Kafka Connect and Kafka REST API on MapR: Streaming Just Became a Whole Lot Easier!
In my previous blogpost, I explained the three major components of a streaming architecture. Most streaming architectures have three major components – producers, a streaming system, and consumers. Producers (such as Apache Flume) publish event data into a streaming system after collecting it from the data source, transforming it into the desired format, and optionally filtering, aggregating, and enriching it. The streaming or messaging system (such as Apache Kafka or MapR Streams) takes the data published by the producers, persists it, and reliably delivers it to consumers. Consumers are typically stream processing engines (such as Apache Spark) that subscribe to data from streams and manipulate or analyze that data to look for alerts and insights. Furthermore, once the data is processed, it may need to be persisted in a database or a file for future use by downstream applications.
The following diagram illustrates the typical streaming architecture:
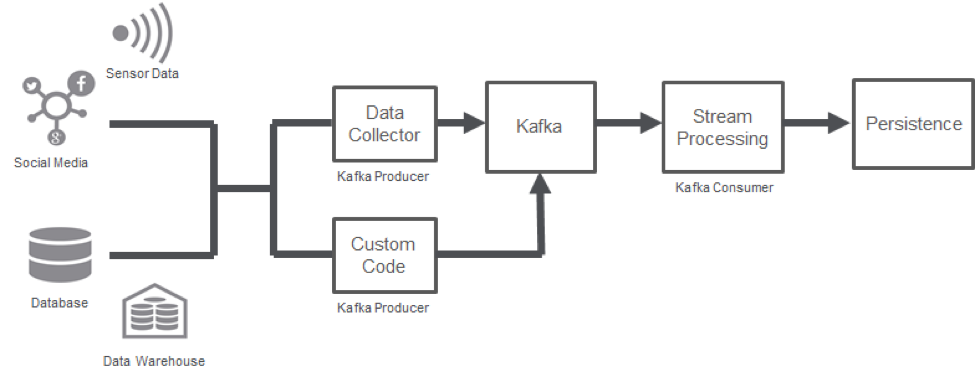
However, as streaming becomes more pervasive, we are looking to simplify this architecture and, at the same time, make it more agile. Enter Kafka Connect and the Kafka REST API. The following diagram illustrates a new, simple, agile way of setting up your streaming:
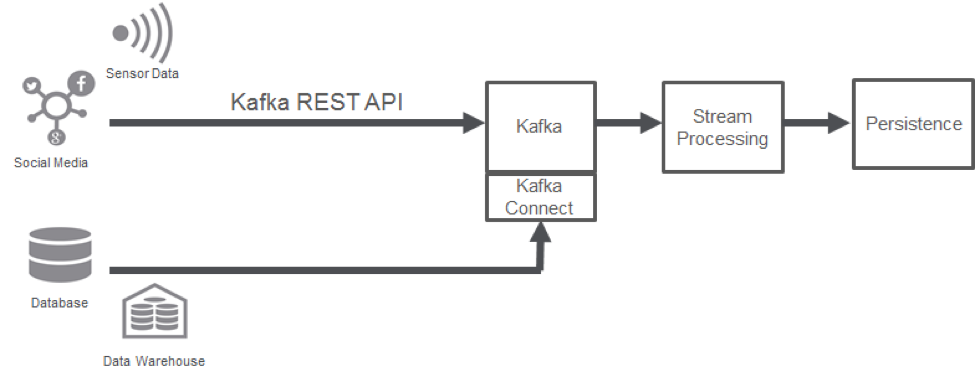
Kafka Connect: Easily connect common data systems with Kafka
Kafka Connect provides pre-built connectors that allow legacy data stores (such as databases and data warehouses) and modern data stores (such as HDFS) to connect with Kafka. This connection eliminates the need of building a custom “producer” or “consumer” application to help these data systems to publish/subscribe to Kafka. It also eliminates the need for a third party data collector that provides connectors to these data stores.
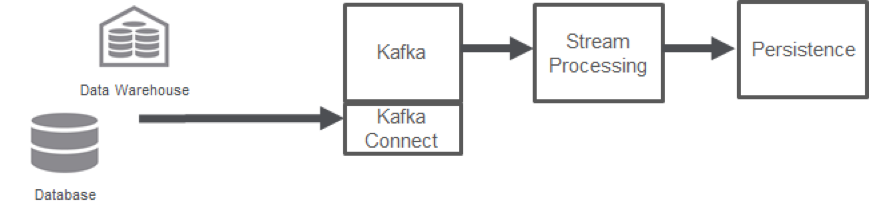
Kafka Connect provides a convenient, reliable connection to the most common data stores. It helps to ingest data into Kafka as well as push data from Kafka into the most commonly used data systems. Moreover, to eliminate the need of custom producer apps, it allows pull-based ingestion of data, supporting sources that don’t know how to push. Similarly, to eliminate custom consumer apps, it allows push-based export of data from Kafka, supporting data systems that don’t know how to pull data from Kafka. As Kafka Connect continues to mature, more connectors will be created, opening up a large range of sources and sinks that can connect to Kafka out of the box.
