For a bit of Christmas holiday fun I thought it’d be cool to create a graph of the different blips on the ThoughtWorks Technology Radar and how the recommendations have changed over time.
I wrote a script to extract each blip (e.g. .NET Core) and the recommendation made in each radar that it appeared in. I ended up with a CSV file:
|----------------------------------------------+----------+-------------| | technology | date | suggestion | |----------------------------------------------+----------+-------------| | AppHarbor | Mar 2012 | Trial | | Accumulate-only data | Nov 2015 | Assess | | Accumulate-only data | May 2015 | Assess | | Accumulate-only data | Jan 2015 | Assess | | Buying solutions you can only afford one of | Mar 2012 | Hold | |----------------------------------------------+----------+-------------|
I then wrote a Cypher script to create the following graph model:
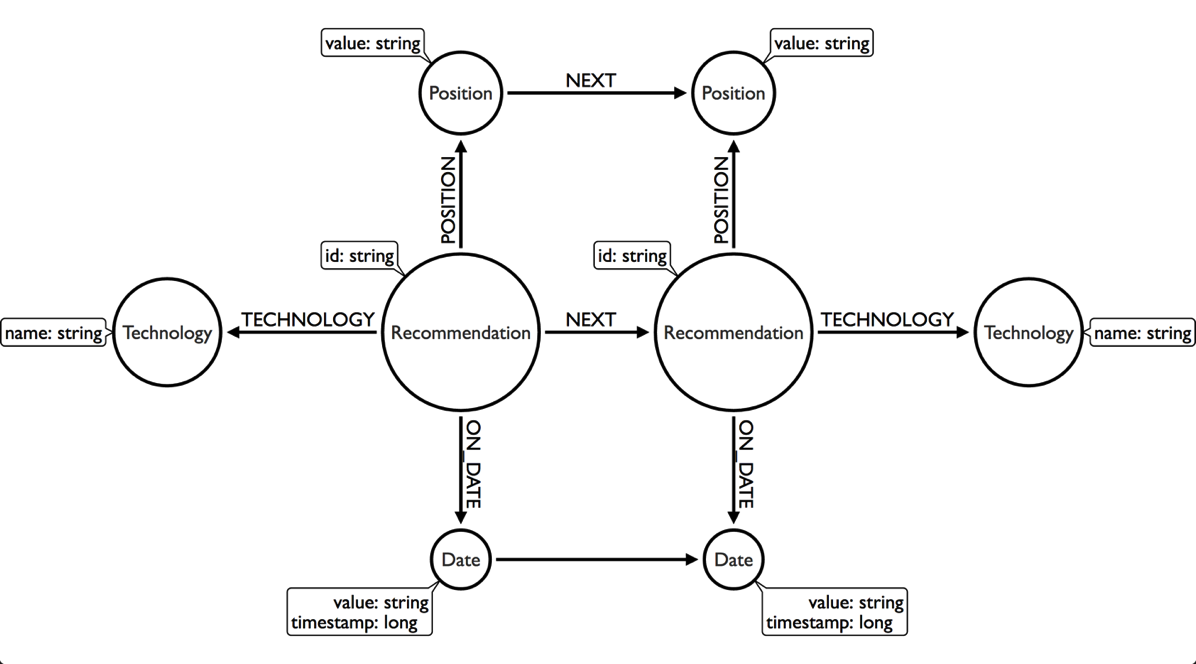
WITH ["Hold", "Assess", "Trial", "Adopt"] AS positions
UNWIND RANGE (0, size(positions) - 2) AS index
WITH positions[index] AS pos1, positions[index + 1] AS pos2
MERGE (position1:Position {value: pos1})
MERGE (position2:Position {value: pos2})
MERGE (position1)-[:NEXT]->(position2);
load csv with headers from "file:///blips.csv" AS row
MATCH (position:Position {value: row.suggestion })
MERGE (tech:Technology {name: row.technology })
MERGE (date:Date {value: row.date})
MERGE (recommendation:Recommendation {
id: tech.name + "_" + date.value + "_" + position.value})
MERGE (recommendation)-[:ON_DATE]->(date)
MERGE (recommendation)-[:POSITION]->(position)
MERGE (recommendation)-[:TECHNOLOGY]->(tech);
match (date:Date)
SET date.timestamp = apoc.date.parse(date.value, "ms", "MMM yyyy");
MATCH (date:Date)
WITH date
ORDER BY date.timestamp
WITH COLLECT(date) AS dates
UNWIND range(0, size(dates)-2) AS index
WITH dates[index] as month1, dates[index+1] AS month2
MERGE (month1)-[:NEXT]->(month2);
MATCH (tech)<-[:TECHNOLOGY]-(reco:Recommendation)-[:ON_DATE]->(date)
WITH tech, reco, date
ORDER BY tech.name, date.timestamp
WITH tech, COLLECT(reco) AS recos
UNWIND range(0, size(recos)-2) AS index
WITH recos[index] AS reco1, recos[index+1] AS reco2
MERGE (reco1)-[:NEXT]->(reco2);Note that I installed the APOC procedures library so that I could convert the string representation of a date into a timestamp using the apoc.date.parse function. The blips.csv file needs to go in the import directory of Neo4j.
