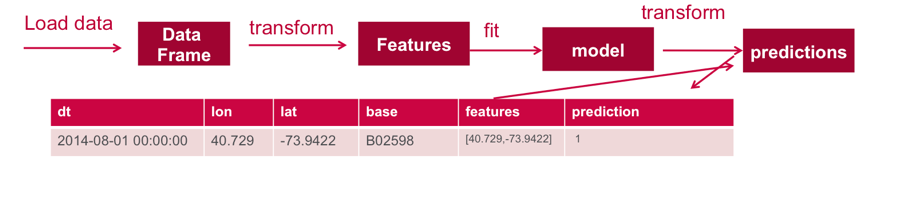
The output of categories.show is below:

The DataFrame is then registered as a table so that it can be used in SQL statements. The output of the SQL query is shown below:

- Write messages from the transformed DStream to a Topic

The Dataset result of the query is converted to JSON RDD Strings, then the RDD sendToKafka method is used to send the JSON key-value messages to a topic (the key is null in this case).
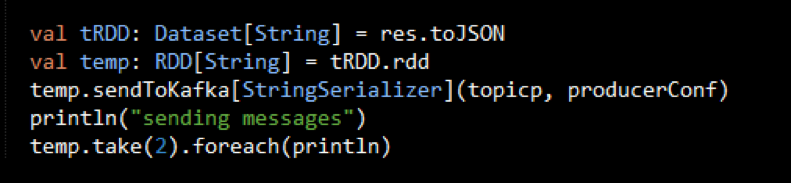
Example message values (the output for temp.take(2) ) are shown below:
{“dt”:”2014-08-01 00:00:00″,”lat”:40.729,”lon”:-73.9422,”base”:”B02598″,”cluster”:7}
{“dt”:”2014-08-01 00:00:00″,”lat”:40.7406,”lon”:-73.9902,”base”:”B02598″,”cluster”:7}
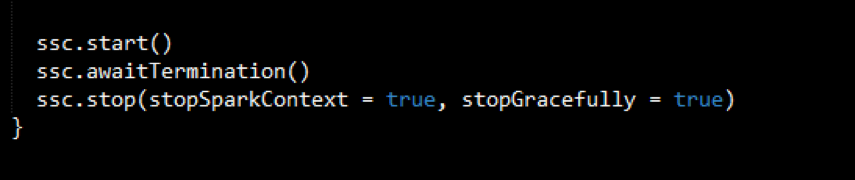
- Start receiving data and processing it. Wait for the processing to be stopped.
To start receiving data, we must explicitly call start() on the StreamingContext, then call awaitTermination to wait for the streaming computation to finish.
Spark Kafka Consumer Code
Next, we will go over some of the Spark streaming code which consumes the JSON-enriched messages.
We specify the schema with a Spark Structype:

Below is the code for:
- Creating a Direct Kafka Stream
- Converting the JSON message values to Dataset[Row] using spark.read.json with the schema
- Creating two temporary views for subsequent SQL queries
- Using ssc.remember to cache data for queries
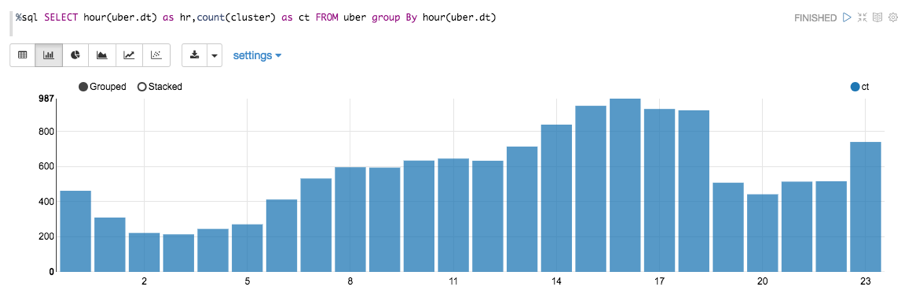
Now we can query the streaming data to ask questions like: which hours had the highest number of pickups? (Output is shown in a Zeppelin notebook):
spark.sql(“SELECT hour(uber.dt) as hr,count(cluster) as ct FROM uber group By hour(uber.dt)”)
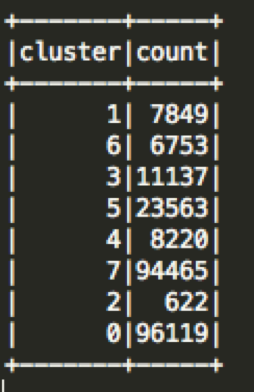
How many pickups occurred in each cluster?
df.groupBy(“cluster”).count().show()
or
spark.sql(“select cluster, count(cluster) as count from uber group by cluster”)
Which hours of the day and which cluster had the highest number of pickups?
spark.sql(“SELECT hour(uber.dt) as hr,count(cluster) as ct FROM uber group By hour(uber.dt)”)
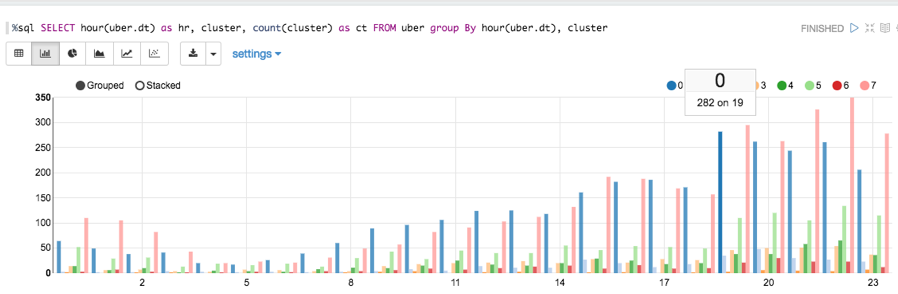
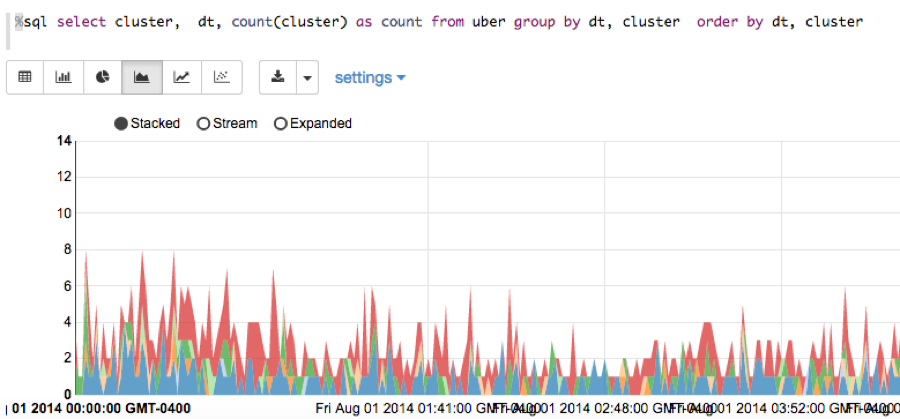
Display datetime and cluster counts for Uber trips:
%sql select cluster, dt, count(cluster) as count from uber group by dt, cluster order by dt, cluster
Software
- You can download the complete code, data, and instructions to run this example from here.
- This example runs on MapR 5.2 with Spark 2.0.1. If you are running on the MapR v5.2 Sandbox, you need to upgrade Spark to 2.0.1 (MEP 2.0). For more information on upgrading, see: here and here.
Summary
In this blog post, you learned how to use a Spark machine learning model in a Spark Streaming application, and how to integrate Spark Streaming with MapR Streams to consume and produce messages using the Kafka API.
References and More Information:
- Integrate Spark with MapR Streams Documentation
- Free Online training on MapR Streams, Spark at learn.mapr.com
- Apache Spark Streaming Programming Guide
- Real-Time Streaming Data Pipelines with Apache APIs: Kafka, Spark Streaming, and HBase
- Apache Kafka and MapR Streams: Terms, Techniques and New Designs
| Reference: | Monitoring Real-Time Uber Data Using Spark Machine Learning, Streaming, and the Kafka API (Part 2) from our JCG partner Carol McDonald at the Mapr blog. |