Kafka REST Proxy: Connect with Kafka using HTTP
New age data sources such as sensors, mobile devices, etc., know how to communicate using HTTP. However, they often do not have enough computing resources to run a Kafka producer application and a Kafka client. This deficiency is why the Kafka REST API is a game changer. It allows these devices to publish/subscribe to Kafka topics easily, which makes the architecture much more agile. Any device that can communicate using HTTP can now communicate directly with Kafka. This development has massive implications in simplifying IoT architectures. Any car, thermostat, machine sensor, etc., can now communicate directly with Kafka.
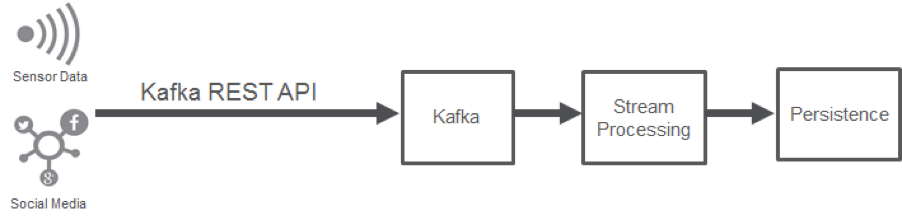
The Kafka REST API eliminates intermediate data collectors and simplifies the architecture by directly connecting the data sources with Kafka. Any programming language in any runtime environment can now connect with Kafka using HTTP. This ability gives developers the freedom to use the development framework of their choice and connect with Kafka using simple REST APIs, which reduces the time-to-market for streaming applications.
MapR Converged Data Platform: Further simplifying the architecture
The MapR Platform further simplifies the streaming architecture by providing event streaming, stream processing, and persistence (both database and files) on one single platform, in one system, in one cluster. You can connect the data sources with MapR Streams – which is a more secure, reliale, and performant replacement for Kafka – using the Kafka REST API or Kafka Connect. All the components of your streaming architecture will be available on MapR, within one platform.
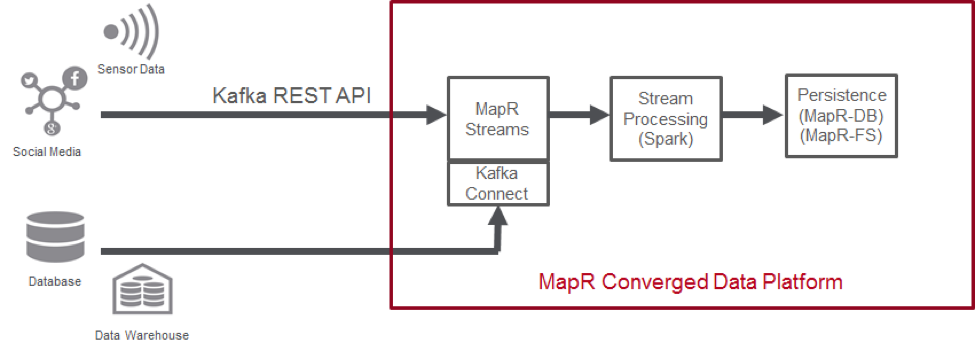
MapR Streams uses the same APIs as Kafka (0.9), which means that applications built with Kafka as the messaging system can be easily ported over to MapR Streams and vice versa. Without the converged platform, event streaming, stream processing, and persistence would run as separate systems that would need to be connected. Connected systems require cross-cluster data movement, which introduces additional latency. They also require more hardware, since resources cannot be shared across siloed systems and have higher administration cost. The MapR Converged Data Platform eliminates these problems by providing one single system for all components (except the original data sources) of the streaming architecture.
To understand the inner workings of MapR Streams, you should watch this whiteboard walkthrough. Read this blog to understand the advantages of using MapR Streams over Kafka. If you would like to try MapR Streams, take a look at this getting started tutorial.
| Reference: | Kafka Connect and Kafka REST API on MapR: Streaming Just Became a Whole Lot Easier! from our JCG partner Ankur Desai at the Mapr blog. |

What REST proxy are you using? Did MapR build one or is this the one from Confluent?