Now we’re reading to write some queries.
The Technology Radar has 4 positions that can be taken for a given technology: Hold, Assess, Trial, and Adopt:
- Hold: Process with Caution
- Assess: Worth exploring with the goal of understanding how it will affect your enterprise.
- Trial: Worth pursuing. It is important to understand how to build up this capability. Enterprises should try this technology on a project that can handle the risk.
- Adopt: We feel strongly that the industry should be adopting these items. We use them when appropriate on our projects.
I was curious whether there had ever been a technology where the advice was initially to ‘Hold’ but had later changed to ‘Assess’. I wrote the following query to find out:
MATCH (pos1:Position {value:"Hold"})<-[:POSITION]-(reco)-[:TECHNOLOGY]->(tech),
(pos2:Position {value:"Assess"})<-[:POSITION]-(otherReco)-[:TECHNOLOGY]->(tech),
(reco)-[:ON_DATE]->(recoDate),
(otherReco)-[:ON_DATE]->(otherRecoDate)
WHERE (reco)-[:NEXT]->(otherReco)
RETURN tech.name AS technology, otherRecoDate.value AS dateOfChange;
╒════════════╤══════════════╕
│"technology"│"dateOfChange"│
╞════════════╪══════════════╡
│"Azure" │"Aug 2010" │
└────────────┴──────────────┘Only Azure! The page doesn’t have any explanation for the initial ‘Hold’ advice in April 2010 which was presumably just before ‘the cloud’ became prominent. What about the other way around? Are there any technologies where the suggestion was initially to ‘Assess’ but later to ‘Hold’?
MATCH (pos1:Position {value:"Assess"})<-[:POSITION]-(reco)-[:TECHNOLOGY]->(tech),
(pos2:Position {value:"Hold"})<-[:POSITION]-(otherReco)-[:TECHNOLOGY]->(tech),
(reco)-[:ON_DATE]->(recoDate),
(otherReco)-[:ON_DATE]->(otherRecoDate)
WHERE (reco)-[:NEXT]->(otherReco)
RETURN tech.name AS technology, otherRecoDate.value AS dateOfChange;
╒═══════════════════════════════════╤══════════════╕
│"technology" │"dateOfChange"│
╞═══════════════════════════════════╪══════════════╡
│"RIA" │"Apr 2010" │
├───────────────────────────────────┼──────────────┤
│"Backbone.js" │"Oct 2012" │
├───────────────────────────────────┼──────────────┤
│"Pace-layered Application Strategy"│"Nov 2015" │
├───────────────────────────────────┼──────────────┤
│"SPDY" │"May 2015" │
├───────────────────────────────────┼──────────────┤
│"AngularJS" │"Nov 2016" │
└───────────────────────────────────┴──────────────┘A couple of these are Javascript libraries/frameworks so presumably the advice is now to use React instead. Let’s check:
MATCH (t:Technology)<-[:TECHNOLOGY]-(reco)-[:ON_DATE]->(date), (reco)-[:POSITION]->(pos) WHERE t.name contains "React.js" RETURN pos.value, date.value ORDER BY date.timestamp ╒═══════════╤════════════╕ │"pos.value"│"date.value"│ ╞═══════════╪════════════╡ │"Assess" │"Jan 2015" │ ├───────────┼────────────┤ │"Trial" │"May 2015" │ ├───────────┼────────────┤ │"Trial" │"Nov 2015" │ ├───────────┼────────────┤ │"Adopt" │"Apr 2016" │ ├───────────┼────────────┤ │"Adopt" │"Nov 2016" │ └───────────┴────────────┘
Ember is also popular:
MATCH (t:Technology)<-[:TECHNOLOGY]-(reco)-[:ON_DATE]->(date), (reco)-[:POSITION]->(pos) WHERE t.name contains "Ember" RETURN pos.value, date.value ORDER BY date.timestamp ╒═══════════╤════════════╕ │"pos.value"│"date.value"│ ╞═══════════╪════════════╡ │"Assess" │"May 2015" │ ├───────────┼────────────┤ │"Assess" │"Nov 2015" │ ├───────────┼────────────┤ │"Trial" │"Apr 2016" │ ├───────────┼────────────┤ │"Adopt" │"Nov 2016" │ └───────────┴────────────┘
Let’s go on a different tangent and look at how many technologies were introduced in the most recent radar?
MATCH (date:Date {value: "Nov 2016"})<-[:ON_DATE]-(reco)
WHERE NOT (reco)<-[:NEXT]-()
RETURN COUNT(*)
╒══════════╕
│"COUNT(*)"│
╞══════════╡
│"45" │
└──────────┘Wow, 45 new things! How were they spread across the different positions?
MATCH (date:Date {value: "Nov 2016"})<-[:ON_DATE]-(reco)-[:TECHNOLOGY]->(tech),
(reco)-[:POSITION]->(position)
WHERE NOT (reco)<-[:NEXT]-()
WITH position, COUNT(*) AS count, COLLECT(tech.name) AS technologies
ORDER BY LENGTH((position)-[:NEXT*]->()) DESC
RETURN position.value, count, technologies
╒════════════════╤═══════╤══════════════════════════════════════════════╕
│"position.value"│"count"│"technologies" │
╞════════════════╪═══════╪══════════════════════════════════════════════╡
│"Hold" │"1" │["Anemic REST"] │
├────────────────┼───────┼──────────────────────────────────────────────┤
│"Assess" │"28" │["Nuance Mix","Micro frontends","Three.js","Sc│
│ │ │ikit-learn","WebRTC","ReSwift","Vue.js","Elect│
│ │ │ron","Container security scanning","wit.ai","D│
│ │ │ifferential privacy","Rapidoid","OpenVR","AWS │
│ │ │Application Load Balancer","Tarantool","IndiaS│
│ │ │tack","Ethereum","axios","Bottled Water","Cass│
│ │ │andra carefully","ECMAScript 2017","FBSnapshot│
│ │ │Testcase","Client-directed query","JuMP","Cloj│
│ │ │ure.spec","HoloLens","Android-x86","Physical W│
│ │ │eb"] │
├────────────────┼───────┼──────────────────────────────────────────────┤
│"Trial" │"13" │["tmate","Lightweight Architecture Decision Re│
│ │ │cords","APIs as a product","JSONassert","Unity│
│ │ │ beyond gaming","Galen","Enzyme","Quick and Ni│
│ │ │mble","Talisman","fastlane","Auth0","Pa11y","P│
│ │ │hoenix"] │
├────────────────┼───────┼──────────────────────────────────────────────┤
│"Adopt" │"3" │["Grafana","Babel","Pipelines as code"] │
└────────────────┴───────┴──────────────────────────────────────────────┘Lots of new things to explore over the holidays! The CSV files, import script, and queries used in this post are all available on github if you want to play around with them.
| Reference: | Neo4j: Graphing the ThoughtWorks Technology Radar from our JCG partner Mark Needham at the Mark Needham Blog blog. |
